Elasticsearch的全观测能力
随着企业IT系统拓扑结构日趋复杂,系统架构从单体道分布式再到微服务,部署模式从物理服务器部署到虚拟化再到容器化应用,基础设施上云后开发模式也从传统瀑布式到DevOps开发运维结合。复杂的系统链路中多种数据源背后,是不同的数据类型,以及极高的海量非结构化数据的统一采集、加工、存储和维护成本。在传统SRE运维场景之外,企业业务场景在实时分析、安全审计、用户行为、运营增长、交易记录场景衍生出各类应用,由此带来多套观测方案交织,维护成本大幅提升,同一个业务组件或系统,产生的数据不同方案中数据难互通,无法充分发挥数据价值。
由此,各个企业也越发关注对系统可观测能力的建设,迫切需要把各类数据在统一平台进行存储、监控和检索分析。业内公认,log、metric、trace是全观测的三大支柱,通过搭建统一的观测系统,在运维场景帮助运维人员在「事前」了解系统运行状态,「事中」快速定位故障,「事后」根因分析,以此提升系统高可用,降本增效。但在全观测技术演进过程中,不仅需要跨云、跨业务系统实现日志和时序数据的观测,而日志、时序等各类数据场景支撑的技术原子工具繁多,工具之间的衔接困难,技术组价及平台的维护成本高。
可观测作为Elastic三大核心解决方案之一,基于Elasticsearch全观测能力可以统一收集日志、指标、uptime数据、应用程序跟踪tracing数据,并将各类数据统一存储到 Elasticsearch,进行统一处理分析并基于Kibana 完成可视化。从而可观测场景下实现了技术栈统一,SRE团队也无须基于多种技术组件搭建可观测平台。

在全观测场景下,阿里云Elasticsearch在基于云原生Serverless日志引擎能力,持续优化在海量日志数据的写入性能及存储成本。而在对Metric时序数据的存储和处理过程中,往往会面临以下几个问题:

TimeStream是什么?
TimeStream是阿里云Elasticsearch团队自研,并结合Elastic社区时序类产品特性共建的时序引擎。在云原生ELK全托管基础上,通过TimeStream时序增强功能插件,可实现高性能、低成本时序数据存储和查询分析。
阿里云ES TimeStream的优势
作为与Ali内核深度整合的阿里云ES时序场景核心技术,Timestream大幅优化了阿里云ES时序场景的成本、性能和易用性:
- 数据管理提效:基于Timestream时序数据模型及增删改查,集成Elasticsearch在时序场景的最佳实践模板,大幅降低了Elasticsearch管理时序指标数据的门槛
- 查询体验提升:支持使用PromQL查询Elasticsearch数据,可无缝对接Prometheus+Grafana,支持DownSample采样查询和DataStream时间分区
- 存储成本优化:通过数据压缩优化、元数据存储容量优化,TimeStream索引相比开源Elasticsearch普通索引的存储容量降低了80%以上
- 读写性能提升:TimeStream索引相比开源Elasticsearch普通索引写入TPS提升近40%,对于时序数据的常用查询分析,性能相比开源Elasticsearch提升了5倍
与开源对比
时序场景中Elasticsearch在使用和不使用TimeStream插件情况下,场景化配置、存储、查询对比如下:
对比项 |
使用TimeStream |
不使用TimeStream |
场景化配置 |
TimeStream引擎原生支持时序类型数据模型,自动生成_tsid,indexing sort优化等 |
需要用户进行大量指标场景最佳实践,例如生成一个时间线id字段,使用时间线id和时间配置indexing sorting,使用时间线id做routing等 |
存储 |
|
|
查询语句 |
支持PromQL查询DSL |
专门构建query DSL查询Metric数据 |
降采样 |
简单配置时间间隔,即可支持降采样功能 |
需要用户侧自行进行降采样处理 |
时间分区 |
按照实际数据分区,一个时间范围的数据会分布在确定的索引中 |
按写入的顺序分区,一个时间范围的数据可能分布在很多索引中 |
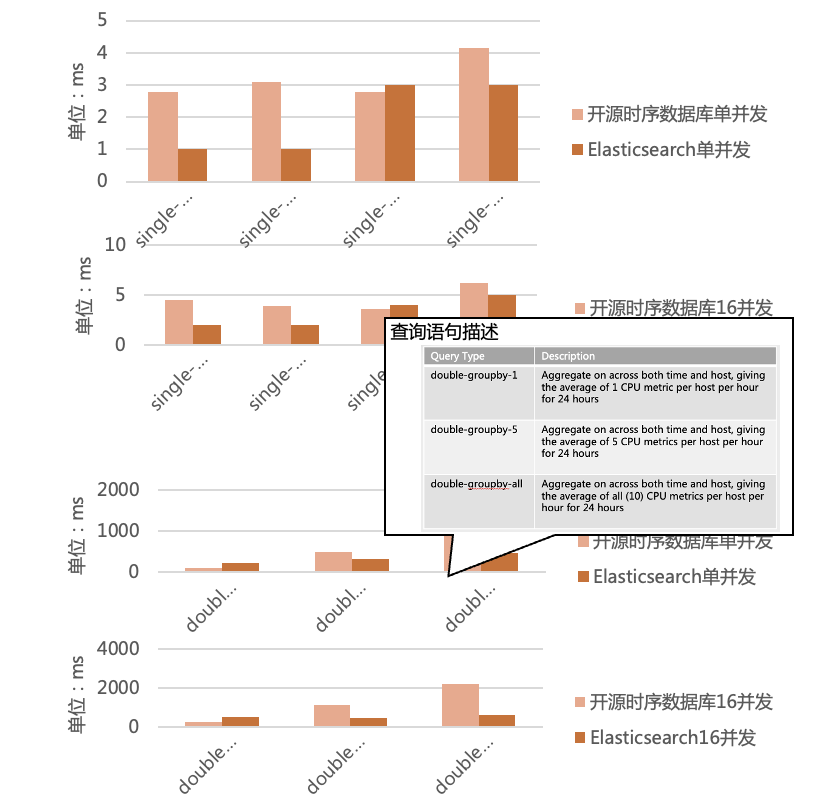
性能对比
从benchmark对比结果看, 阿里云Elasticsearch基于TimeStream实现了Elasticsearch时序读写性能大幅提升,核心性能与传统开源时序类产品处于同一级别
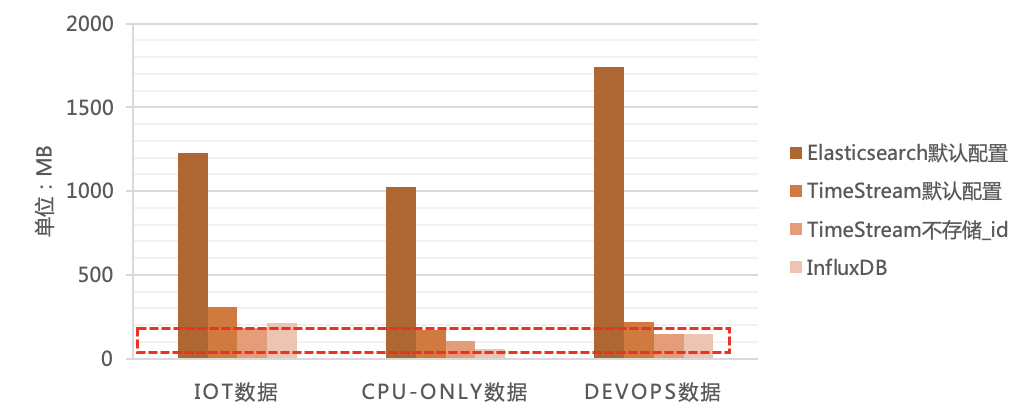
存储容量方面
TimeStream索引相比开源Elasticsearch普通索引存储容量降低超过80%;
TimeStream支持不存储_id,使得与同等条件下存储_id的普通索引相比,存储容量降低超过90%,与开源时序数据库持平;
写入性能方面
TimeStream索引相比开源Elasticsearch普通索引提升写入TPS提升近40%

查询性能方面
单并发简单查询,阿里云ES接近开源时序产品;
单并发复杂查询,阿里云ES TimeStream查询性能表现更优。
多并发,简单和复杂查询语句下,阿里云ES TimeStream 查询性能表现更优
实践案例
案例A:TimeStream管理Elasticsearch时序数据快速入门
STEP1 购买和使用
TimeStream目前支持阿里云ES 7.16版本实例(内核版本1.7.0及以上)

通过系统默认插件列表查看是否已安装Aliyun-TimeStream插件,确认拥有TimeStream最新功能

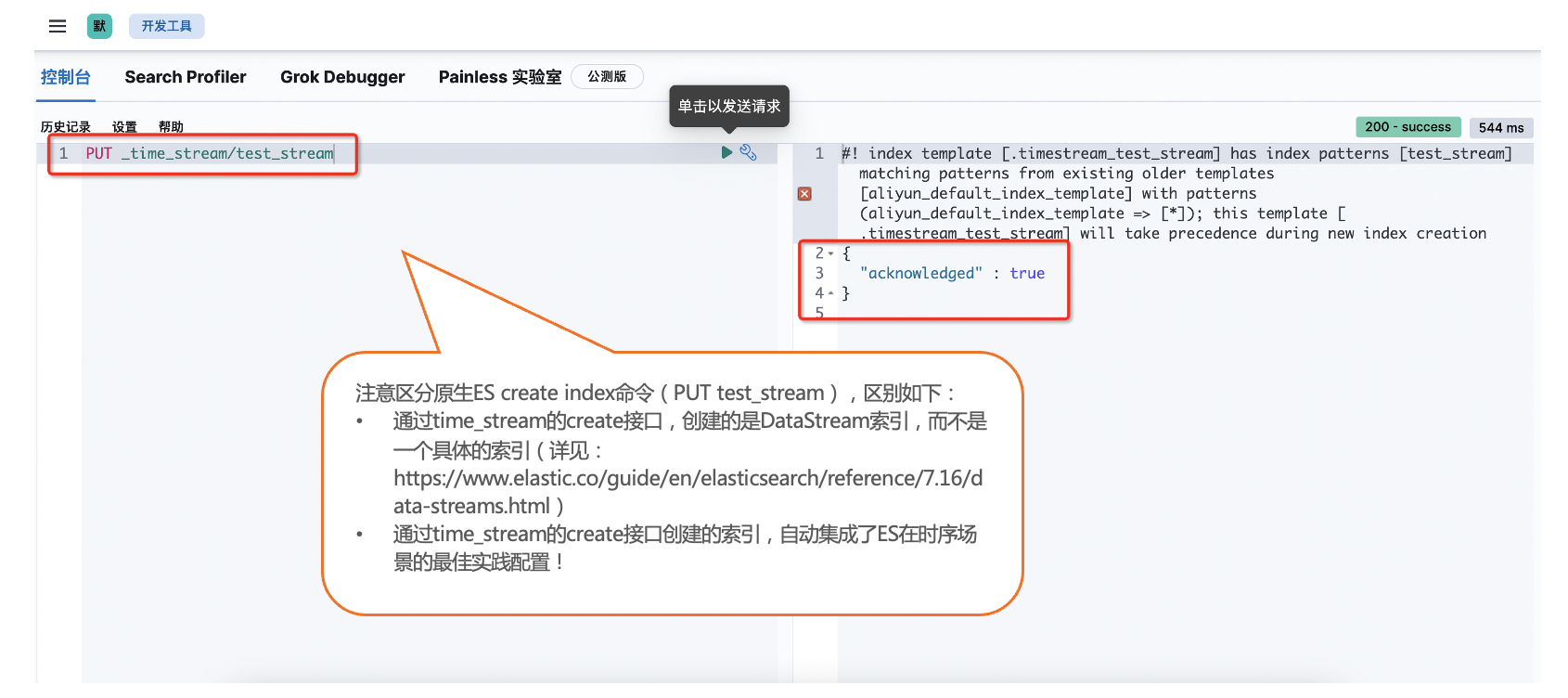
STEP2 创建TimeStream时序数据索引
在Kibana控制台通过time_stream的create接口创建时序数据类型索引,命令及返回结果如下。
STEP3 写入数据
使用bulk、index接口写入数据,写入时需按照时序模型写入(模型字段可修改),命令及返回结果如下。

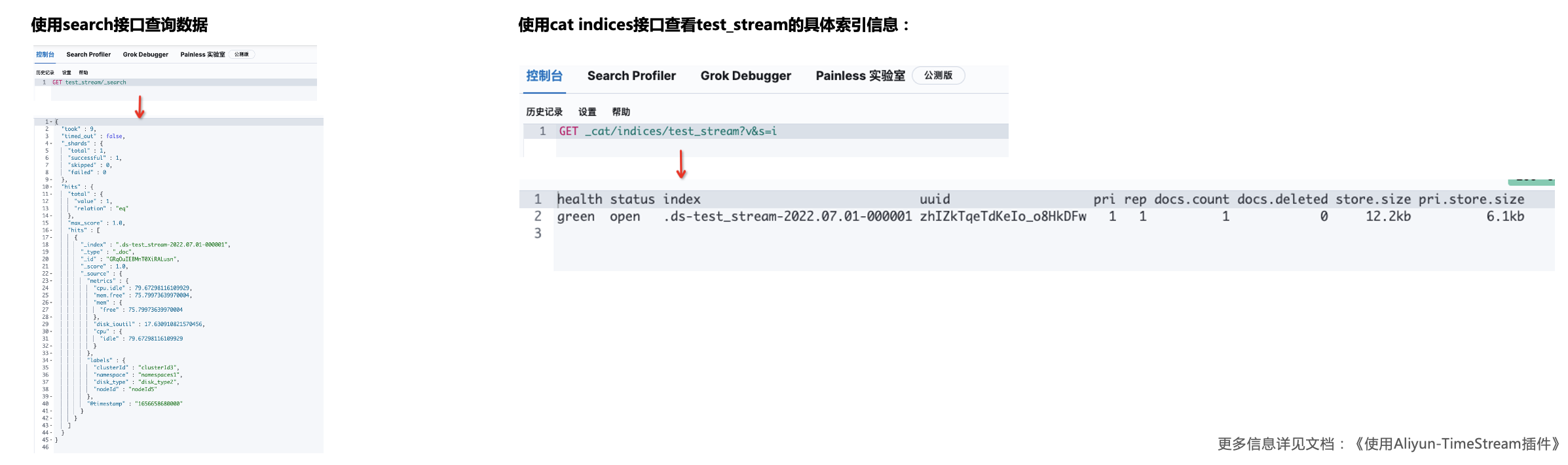
STEP4 查询数据
使用search接口查询数据,以及使用cat indices接口查看test_stream具体索引信息,命令及返回结果如下:
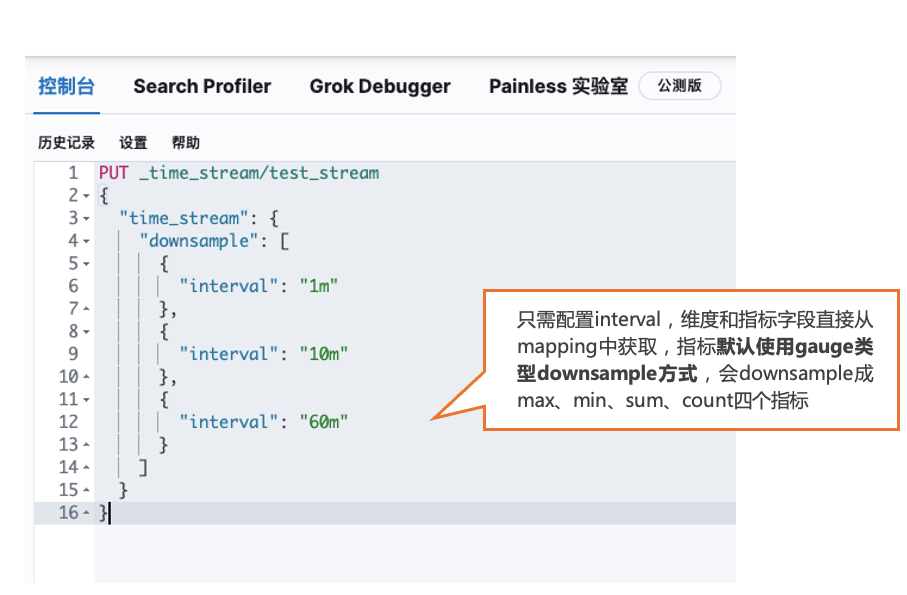
STEP5 使用DownSample功能
通过time_stream的create接口创建时,可直接指定DownSample规则,通过配置interval设定downsample精度,示例如下:
案例B:使用阿里云ES TimeStream对接Prometheus+Grafana实现可观测性
阿里云Elasticsearch支持无缝对接Prometheus+Grafana,支持Prometheus Query相关的API,可以直接将TimeStream索引作为Grafana的Prometheus数据源使用,能够提高时序数据存储与查询分析的性能,同时节约成本。
通过node_expoter收集各种与硬件和内核相关的指标,并提供给Prometheus进行读取,再通过remote write将数据写入阿里云ES TimeStream索引,并通过配置Grafana进行可视化分析。

下图示例在Grafana配置Prometheus数据源,使用PromQL查询作为Prometheus数据源的阿里云ES数据,访问并可视化。

相关文档

联系我们(钉群二维码)
更多可观测场景架构及使用最佳实践交流,欢迎扫描二维码加入钉群>>