问题一:flink默认的这个catalog一般有啥作用?
flink默认的这个catalog一般有啥作用?
参考答案:
在Apache Flink中,catalog(目录)是用于管理和组织表的元数据的服务。默认情况下,Flink提供了几个内置的catalog,包括:
1. GenericInMemoryCatalog:
这是一个简单的、内存中的catalog实现,适用于测试和开发环境。
1. HiveCatalog:
这是一个支持与Hive集成的catalog,允许您使用Hive Metastore来存储和管理Flink表的元数据。
1. JdbcCatalog:
这是一个基于JDBC连接的catalog,可以与各种关系型数据库(如MySQL、PostgreSQL等)集成,以便将表的元数据存储在这些数据库中。
1. CalciteCatalog:
这是一个基于Apache Calcite框架的catalog,它可以处理多种类型的存储后端,并提供对SQL DDL语句的支持。
1. FileSystemCatalog:
这是一个基于文件系统的catalog,它允许您将表的元数据以JSON格式存储在本地文件系统或分布式文件系统(如HDFS)上。
这些catalog的主要作用包括:
组织和管理表:
Catalog可以帮助用户组织和管理其Flink作业中的表。通过catalog,您可以创建、删除、查询和修改表的结构和属性。
持久化元数据:
Catalog通常会将表的元数据持久化到某种形式的存储系统中,这使得即使在Flink作业失败或重启后也能恢复元数据信息。
跨作业共享表:
使用catalog可以让多个Flink作业共享相同的表元数据,从而简化了表的管理和使用。
支持SQL DDL操作:
许多catalog还支持SQL DDL(数据定义语言)操作,例如CREATE TABLE、ALTER TABLE和DROP TABLE等,这使得用户可以更方便地操作表。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/578523
问题二:Flink这个监控在哪看呀?
Flink这个监控在哪看呀? 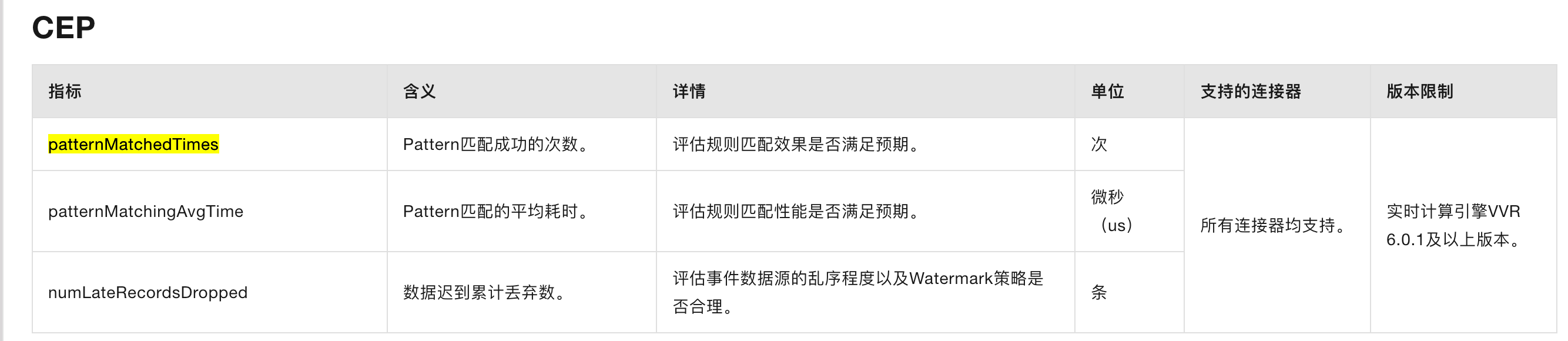
参考答案:
Apache Flink 提供了控制台监控界面来查看作业运行时的各项指标,包括 Checkpoint 监控和反压监控。这些监控信息可以通过访问 Flink 的控制台来查看,在 Flink控制台界面上,您可以找到与 Checkpoint 相关的选项卡或标签页,
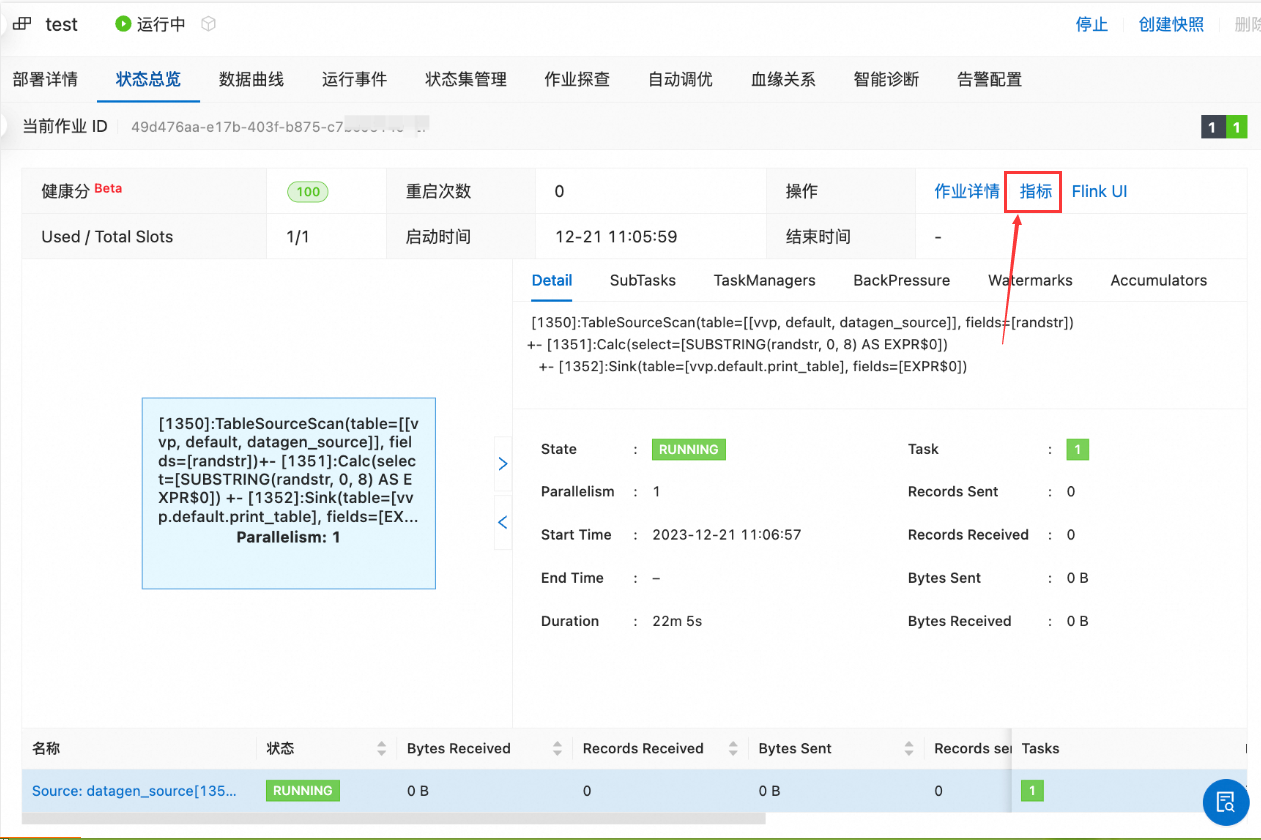
其中会显示作业的 checkpoint 信息,例如 checkpoint 的频率、状态、持续时间以及相关的元数据等。即使作业已经终止,这些统计信息通常仍然可以查看。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/578522
问题三:Flink这种怎么看他们的hash键是哪个?
Flink这种怎么看他们的hash键是哪个? 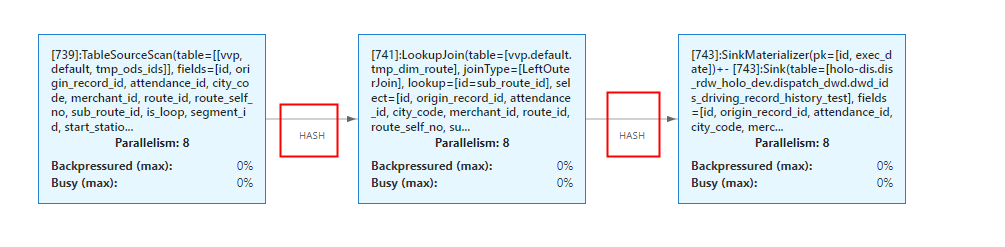
参考答案:
常见的策略就是基于键(key)的分区,例如 keyBy 或者 partitionCustom。在基于键的分区中,Flink 会使用 hash 函数来决定每个数据元素应该发送到哪个并行实例。
可以从代码分析下,比如 join、group by key。 
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/578521
问题四:Flink这个整库多表同步大概是怎么做呢?
Flink这个整库多表同步大概是怎么做呢?我这边一个job处理一个宽表。
一个库一个job表不会太多吗
参考答案:
我是采用flink+hologres方案,holo ods层类似从库方案,没有直接连mysql去打宽,很多需求不一样,同一表可能多处用到,都去连业务库压力还是比较大的,整库同步cads,然后指定多表。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/578519
问题五:我使用flink在做一个100张表左右的数据同步,这种情况下,对于CPU要求的范围大概是多少呢?
我使用flink在做一个100张表左右的数据同步,涉及到的业务不是特别复杂,这种情况下,对于CPU要求的范围大概是多少呢?还有内存,这边想知道一下范围方便采购
参考答案:
可以参考下我的:我现在有50个库在做数据同步, 差不多每个库是90个表, 整库多表同步, 50个库对应50个job, 目前每个job使用的资源差不多0.7CU, JM:0.25+1,TM:0.5+2 。
关于本问题的更多回答可点击进行查看:
