问题一:使用CTAS把mysql表同步数据到hologres,Flink有什么参数可以使字段都小写?
使用CTAS 把mysql 表同步数据 到hologres ,Flink有什么参数可以使hologres 的字段都小写吗?因为mysql 有大写也有小写,比较混乱,我想holo做个统一
参考答案:
这个好像没办法。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583791
问题二:FlinkCDC使用MySQLSource为什么将并行度从1提高,fromSource()这就会卡住
FlinkCDC使用MySQLSource为什么将并行度从1提高,fromSource()这就会卡住
参考答案:
Flink CDC (Change Data Capture) 是一个用于捕获和处理数据库变化的框架。当使用 Flink CDC 连接 MySQL 数据库时,可以通过 MySQLSource 来实现数据的流式处理。
如果在提高并行度时遇到问题,并且 fromSource() 方法变得卡住,这可能是由于多种原因。以下是一些可能的原因和相应的解决方法:
1.资源限制:当并行度增加时,Flink 需要更多的资源来处理数据。如果集群资源不足,可能会导致任务挂起或失败。请检查集群的 CPU、内存和网络资源是否足够。
2.数据库性能:当并行度增加时,更多的并行任务同时从数据库读取数据。如果数据库的性能不足以支持这种负载,可能会导致查询变慢或失败。请检查数据库的性能指标,并确保它能够处理增加的负载。
3.数据倾斜:在分布式计算中,数据倾斜是一个常见问题,其中某些任务处理的数据量远大于其他任务。这可能导致某些任务长时间运行,而其他任务已经完成。请检查 Flink 的 Web UI,查看任务的执行情况,并确保没有数据倾斜问题。
4.版本兼容性:确保 Flink CDC 的版本与 Flink 的版本兼容,并且与 MySQL 的版本兼容。有时,库的更新可能引入不兼容的更改或问题。
5.日志和错误信息:查看 Flink 的日志和错误信息,这可能会提供有关问题的更多详细信息。根据日志中的错误或警告信息,可以进一步调查问题的根源。
6.配置调整:调整 Flink 和 MySQLSource 的配置参数,例如并行度、超时时间、缓冲区大小等,以更好地适应您的环境和需求。
7.社区支持:如果上述方法都不能解决问题,建议在 Flink 的社区论坛或邮件列表中寻求帮助。可能有其他用户遇到了类似的问题,并且已经找到了解决方案。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583641
问题三:Flink cdc oracle 同步 Oracle 数据库,程序启动后无反应
已解决
Flink cdc oracle 2.11
Flink 1.13.6
``` SourceFunction sourceFunction = OracleSource.builder()
.hostname("xx.x.xx.x")
.port(1531)
.database("TEST") // monitor XE database
.schemaList("APPS") // monitor inventory schema
.tableList("APPS.student") // monitor products table
.username("apps")
.password("apps")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.startupOptions(StartupOptions.latest())
.debeziumProperties(properties)
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(3000); // set the source parallelism to 4 env .addSource(sourceFunction) .print().setParallelism(1); // use parallelism 1 for sink to keep message ordering env.execute("Print Oracle Snapshot + RedoLog");
```
本地测试idea启动后,下图

不知道是什么原因?
参考答案:
如果你的Flink CDC Oracle程序启动后无反应,以下是一些可能的排查步骤:
1. 检查Oracle数据库连接:确保提供的hostname、port、database、username和password是正确的,并且可以从运行Flink作业的环境访问到Oracle数据库。
1. 检查Debezium连接器配置:确认你的DebeziumProperties配置是否正确,包括数据库的历史数据捕获选项(如snapshot.mode)和其他必要的连接器属性。
1. 检查网络连接和防火墙设置:确保运行Flink作业的环境和Oracle数据库之间的网络连接是畅通的,没有被防火墙阻止。
1. 查看Flink日志:检查Flink作业的日志文件,看看是否有任何错误或警告信息。这可能会提供一些关于问题的线索。
1. 测试Debezium连接器:尝试使用Debezium提供的示例代码或者独立的Debezium工具(如Kafka Connect)来测试Oracle连接器,以确认连接器本身是否能够正常工作。
1. 调整Flink作业配置:尝试调整Flink作业的并行度、checkpoint间隔等参数,看看是否会影响到CDC数据的获取。
1. 确认Oracle数据库的日志模式和CDC设置:确保你要监控的Oracle数据库启用了适当的日志模式(如ARCHIVELOG模式),并且已经为CDC配置了必要的触发器和补丁。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583276
问题四:请问Flink这个AI 说的 每个key状态 和每个并行度的状态 怎么测试区分?
请问Flink这个AI 说的 每个key状态 和每个并行度的状态 怎么测试区分? 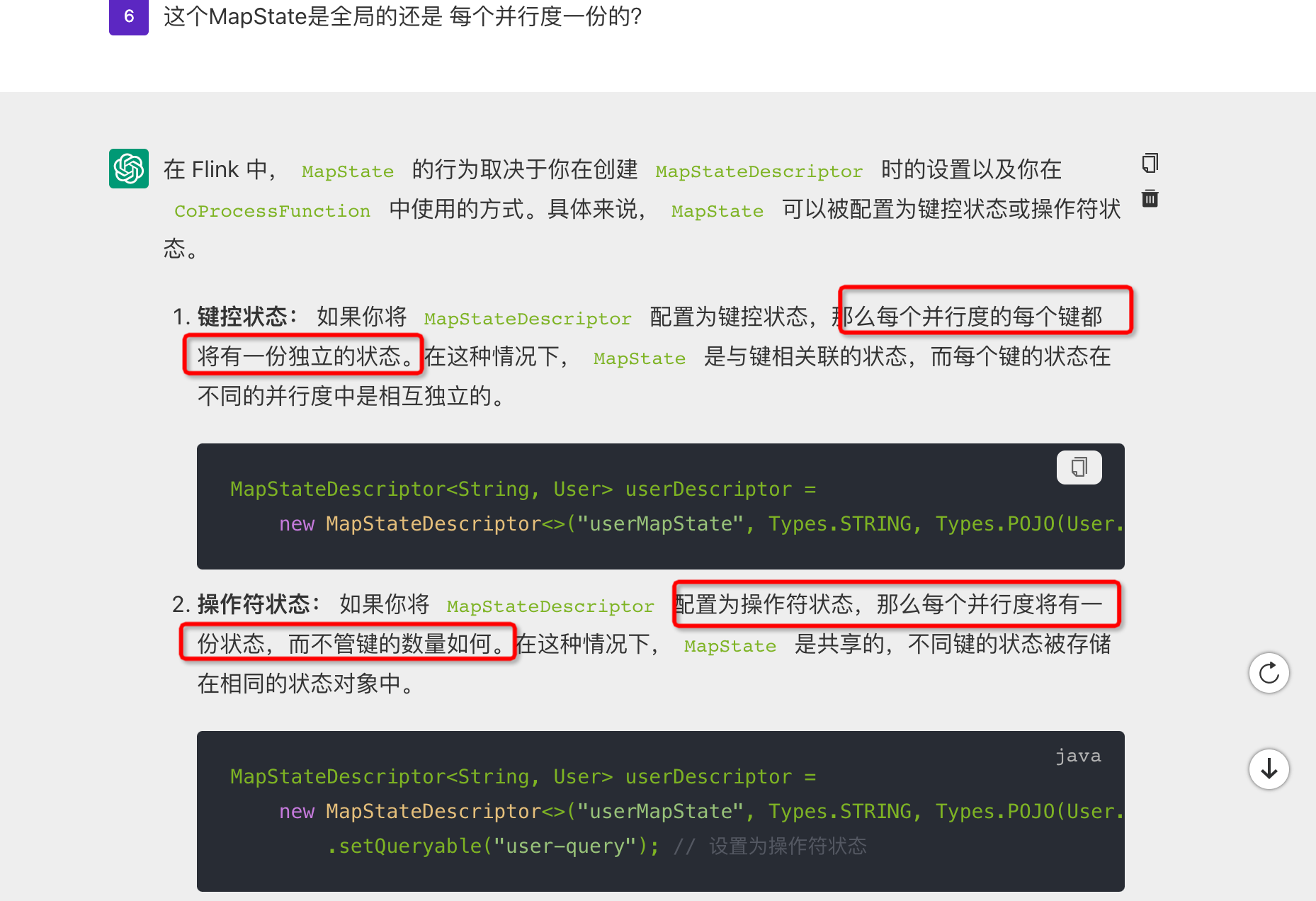
参考答案:
楼主你好,在阿里云Flink中,"每个key状态"指的是针对每个不同的key所维护的状态,而"每个并行度的状态"指的是每个算子实例所维护的状态。
- 数据源:创建一个带有不同key的数据源。比如生成一串包含不同用户ID的事件数据流。
- 算子操作:在Flink任务中使用
keyBy函数对数据流进行分区,以key作为分区参数。然后使用具有状态的算子(比如sum或reduce)对数据进行处理,以便维护每个key的状态。 - 打印状态:使用
print或printToErr函数在流中的某个位置打印状态信息。比如在sum算子之后,使用stream.print()或stream.printToErr()函数打印输出。 - 并行度调整:通过更改任务的并行度,例如将并行度设置为2或4,进行多次测试。比如可以使用
StreamExecutionEnvironment的setParallelism方法来设置并行度。
观察打印的状态信息,可以分别看到每个key的状态和每个并行度的状态,每个key的状态应该是独立维护的,而每个并行度的状态应该是在所有key上进行维护的。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/582471
问题五:Flink应该如何保存savepoint呢?我写的保存语句如下。也不对,是吗?
Flink应该如何保存savepoint呢?我写的保存语句如下。也不对,是吗?
bin/flink stop \
--savepointPath /tmp/savepoints \
d69301ce5772186fb26aa193640ca46f \
--target kubernetes-application \
-Dkubernetes.cluster-id=toll-pro-aa \
-Dkubernetes.namespace=flink \
-Dakka.client.timeout=300s
参考答案:
我用flink独立模式读取本地是可以的,容器没用过,所以建议你用文件系统存储检查点和保存点
关于本问题的更多回答可点击进行查看:
