问题一:flinkCDC一直没有数据同步过来,也没报错什么情况?
flinkCDC同步Oracle 11g 的一张测试表到doris,一直没有数据同步过来,也没报错什么情况? 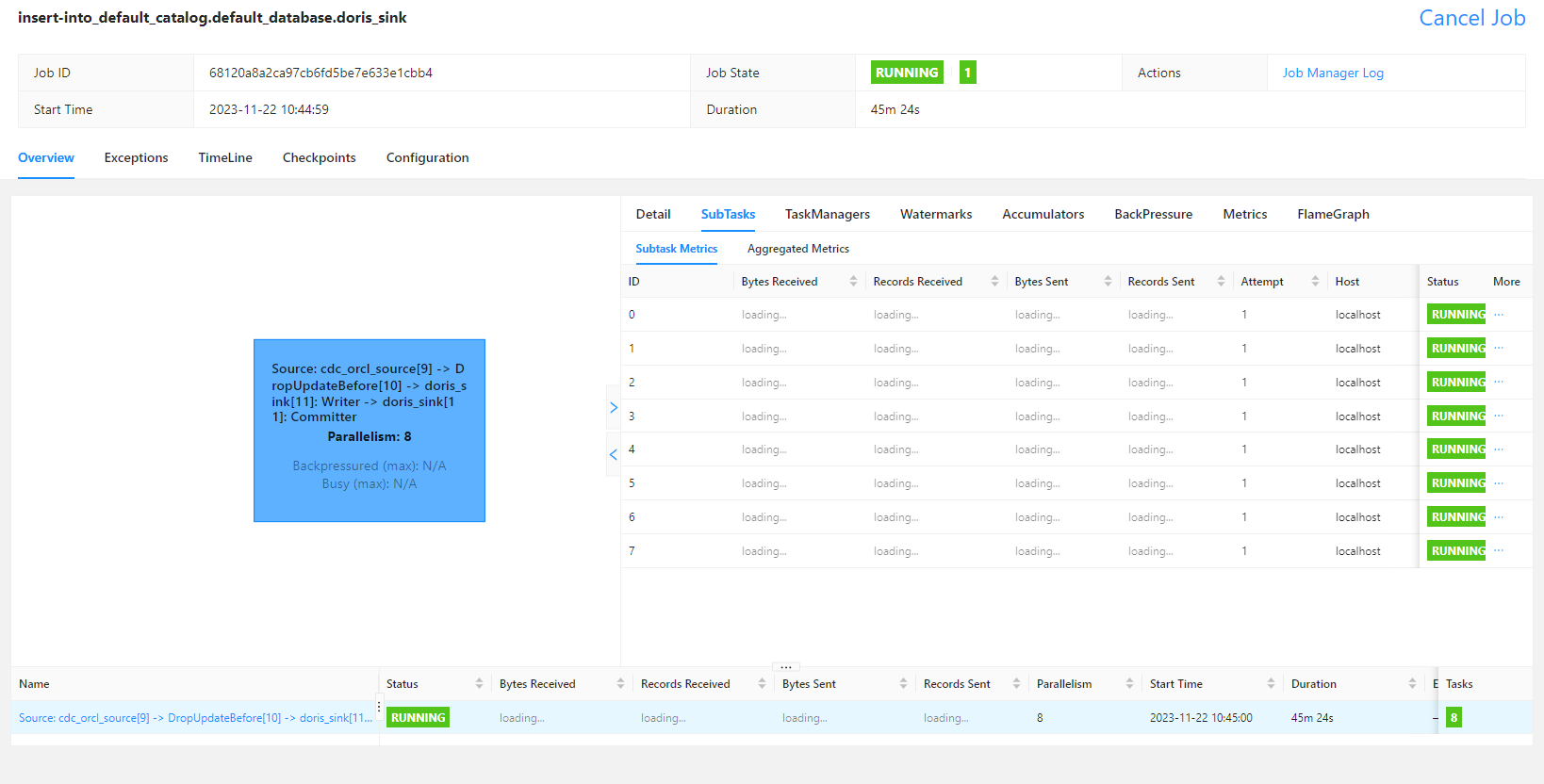
参考回答:
这种情况可能是由于以下原因导致的:
- Oracle数据库中的表没有发生变化,因此Flink CDC没有捕获到任何数据。请确保在Oracle数据库中对测试表进行了一些更改,以便Flink CDC能够检测到变化并同步数据。
- Flink CDC配置不正确。请检查您的Flink CDC配置,确保您已正确设置源端点、目标端点和同步模式。例如,您需要确保已正确设置Oracle的JDBC连接信息、Doris的目标端点等。
- Flink作业可能存在问题。请检查您的Flink作业逻辑,确保它能够正确地处理从Oracle读取的数据并将其写入Doris。您可以查看Flink作业的日志以获取更多关于错误的详细信息。
- Doris集群可能存在问题。请检查Doris集群的状态,确保它正常运行并且可以接受来自Flink的数据。您可以尝试手动将一些数据插入Doris,以检查其是否正常工作。
- 网络问题。请检查Flink作业与Oracle和Doris之间的网络连接,确保它们之间可以正常通信。如果可能的话,尝试在同一网络环境下运行Flink作业,以排除网络问题的可能性。
要解决这个问题,您可以尝试以下方法:
- 在Oracle数据库中对测试表进行一些更改,以便Flink CDC能够检测到变化并同步数据。
- 仔细检查您的Flink CDC配置,确保所有必要的设置都已正确完成。
- 查看Flink作业的日志以获取更多关于错误的详细信息,并根据日志中的信息调整您的Flink作业逻辑。
- 检查Doris集群的状态,确保它正常运行并且可以接受来自Flink的数据。如果需要,您可以尝试重启Doris集群或调整其配置。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574212
问题二:Flink CDC中mysql和sqlserver放在一起跑之后,flink集群报了上面这个错误?
Flink CDC中mysql和sqlserver放在一起跑之后,flink集群报了上面这个错误?
参考回答:
这个错误可能是由于Flink CDC在处理MySQL和SQL Server之间的数据同步时遇到了问题。为了解决这个问题,你可以尝试以下方法:
- 确保你的Flink集群有足够的资源来处理这两个数据库之间的数据同步。如果资源不足,可以考虑增加集群的节点数量或提高每个节点的资源配置。
- 检查你的Flink CDC配置,确保所有必要的设置都已正确完成。特别是关于源端点(MySQL)和目标端点(SQL Server)的配置,确保它们之间的连接信息、用户名、密码等都是正确的。
- 查看Flink作业的日志以获取更多关于错误的详细信息。根据日志中的信息,你可以找到导致问题的确切原因,并采取相应的措施来解决它。
- 如果可能的话,尝试在一个独立的Flink集群上运行Flink CDC,以便更好地隔离问题。这样可以帮助你更容易地识别和解决问题。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574210
问题三:Flink CDC这是因为jobmanager的内存不足了吗?
Flink CDC这是因为jobmanager的内存不足了吗?Caused by: java.util.concurrent.ExecutionException: org.apache.flink.runtime.rest.util.RestClientException: [Internal server error: Metaspace. The metaspace out-of-memory error has occurred. This can mean two things: either Flink Master requires a larger size of JVM metaspace to load classes or there is a class loading leak. In the first case 'jobmanager.memory.jvm-metaspace.size' configuration option should be increased. If the error persists (usually in cluster after several job (re-)submissions) then there is probably a class loading leak in user code or some of its dependencies which has to be investigated and fixed. The Flink Master has to be shutdown...
参考回答:
这个错误可能是由于JobManager的内存不足导致的。原因可能是Flink Master需要更大的JVM元空间来加载类,或者存在类加载泄漏。在第一种情况下,应该增加'jobmanager.memory.jvm-metaspace.size'配置选项。如果错误仍然存在(通常在集群中提交了几个作业后),那么可能存在用户代码或其依赖项中的类加载泄漏,需要调查并修复
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574209
问题四:Flink CDC这种报错又是因为啥?
Flink CDC这种报错又是因为啥?Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received unexpected exception while polling the records
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:165) ~[flink-connector-files-1.17.1.jar:1.17.1]
at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:114) ~[flink-connector-files-1.17.1.jar:1.17.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) ~[?:?]
at java.util.concurrent.FutureTask.run(Unknown Source) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) ~[?:?]
... 1 more
Caused by: io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot.
at io.debezium.relational.HistorizedRelationalDatabaseSchema.recover(HistorizedRelationalDatabaseSchema.java:59) ~[flink-sql-connector-mysql-cdc-2.4.2.jar:2.4.2]
at io.debezium.schema.HistorizedDatabaseSchema.recover(HistorizedDatabaseSchema.java:38) ~[flink-sql-connector-mysql-cdc-2.4.2.jar:2.4.2]
参考回答:
这个报错是由于Flink CDC在同步过程中遇到了问题。具体来说,是因为Debezium在尝试恢复数据库历史记录时遇到了问题。错误信息中提到了数据库历史主题或其内容完全或部分缺失,需要检查数据库历史主题的配置并重新执行快照。
要解决这个问题,你可以尝试以下方法:
- 检查数据库历史主题的配置,确保它指向正确的Kafka主题。
- 确保Kafka集群正常运行,没有出现故障或分区丢失的情况。
- 如果问题仍然存在,可以尝试升级Flink CDC和Debezium的版本,看看是否能解决问题。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574207
问题五:Flink CDC这里是我忽略了什么配置么?
Flink CDC这里是我忽略了什么配置么?mongo-cdc 2.4 flink1.17.1 同步的时候出现 Caused by: org.bson.BsonInvalidOperationException: Document does not contain key $clusterTime,请问有人遇到过这问题么? 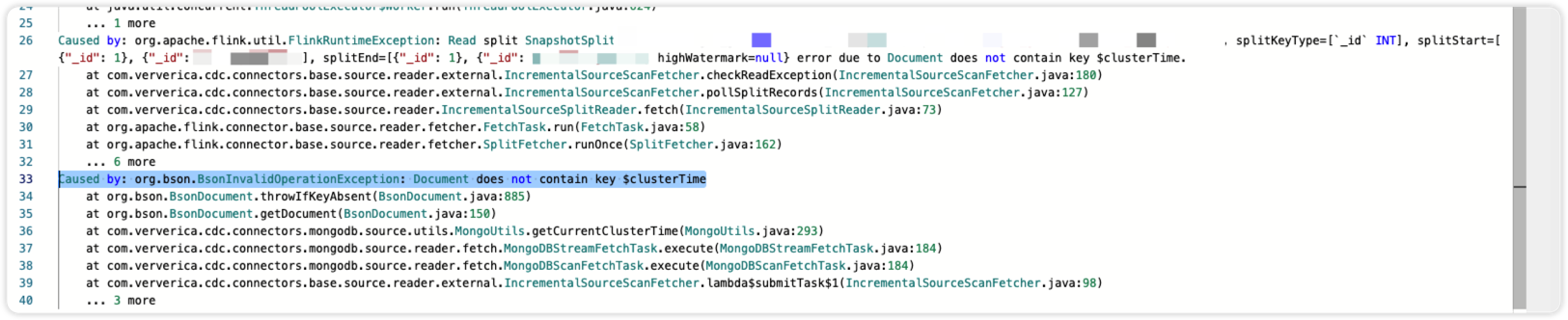
MongoDB server version: 4.4.2-4
参考回答:
这个问题可能是由于您的Flink CDC配置中缺少了mongo-cdc.start.at参数导致的。这个参数用于指定从哪个时间点开始读取数据,如果不设置该参数,则默认为null,这可能会导致同步过程中出现BsonInvalidOperationException异常。
您可以尝试在Flink CDC的配置文件中添加以下参数:
mongo-cdc.start.at=<时间戳>
其中,<时间戳>表示您希望从哪个时间点开始读取数据。例如,如果您希望从2023年1月1日开始读取数据,可以将其设置为:
mongo-cdc.start.at=1672444800000
请注意,时间戳的单位是毫秒。
关于本问题的更多回答可点击原文查看:

