问题一:机器学习PAI遇到个问题需要帮忙解答,运行过程中遇到如下错误?
机器学习PAI遇到个问题需要帮忙解答,我的配置文件设置了early_stop,模型是mmoe,在各个tower中设置评估指标为auc和gauc,但是运行过程中遇到如下错误: 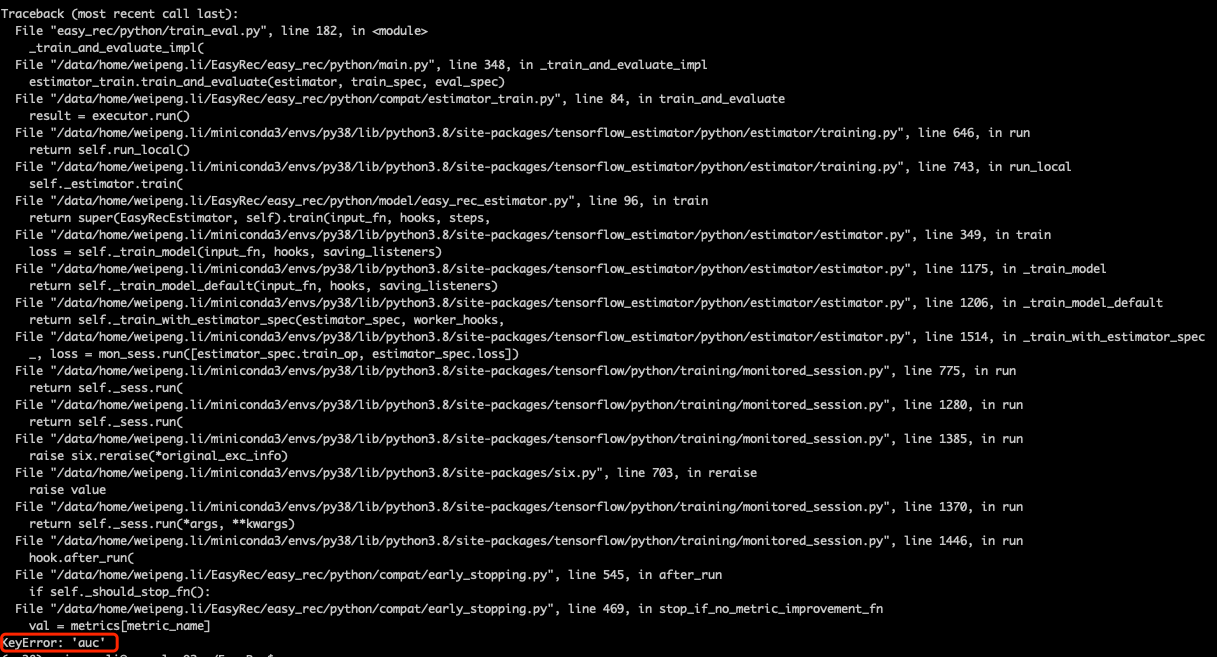
补充一下,eval_results对应的是:
{
1000: {
"auc_ctr_tower": 1.0,
"auc_cvr_tower": 1.0,
"gauc_ctr_tower": 1.0,
"gauc_cvr_tower": 1.0,
"loss": 0.005554337985813618,
"loss/loss/cross_entropy_loss_ctr_tower": 0.0026337471790611744,
"loss/loss/cross_entropy_loss_cvr_tower": 0.0029205905739217997,
"loss/loss/total_loss": 0.005554337985813618
}
}
参考答案:
https://easyrec.readthedocs.io/en/latest/export.html
设置一下这个参数:best_exporter_metric: "auc_ctr_tower" 试一下看看
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/576999
问题二:在机器学习PAI MetaPath游走 demo报这个错误是为啥?
MetaPath游走 demo报这个错误是为啥?Caused by: java.util.NoSuchElementException: null
at java.util.Collections$EmptyIterator.next(Collections.java:4191)
at com.alibaba.alink.operator.batch.graph.MetaPathWalkBatchOp$ConcatDstNodeType.coGroup(MetaPathWalkBatchOp.java:577)
at org.apache.flink.runtime.operators.CoGroupDriver.run(CoGroupDriver.java:177)
at org.apache.flink.runtime.operators.BatchTask.run(BatchTask.java:514)
at org.apache.flink.runtime.operators.BatchTask.invoke(BatchTask.java:357)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:776)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563)
at java.lang.Thread.run(Thread.java:750)
参考答案:
这个错误是由于在MetaPath游走过程中,遇到了一个空的迭代器。具体来说,是在com.alibaba.alink.operator.batch.graph.MetaPathWalkBatchOp$ConcatDstNodeType.coGroup方法中,当尝试从CoGroupDriver.run方法返回的结果中获取下一个元素时,抛出了java.util.NoSuchElementException: null异常。
为了解决这个问题,你需要检查你的代码,确保在调用next()方法之前,迭代器中确实有元素。你可以在调用next()方法之前添加一个条件判断,例如:
if (iterator.hasNext()) { Object nextElement = iterator.next(); // 处理nextElement的逻辑 } else { // 处理没有更多元素的情况 }
这样可以避免在迭代器为空时调用next()方法,从而避免抛出NoSuchElementException异常。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/575700
问题三:机器学习PAI缺失值补充报错 读取数据正常 走到下一步补充缺失值就报这个错误?
从odps读取数据正常 走到下一步补充缺失值就报这个错误?只有belong_date ltv ecpm ipu四个字段 这里有sql关键字?
参考答案:
https://help.aliyun.com/search/?spm=a2c4g.11186623.J_XmGx2FZCDAeIy2ZCWL7sW.i0.756849ecNXzsuJ&k=ODPS-0130161&scene=helpdoc&product-id=30347&product-level=3&page=1 这个错误码搜了一下,看起来是你的字段名存在MC SQL的关键字
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/574300
问题四:机器学习PAI这个地方总是报错,是什么原因?时报错时不报错
机器学习PAI这个地方总是报错,是什么原因?时报错时不报错
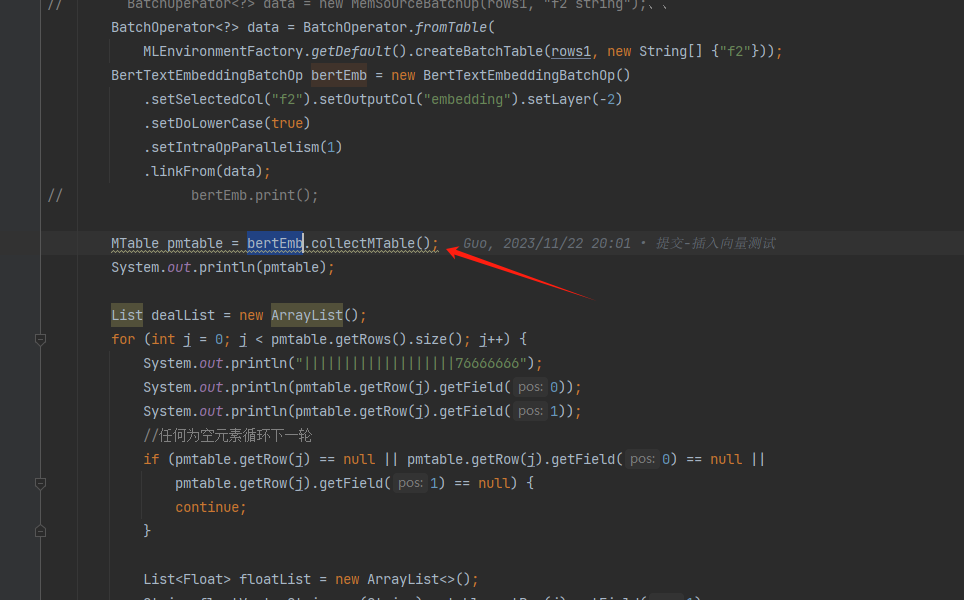
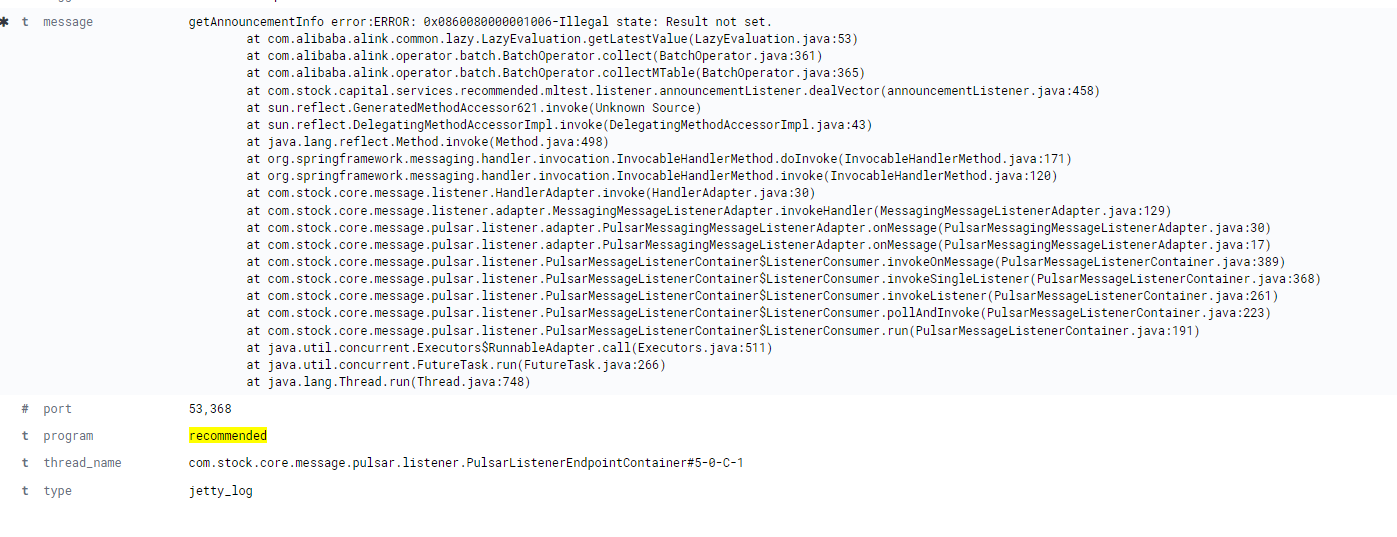
参考答案:
无法确定具体的错误原因。但是,我可以给您一些建议来帮助您解决问题:
- 检查您的网络连接是否正常,确保您的计算机可以访问PAI的端口(53,368)。
- 检查您的防火墙设置,确保它允许您的计算机访问PAI的端口。
- 查看PAI的日志文件(jetty_log),以获取更多关于错误的详细信息。您可以在PAI的安装目录下找到日志文件。
- 确保您的程序和依赖项都是最新的,以避免因版本不兼容导致的错误。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/574196
问题五:机器学习PAI这个数据集现在下载不下来,还有其它方式可以下载吗?
机器学习PAI这个数据集现在下载不下来,还有其它方式可以下载吗? 
想拿下这个数据集跑下效果
这个没有完整的数据集吗?
参考答案:
没有,数据是上面那个 
关于本问题的更多回答可点击进行查看:
