
问题一:flink CDC3.0 同步mysql binlog,mysql表没有分区怎么同步?
flink CDC3.0 同步mysql binlog,mysql表没有分区,doris表中有分区。怎么同步呢?比如 mysql中有个create_time 是yyyy-MM-dd hh:mm:ss,但是doris 分区字段是 dt 分区格式是:yyyy-MM-dd。这样怎么同步呢?
参考回答:
问题一:对于MySQL表没有分区,而Doris表中有分区的情况,可以通过以下步骤进行同步:
1. 在Flink CDC中配置MySQL的binlog解析和数据转换规则。可以使用Flink SQL或者Java API来实现。
1. 在Flink CDC的数据流中添加一个自定义的函数或UDF(User-Defined Function),用于将MySQL中的create_time字段转换为Doris表中的dt字段格式。可以使用Flink内置的时间函数或者自定义的函数实现。
1. 在Flink CDC的数据流中添加一个分区键生成器,根据Doris表的分区字段dt来生成分区键。可以使用Flink内置的分区键生成器或者自定义的分区键生成逻辑实现。
1. 将Flink CDC的数据流写入到Doris表中,并指定分区键为dt字段。
问题二:如果同步任务未同步MySQL某张表,但该表结构发生了变更,可能会导致Flink CDC同步任务报错。为了避免这种情况,可以采取以下措施:
1. 在Flink CDC的配置中设置自动检测表结构变更的功能。这样,当MySQL表结构发生变更时,Flink CDC会自动更新同步任务的配置,以适应新的表结构。
1. 定期检查MySQL表的结构变化,并在必要时手动更新Flink CDC同步任务的配置。这可以通过编写脚本或使用其他工具来实现。
1. 在Flink CDC同步任务中添加错误处理机制,以便在遇到表结构变更导致的错误时能够自动恢复或跳过有问题的数据记录。这可以通过使用Flink的异常处理机制或者自定义的错误处理逻辑来实现。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/594838?spm=a2c6h.13066369.question.81.283f3f33bN1ttc
问题二:Flink CDC里flinksql连接kudu数据库这种错误是少了啥jar包吗?
Flink CDC里flinksql连接kudu数据库这种错误是少了啥jar包吗? 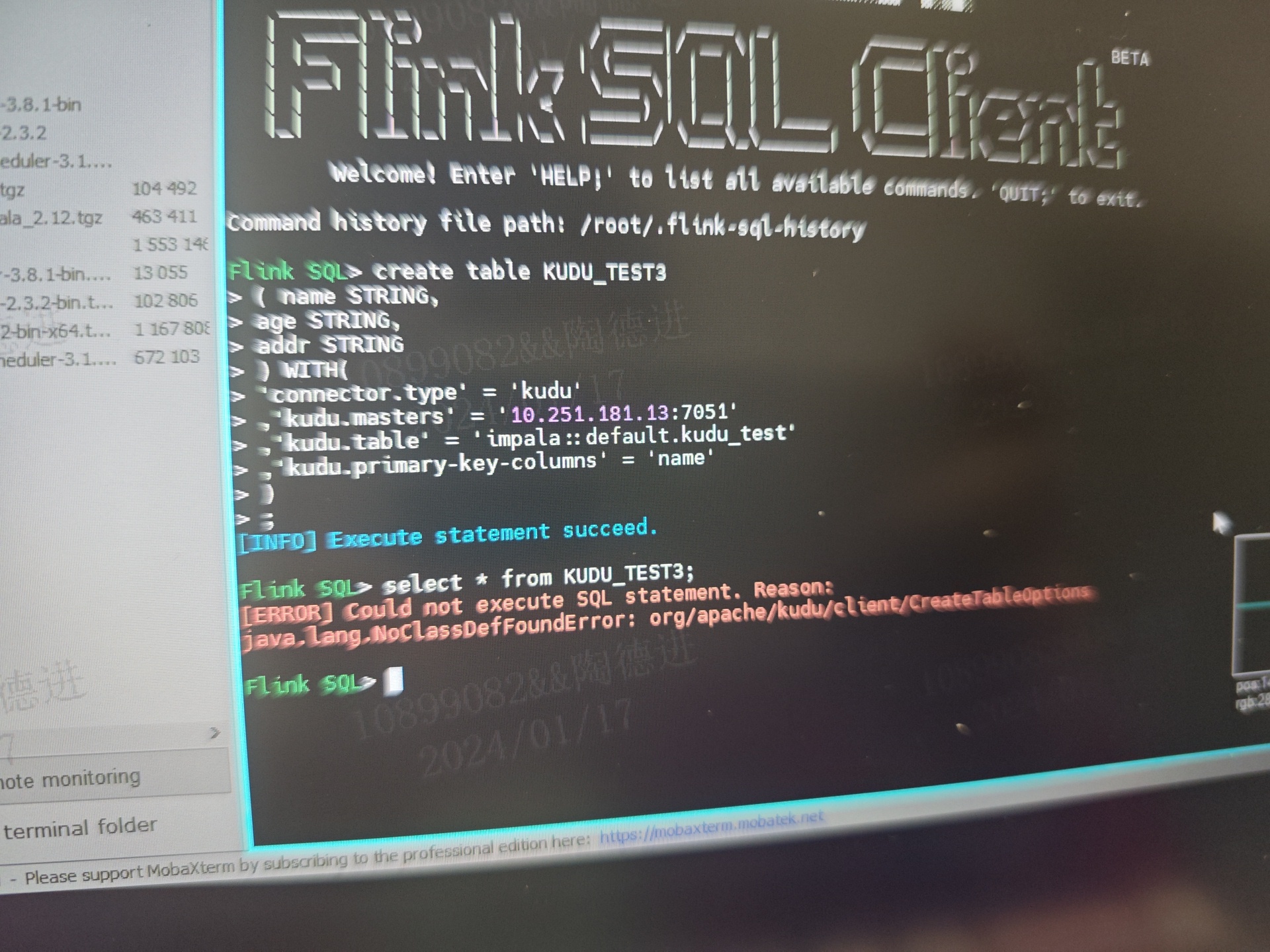
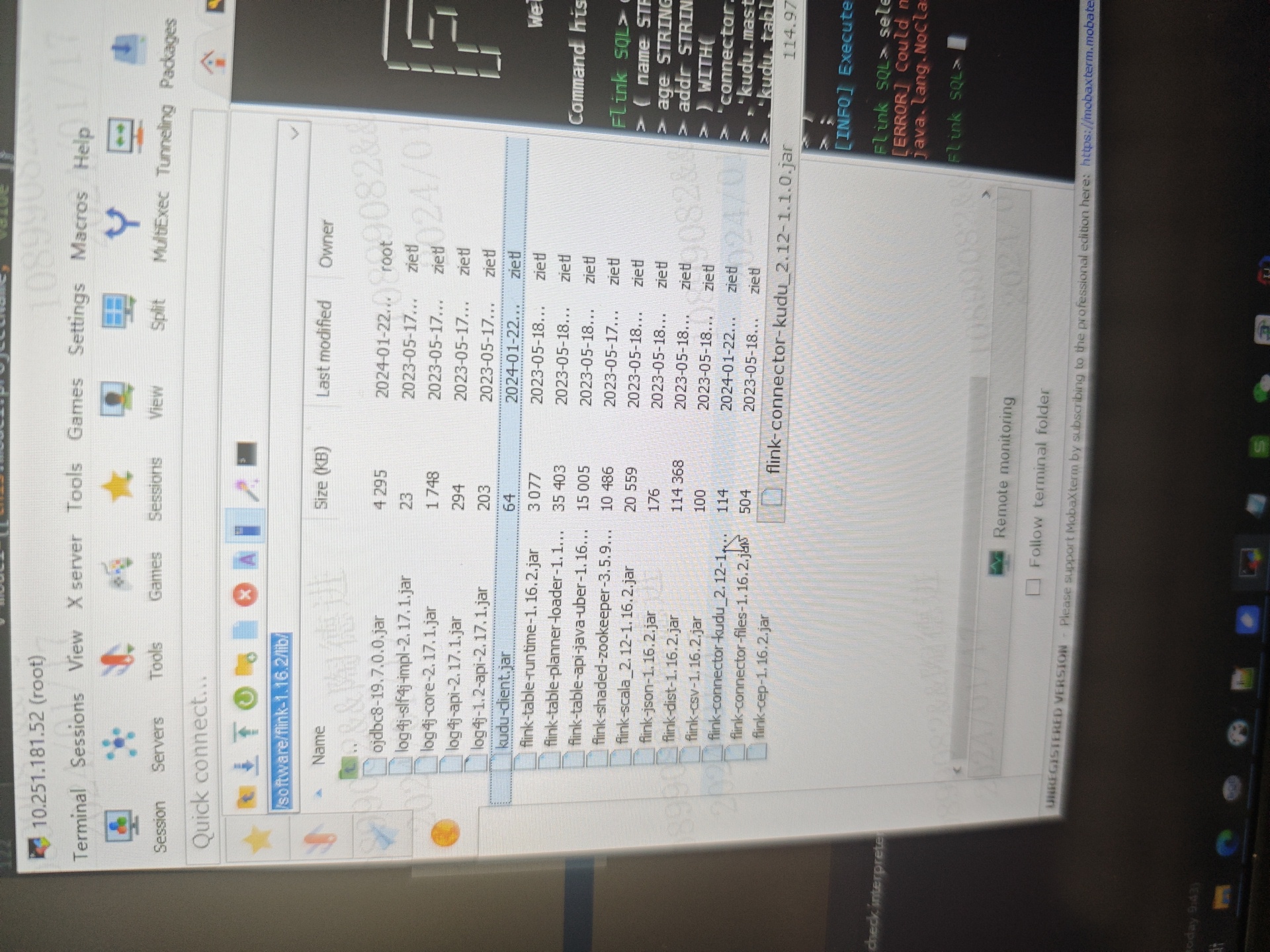
参考回答:
根据您提供的信息,出现"Flink CDC里flinksql连接kudu数据库这种错误"可能是由于缺少了相应的jar包导致的。具体来说,错误信息中提到的"java.lang.NoClassDefFoundError: org/apache/juli/Main"表明缺少了juli相关的jar包。
要解决这个问题,您可以尝试以下步骤:
1. 确保您的项目中包含了正确的依赖项。根据您的查询语句和错误信息,您可能需要将juli相关的jar包添加到您的项目中。您可以从Apache官方网站或其他可靠的资源下载并添加相应的jar包。
1. 检查您的类路径设置。确保您的项目能够正确加载所需的jar包。您可以检查类路径设置,确保包含了juli相关的jar包所在的路径。
1. 如果您使用的是构建工具(如Maven或Gradle),请确保在构建配置文件中正确配置了依赖项。您可以在配置文件中添加juli相关的依赖项,并重新构建您的项目以获取所需的jar包。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/594825?spm=a2c6h.13066369.question.82.283f3f33d7mLcu
问题三:Flink CDC里datastream flinkcdc tidb的多表数据同步怎么配置?
Flink CDC里datastream flinkcdc tidb的多表数据同步怎么配置?
参考回答:
Flink CDC 支持多表数据同步,但关于整库同步能力的信息尚不明确。
首先,Flink CDC 是一个基于数据库日志 CDC(Change Data Capture)技术的实时数据集成框架,它具备全增量一体化、无锁读取、并行读取、表结构变更自动同步等高级特性。这些特性使得 Flink CDC 能够有效地实现多表数据的同步。具体到 TiDB 的数据同步,可以通过以下两种方式进行配置:
DataStream 模式:在 DataStream 模式下,可以使用 TableFunction 将多个表的数据流合并为一个数据流,然后使用 DataStreamSink 将数据流写入目标表。
Flink SQL 模式:在 Flink SQL 模式下,可以使用 INSERT INTO 语句将多个表的数据插入到一个目标表中。
其次,至于 Flink CDC 是否支持 TiDB-HUDI 的整库同步,目前没有明确的信息表明 Flink CDC 直接支持整库同步。但是,Flink CDC 社区正在努力降低 CDC 数据入湖入仓的门槛,并解决整库同步、表结构变更同步等痛点。因此,如果您需要实现整库同步,建议关注 Flink CDC 的最新动态和版本更新,以获取更详细的信息和可能的解决方案。
综上所述,Flink CDC 提供了灵活的数据同步配置方式,适用于多表数据同步的场景。对于整库同步的需求,可能需要进一步探索和社区的支持。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/594823?spm=a2c6h.13066369.question.83.283f3f33a4yUuz
问题四:Flink CDC里启动任务之后,为什么莫名出现重复?
Flink CDC里启动任务之后,checkpoint 的 checkpointed data size很小,并且生成时间极长(超过半个小时)的情况吗?似乎没有正常完成checkpoint,很容易失败,导致整个任务挂掉。但是日志没有报错,只有一段比较奇怪的重复,像是一直在重试读取一样的mysql binlog片段,flink 版本1.7.0, cdc 版本 3.0.0,这该怎么解决?
参考回答:
根据您描述的情况,Flink CDC 任务在执行 checkpoint 时出现了数据量小且耗时长的问题,同时任务容易失败并出现重复读取 MySQL binlog 的现象。这可能是由于一些配置或环境问题导致的。以下是一些建议来解决这个问题:
检查资源配置:确保 Flink 集群的配置足够支持 checkpoint 操作。如果资源不足,checkpoint 过程可能会变得缓慢或失败。特别关注 TaskManager 的资源使用情况,如 CPU、内存和磁盘空间。
调整 checkpoint 间隔:尝试增加 checkpoint 的间隔时间,以减少对系统资源的占用。可以在 Flink 配置文件中设置 execution.checkpointing.interval 参数来调整间隔时间。
优化并行度:根据您的数据量和处理需求,适当调整任务的并行度。过高的并行度可能导致 checkpoint 竞争和性能下降。
检查网络连接:确保 Flink 集群与 MySQL 数据库之间的网络连接稳定。不稳定的网络可能导致 checkpoint 过程中的数据丢失或同步失败。
查看日志文件:仔细查看 JobManager 和 TaskManager 的日志文件,以获取更多关于问题的详细信息。尽管没有明显的错误消息,但可能会有其他有用的调试信息。
升级版本:考虑升级 Flink 和 CDC 的版本。新版本可能修复了与 checkpoint 相关的问题,并提供了更好的性能和稳定性。
寻求社区支持:如果问题仍然存在,建议向 Flink CDC 社区寻求帮助。在社区论坛或邮件列表中提问,提供详细的配置信息、日志片段和问题描述,以便社区成员能够更好地帮助您解决问题。
请注意,这些建议是基于一般情况提出的,并不能保证解决所有可能的问题。具体的解决方法可能需要根据实际情况进行调整。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/594821?spm=a2c6h.13066369.question.84.283f3f33SXB0XL
问题五:Flink CDC里这儿没有flink1.18的jdbc版本包,请问可以从哪儿找到?
Flink CDC里这儿没有flink1.18的jdbc版本包,请问可以从哪儿找到? 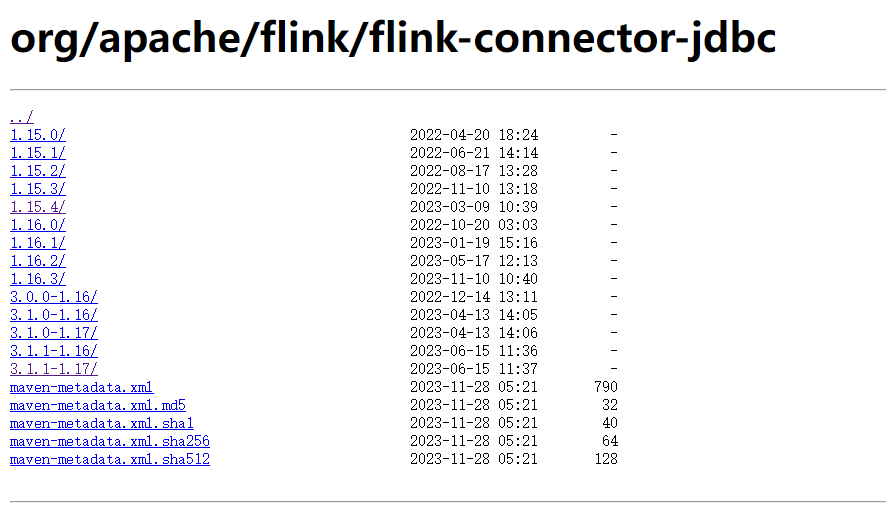
参考回答:
还没开发出来,wait。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/594817?spm=a2c6h.13066369.question.85.283f3f33ojEtvG
