问题一:flink报错
你好,flink在运行job时发现如下报错 Could not allocate all requires slots within timeout of 300000 ms. Slots required: 3, slots allocated: 2 但是观察flink的web页面时发现slot还有170多个,还有其它原因会导致这个错误的出现吗?*来自志愿者整理的flink邮件归档
参考答案:
分配slot超时了,导致只分配了两个,还有一个超时了没有分配成功,你查看下日志,找下超时原因。*来自志愿者整理的flink
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/372233?spm=a2c6h.13066369.question.43.6f064d5cLVu4GJ
问题二:报错日志如下,为什么出现报错呢?
"报错日志如下,为什么出现报错呢? org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:139)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getGlobalFailureHandlingResult(ExecutionFailureHandler.java:102)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleGlobalFailure(DefaultScheduler.java:299)
at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder$LazyInitializedCoordinatorContext.lambda$failJob$0(OperatorCoordinatorHolder.java:635)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:453)
at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:453)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:218)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:84)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:168)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at akka.actor.Actor.aroundReceive(Actor.scala:537)
at akka.actor.Actor.aroundReceive$(Actor.scala:535)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
at akka.actor.ActorCell.invoke(ActorCell.scala:548)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
at akka.dispatch.Mailbox.run(Mailbox.scala:231)
at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)
Caused by: org.apache.flink.util.FlinkException: Global failure triggered by OperatorCoordinator for 'Source: products[7] -> DropUpdateBefore[8] -> ConstraintEnforcer[9] -> Sink: sink_products[9]' (operator cbc357ccb763df2852fee8c4fc7d55f2).
at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder$LazyInitializedCoordinatorContext.failJob(OperatorCoordinatorHolder.java:617)
at org.apac"
参考答案:
设置了你的时区后,重启flink集群。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/497144?spm=a2c6h.13066369.question.44.6f064d5cVqGiJm
问题三:Flink这个报错是 任务太多了吗?
Flink这个报错是 任务太多了吗? org.apache.flink.shaded.zookeeper3.org.apache.zookeeper.KeeperException$NumberQuotaExceedException: KeeperErrorCode = Nodes number exceeds quota limit for /flink2/application_1670910941835_27837/leader
参考答案:
这个报错是因为 Flink 使用的 ZooKeeper 集群节点数目超出了 ZooKeeper 的节点数量限制。每个 ZooKeeper 集群都有节点数量的限制,当超过限制时就会出现 KeeperException$NumberQuotaExceedException 异常。
该异常一般发生在 Flink 集群规模较大、任务数量较多的情况下。解决该异常的方法是:
1、增加 ZooKeeper 集群的节点数量限制。 在 Kafka、Hadoop 等大数据生态系统中,ZooKeeper 集群节点数量的限制通常会被修改为更大的值。如果您的 ZooKeeper 集群节点数量已达到限制,则需要修改节点数量限制,以容纳更多的 Flink 集群节点。
2、减少 Flink 集群节点数量。 如果您的 ZooKeeper 集群节点数量已经达到了上限,且无法修改限制时,则需要减少 Flink 集群节点数量。可以通过增加每个节点的内存、CPU 资源,以提高每个节点的处理能力,从而减少节点数量。
3、将 Flink 集群拆分成多个子集群。 如果无法增加 ZooKeeper 集群节点数量限制,且无法减少 Flink 集群节点数量时,可以将 Flink 集群拆分成多个子集群,并将它们连接到不同的 ZooKeeper 集群上。这样可以将节点数量分散到多个 ZooKeeper 集群上,从而解决该问题。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/491319?spm=a2c6h.13066369.question.45.6f064d5cnYJqmC
问题四:flink on k8s 报错读不出kafka数据来,on yarn没问题 有大佬知道这什么报错吗?
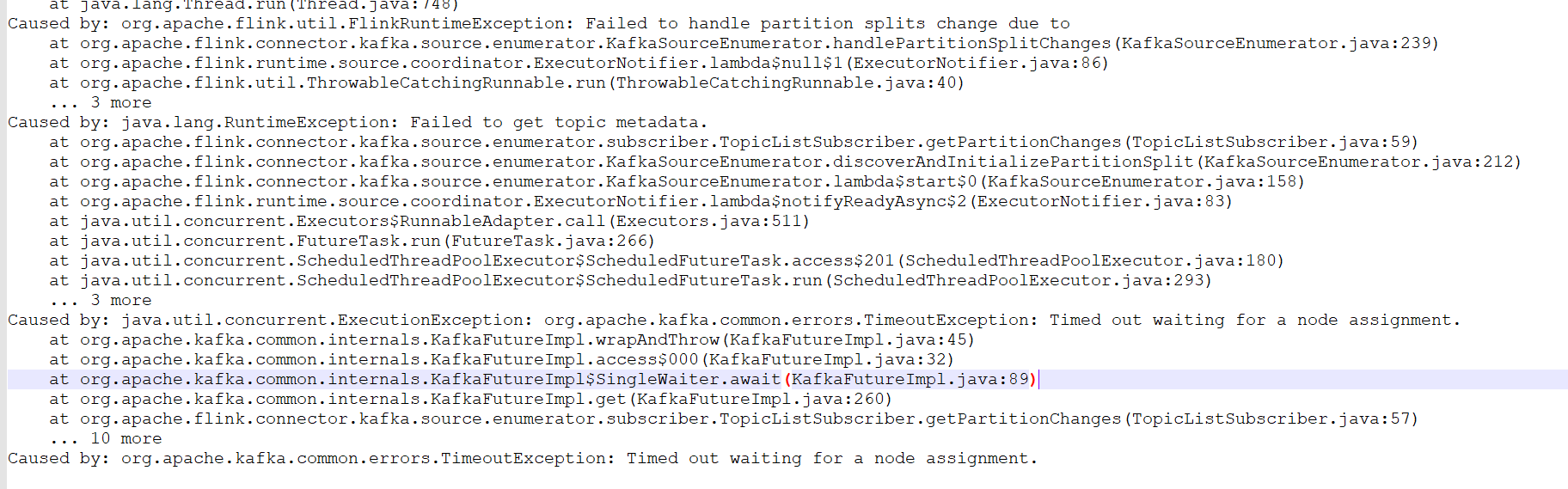 flink on k8s 报错读不出kafka数据来,on yarn没问题 有大佬知道这什么报错吗?
flink on k8s 报错读不出kafka数据来,on yarn没问题 有大佬知道这什么报错吗?
参考答案:
网络问题。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/492517?spm=a2c6h.13066369.question.46.6f064d5cG6zs1N
问题五:用flink1.13版本写入ES8.5.3版本,数据只能写入一部分,之后报错,为什么?
用flink1.13版本写入ES8.5.3版本,数据只能写入一部分,之后报错Failed Elasticsearch item request: Unable to parse response body for Response{requestLine=POST /_bulk?timeout=1m HTTP/1.1, host=http://10.206.67.212:9200, response=HTTP/1.1 200 OK}; 这是什么原因
参考答案:
这个问题可能是由于ES的限制引起的。ES有一个默认的请求体大小限制,如果一次请求体大小超过该限制,则会抛出类似的异常。根据你提供的信息,问题的原因可能是请求体过大,导致ES无法正确解析请求体,从而导致写入错误。
为了解决这个问题,可以尝试以下几种方法:
增加ES的请求体大小限制。可以在ES的配置文件中调整该值。具体操作可以参考ES的官方文档。
减小flink写入ES时的批处理大小。可以将写入ES的批处理大小调小一些,这样可以减小请求体大小,从而避免ES的限制。
对数据进行分批处理。可以将数据分成多个批次处理,每个批次的数据量比较小,这样可以避免一次请求体过大的问题。
需要注意的是,如果数据量较大,可能需要同时采用多种方法来解决该问题。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/491328?spm=a2c6h.13066369.question.45.6f064d5ca6JeEg
