JasonLee实时计算

已加入开发者社区2353天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人






粉丝
技术能力
兴趣领域
- Java
擅长领域
技术认证
暂时未有相关云产品技术能力~
博主一直从事大数据开发的工作,工作经验非常丰富,目前主要专注于 Flink 实时计算领域,就职于一线互联网大厂。
暂无精选文章
暂无更多信息
2022年06月
-
06.07 17:55:31
 发表了文章
2022-06-07 17:55:31
发表了文章
2022-06-07 17:55:31
Flink on zepplien的安装配置
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的notebook。Zeppelin提供了数据可视化的框架。Flink结合zepplien使用可以让提交Flink任务变的简单化. 从Zeppelin 0.9开始将正式支持Flink 1.10。Flink是一个批流统一的计算引擎,本文将从第一个wordcount的例子为起点来介绍一下Flink on zeplien(on yarn)的配置和使用. 版本说明: Flink 1.11.0 -
06.07 17:50:47发表了文章
2022-06-07 17:50:47
Flink源码分析:WindowOperator底层实现
上一篇文章介绍了 Flink窗口机制的执行流程,其实WindowOperator才是真正负责window中元素存储和计算流程的核心类。这篇文章主要就是分析一下WindowOperator的执行逻辑。 apply方法 接着上一篇从apply方法入手,先来看一下apply的代码逻辑。 -
06.07 17:46:13发表了文章
2022-06-07 17:46:13
Flink源码分析: 窗口机制的执行流程
这篇文章主要是研究一下Flink的window执行流程,但是不会详细的分析代码实现的细节,因为这部分的代码还是非常多的,先了解一下代码执行的整个流程,为后面分析WindowOperator的源码实现逻辑做一个铺垫. 关于Flink的window使用相信大家都比较熟悉了,日常开发中很多场景都会用到window,可以说window是Flink流计算的核心功能之一,我们先来看下官网对于window的使用流程介绍.(这里以keyed Windows为例). -
06.07 17:43:03发表了文章
2022-06-07 17:43:03
Flink到底能不能实现exactly-once语义
关于这个问题其实从一开始很多人是存在质疑的,首先exactly-once语义指的是即使在出现故障的情况下,Flink流应用程序中的所有算子都保证事件只会被"精确一次"(恰好一次,不多不少)的处理.假设有下面一个场景,Flink在完成了一次checkpoint后,第二次checkpoint前(此时两个checkpoint中间的数据已经处理了一部分了)任务挂掉了,然后任务恢复的时候会从上一次成功的checkpoint处恢复(也即是checkpoint ID为1的位置)任务,那这个时候刚才被处理的数据又会被处理一次,这部分数据被处理了两次甚至可能是多次,那这就不能称为exactly-once语义了啊 -
06.07 17:40:17发表了文章
2022-06-07 17:40:17
Flink 1.10.0 SQL DDL中如何定义watermark和计算列
随着Flink1.10.0版本的发布,在SQL上一个重大的优化是支持了watermark语义的计算,在之前的Flink1.9.x版本中是不支持的,当时只能用SQL DDL进行processing time的计算,但是现在可以进行eventtime语义的计算了,那在Flink1.10.0版本中也推出了很多新的特性,这里就不在多介绍了,本篇文章主要是接上一篇文章,FlinkSQL使用DDL语句创建kafka源表,主要来介绍一下Flink1.10.0中怎么定义watermark. -
06.07 17:29:19发表了文章
2022-06-07 17:29:19
FlinkSQL使用DDL语句创建kafka源表
在Flink1.9.x版本中,社区版本的 Flink 新增 了一个 SQL DDL 的新特性,但是暂时还不支持流式的一些概念的定义,比如说水位(watermark). 下面主要介绍一下怎么使用DDL创建kafak源表. 定义create table语句从kafka中读取数据 """ |CREATE TABLE PERSON ( | name VARCHAR COMMENT '姓名', | age VARCHAR COMMENT '年龄', | city VARCH -
06.07 17:26:06发表了文章
2022-06-07 17:26:06
Linux环境安装Protobuf
1,下载地址: https://github.com/protocolbuffers/protobuf/releases 最好是下载-all的包,因为里面的依赖文件比较全,不然还需要下载各种依赖,可能会遇到各种报错,我这里下载的是3.11.2版本,自己根据情况下面对应的版本. 2,解压编译 1, tar -zxvf protobuf-all-3.11.2.tar.gz 2, ./configure 3, make 4, make install 最后两步比较的慢,耐心等待就行,完成后运行下面的命令可以看到版本的信息 执行 protoc --version 会显示 libpro -
06.07 17:23:18发表了文章
2022-06-07 17:23:18
Flink 状态清除的演进之路
对于流计算程序来说,肯定会用到状态(state),假如状态不自动清除,并且随着作业运行的时间越来越久,就会累积越多越多的状态,就会影响任务的性能,为了有效的控制状态的大小,Flink从1.6.0开始引入了状态的生存时间(TTL)功能,这样就可以实现自动清理状态,控制状态的大小.本文主要介绍一下Flink从1.6.0开始到1.9.1的状态清理不断的演进之路. Flink1.6.0状态清除 Apache Flink 的 1.6.0 版本引入了状态生存时间特性。它使流处理应用程序的开发人员能够配置算子的状态,使其在定义的生存时间超时后被清除。 -
06.07 17:17:41发表了文章
2022-06-07 17:17:41
maven环境下java和scala混合开发如何打依赖包?
在实际的项目开发中,很多时候我们可能会用java和scala混合开发,比如Flink或者Spark的项目,他们两个可以相互调用,也有各自的优缺点,结合起来使用非常的方便,但是在编译打包的时候很多朋友遇到要么Java的包没打进去,或者Scala的包没打进去,运行的时候报各种找不到jar包的错,下面介绍一种打包的方法,可以运行项目里面的任何一个方法,供大家参考,当然还有很多其他的打包方式. 直接看下面的maven里面的配置 <build> -
06.07 17:15:15发表了文章
2022-06-07 17:15:15
greenplum(gp)的常用命令
下面列举一些gp数据库的常用命令,这只是其中的一部分 连接gp命令: psql -d 库名 -h ip地址 -p 端口号 -U 用户名; gp 添加分区: alter table 表名 add partition d20190611 values('20190611') ; gp 添加字段: alter table 表名 add column update_flag varchar(255); gp 重命名: alter table 表名 rename column old_column_name to new_column_name; -
06.07 17:13:39发表了文章
2022-06-07 17:13:39
maven打包报错java.lang.StackOverflowError解决方法
在maven项目打包的时候报错,java.lang.StackOverflowError 解决方法在setting->maven->runner->VM Options中添加 -Xss4096k 如下图所示 再次点击打包就可以了,如果还是报错的话,可以尝试把这个值在增大一点.
-
06.07 17:10:58发表了文章
2022-06-07 17:10:58
hbase怎么修改表名?
hbase本身没有提供修改表名的命令,那如果我们需要修改表名,该怎么办呢? 可以通过snapshot的功能来实现 先来看下hbase里面有哪些表: list 我们把test1修改成test2 1,禁用表 disable 'test1'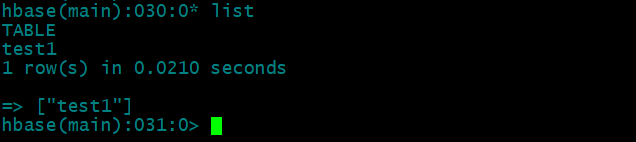
-
06.07 17:08:19发表了文章
2022-06-07 17:08:19
在idea里面怎么远程提交spark任务到yarn集群
很久没有更新了,因为最近一段时间有点小忙,最近也是有同学问我说自己在idea里面写spark程序测试,每次都要打包然后上传到集群,然后spark-submit提交很麻烦,可不可以在idea里面直接远程提交到yarn集群呢? 当然是可以的,今天就给大家分享一下具体的操作过程. 那先来说一下spark任务运行的几种模式: 1,本地模式,在idea里面写完代码直接运行. -
06.07 17:02:54发表了文章
2022-06-07 17:02:54
【Flink实战系列】Blink的UI焕然一新,我觉得还行
今天带大家看一下Blink的UI的一些新功能,编译的过程这里就不说了,网上也有很多的教程,我们直接启动一个Blink的standalone的集群,然后进入他的UI页面,我先放几张截图,大家随意感受一下 首先给人的第一感觉就是界面做的很炫酷,比Flink的UI要丰富很多,不像Flink的UI那样简单,界面也很阿里风格,多了很多新的功能,然后我们直接提交一个job上去,选择正在运行的job,如下图所示
2022年05月
-
05.31 00:02:13发表了文章
2022-05-31 00:02:13
elasticsearch 怎么删除过期的数据
使用elasticsearch收集日志进行处理,时间久了,很老的数据就没用了或者用途不是很大,这个时候就要对过期数据进行清理.但是es5.0之后就不支持ttl,那怎么办呢? 1,请使用官方的工具elasticsearch-curator 2,使用delete-by-query方法删除特定时间范围的数据 第一种这里不再介绍了,直接看官网吧,主要说下第二种 -
05.30 23:59:56发表了文章
2022-05-30 23:59:56
hive 的注释(comment) 中文乱码的解决方法(亲测有效)
最近群里有人问我hive中文显示乱码的问题, 下面就来说一下,怎么设置. 创建表的时候,comment说明字段包含中文,表成功创建成功之后,desc的时候中文说明显示乱码.如下图所示: 我们知道hive的元数据是有mysql管理的,所以这是mysql的元数据的问题.下面我们就修改一下字符编码 (1)修改表字段注解和表注解 alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8; alter table TABLE_PARAMS modify column PARAM_VALUE var
-
05.30 23:57:05发表了文章
2022-05-30 23:57:05
【算法】java 实现数组的反转
数组的反转原理跟冒泡排序有点像,都是通过交换位置,只不过数组的反转是交换第一个和最后一个的位置,第二个和倒数第二个的位置,冒泡排序是交互相邻两个的位置.下面看一下具体的代码实现 package test; /** * 数组的反转 -
05.30 23:55:03发表了文章
2022-05-30 23:55:03
java二分查找算法实现
package arithmetic; /** * @author JasonLee * @description java的二分查找(折半查找),前提是数组中的数据是有序的 * 思想:搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素, * 则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空, * 则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半 -
05.30 23:53:07发表了文章
2022-05-30 23:53:07
java冒泡排序算法实现
简单的总结一下冒泡排序的实现: package arithmetic; /** * @author JasonLee * @description java的冒泡排序算法 * 原理:比较两个相邻的元素,将值大的元素交换至右端 */ -
05.30 23:50:59发表了文章
2022-05-30 23:50:59
scala中怎么跳出循环
在java中跳出循环的时候,我们可以直接break就行了,但是在scala里面没有break,那怎么跳出循环呢? 直接看下面的demo: package test import scala.util.control.Breaks object ListDemo { def main(args: Array[String]): Unit = { var loop = Breaks var i = 0 loop.breakable { while (i < 10) { println(i) i += 1 -
05.30 23:48:51发表了文章
2022-05-30 23:48:51
scala中的list怎么存储对象
scala中的list是一个不可变的列表,有时候我们想直接添加对象不太方便,这个时候可以先转成java的List添加完再转回去. LIst支持在头部快速添加和移除条目,但是不提供快速按下标访问的功能,这个功能需要线性遍历列。 快速的头部添加和移除意味着模式匹配很顺畅 -
05.30 23:45:55发表了文章
2022-05-30 23:45:55
hadoop 的启动和停止命令(史上最全)
sbin/start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager sbin/stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode sbin/stop-dfs.sh 停止Hadoop -
05.30 23:44:09发表了文章
2022-05-30 23:44:09
datax从mysql导入数据到mysql
一般从数仓数据导入到MySQL中,可以从hive查询存储到一个文件里面,如果是数据量比较大的情况下先将文件按一定行数切分为多个文件,然后遍历文件往MySQL中导入,这种方式虽然简单,缺点在于对于每一个导入需求,都需要写一个job,并且每次都会产生临时文件,mysql load会比较占用资源,之所以选择了DataX,因为它能实现hdfs导入MySQL,速度快,能实现增量全量,可以分表,能减少很多技术的实现成本。 -
05.30 23:40:20发表了文章
2022-05-30 23:40:20
spark on yarn模式安装和配置carbondata
前置条件 Hadoop HDFS 和 Yarn 需要安装和运行。 Spark 需要在所有的集群节点上安装并且运行。 CarbonData 用户需要有权限访问 HDFS. 以下步骤仅针对于 Driver 程序所在的节点. (Driver 节点就是启动 SparkContext 的节点) -
05.30 23:35:37发表了文章
2022-05-30 23:35:37
Hbase的Rowkey设计以及如何进行预分区
今天有人问我Hbase的rowkey设计和预分区的问题,这篇文字就简单介绍一下.,关于Hbase的表的一些基本概念这里就不说了,直接说重点,尽可能说的简单一点,废话就不写了. 1.什么是Rowkey? 我们知道Hbase是一个分布式的、面向列的数据库,它和一般关系型数据库的最大区别是:HBase很适合于存储非结构化的数据,还有就是它基于列的而不是基于行的模式.
-
05.30 23:30:34发表了文章
2022-05-30 23:30:34
scala之list用法史上最全
Scala 列表类似于数组,它们所有元素的类型都相同,但是它们也有所不同:列表是不可变的,值一旦被定义了就不能改变,其次列表 具有递归的结构(也就是链接表结构)而数组不是 下面是list的常用方法,当然了这不是所有的.但都是最常用的.具体看下面的demo.具体可以看代码里面的注释 -
05.30 23:27:54发表了文章
2022-05-30 23:27:54
elasticsearch 如何设置高亮显示 ?
许多应用都倾向于在每个搜索结果中 高亮 显示搜索的关键词,比如字体的加粗,改变字体的颜色等.以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。 为了执行突出显示,需要该字段的实际内容。如果存储了相关字段(已 在映射中store设置true),则将使用_source该字段,否则将加载实际字段并从中提取相关字段。 -
05.30 23:24:28发表了文章
2022-05-30 23:24:28
storm集群的搭建
最近也是有朋友问我storm的问题,好长时间没玩storm了,今天就来简单的说一下吧,首先我们来看一下官网的图片,storm是完全实时的,就像水龙头打开后一样,会不停的往外面流水.所以他的延迟非常的低,这也是他的特点.然后先搭建storm集群吧,storm集群的搭建也比较简单.
-
05.30 23:21:38发表了文章
2022-05-30 23:21:38
failed to start lsb:bring up/down
centos 7 有的时候重启网络报错,failed to start lsb:bring up/down 解决方法: systemctl stop NetworkManager -
05.30 23:13:40发表了文章
2022-05-30 23:13:40
hive中udf的开发
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就可以方便地插入用户写的处理代码并在查询中使用它们,相当于在HQL(Hive SQL)中自定义一些函数,首先UDF必须用java语言编写,Hive本身就是用java写的,sparksql中UDF的使用移步到这 编写UDF需要下面两个步骤: -
05.30 23:10:11发表了文章
2022-05-30 23:10:11
java,scala读写kafka操作
今天主要简单写一下kafka的读写,我写了java,scala两个版本的,写法比较老,但都能用,已经测试过了,直接上代码吧; java版本: package com.cn.kafka; import java.util.Arrays; import java.util.HashMap; -
05.30 23:08:07发表了文章
2022-05-30 23:08:07
scala中的:: , +:, :+, :::, +++, 等操作的含义
package test /** * scala中的:: , +:, :+, :::, +++, 等操作; */ object listTest { def main(args: Array[String]): Unit = { val list = List(1,2,3) // :: 用于的是向队列的头部追加数据,产生新的列表, x::list,x就会添加到list的头部 println(4 :: list) //输出: List(4, 1, 2, 3) // .:: 这个是list的一个方法;作用和上面的一样,把元素添加到头部位置; list. -
05.30 23:06:08发表了文章
2022-05-30 23:06:08
kafka的常用命令
1.kafka启动: ./kafka-server-start.sh ../config/server.properties & 2.创建topic: ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic tes 3.查看kafka的topic:./kafka-topics.sh --zookeeper master:2181 --list 4.查看kafka某个topic下partition信息: ./kafka-topics.sh --des -
05.30 23:03:09发表了文章
2022-05-30 23:03:09
hbase的表映射到hive中
1.本文主要说一下怎么把hbase中的表映射到hive中,说之前我们先简单说一下hive的内部表和外部表的区别; (1),被external关键字修饰的表是外部表,没有被external关键字修饰的表是内部表. (2),内部表数据由Hive自身管理,外部表数据由HDFS管理. (3),内部表数据存储的位置是hive.metastore.warehouse.dir.外部表数据的存储位置由自己确定. (4),删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除; -
05.30 22:58:27发表了文章
2022-05-30 22:58:27
redis的hash结构用法
我们都知道redis支持5种数据类型的存储,今天主要来说一下hash散列的使用: String: 字符串 Hash: 散列 List: 列表 Set: 集合 Sorted Set: 有序集合 Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
-
发表了文章
2022-06-10
Flink on yarn 实时日志收集到 kafka 打造日志检索系统
-
发表了文章
2022-06-10
Flink 任务实时监控最佳实践(Prometheus + Grafana)打造企业级监控方案
-
发表了文章
2022-06-10
Flink项目实战系列(Spark项目实战系列)
-
发表了文章
2022-06-10
scala的模式匹配
-
发表了文章
2022-06-10
hive2.2.0安装与配置(元数据保存在mysql中)
-
发表了文章
2022-06-10
centos7安装mysql5.6.38史上最详细的安装步骤
-
发表了文章
2022-06-10
carbondata1.5.1编译
-
发表了文章
2022-06-10
hbase的常用命令
-
发表了文章
2022-06-10
【leetcode-141】环形链表
-
发表了文章
2022-06-10
Flink 源码:广播流状态源码解析
-
发表了文章
2022-06-10
IDEA 中使用 Big Data Tools 连接大数据组件
-
发表了文章
2022-06-10
【leetcode-235】面试题 02.02. 返回倒数第 k 个节点
-
发表了文章
2022-06-10
【leetcode-235】二叉搜索树的最近公共祖先
-
发表了文章
2022-06-10
Flink 通过 State Processor API 实现状态的读取和写入
-
发表了文章
2022-06-10
Apache Flink 1.14.4 Release Announcement
-
发表了文章
2022-06-10
Flink 实现自定义滑动窗口
-
发表了文章
2022-06-10
【leetcode-34】在排序数组中查找元素的第一个和最后一个位置
-
发表了文章
2022-06-10
【leetcode-剑指 Offer 42】连续子数组的最大和
-
发表了文章
2022-06-10
【leetcode-剑指 Offer 55 - II】平衡二叉树
-
发表了文章
2022-06-10
【leetcode-剑指 Offer 34】二叉树中和为某一值的路径
滑动查看更多

暂无更多信息