
"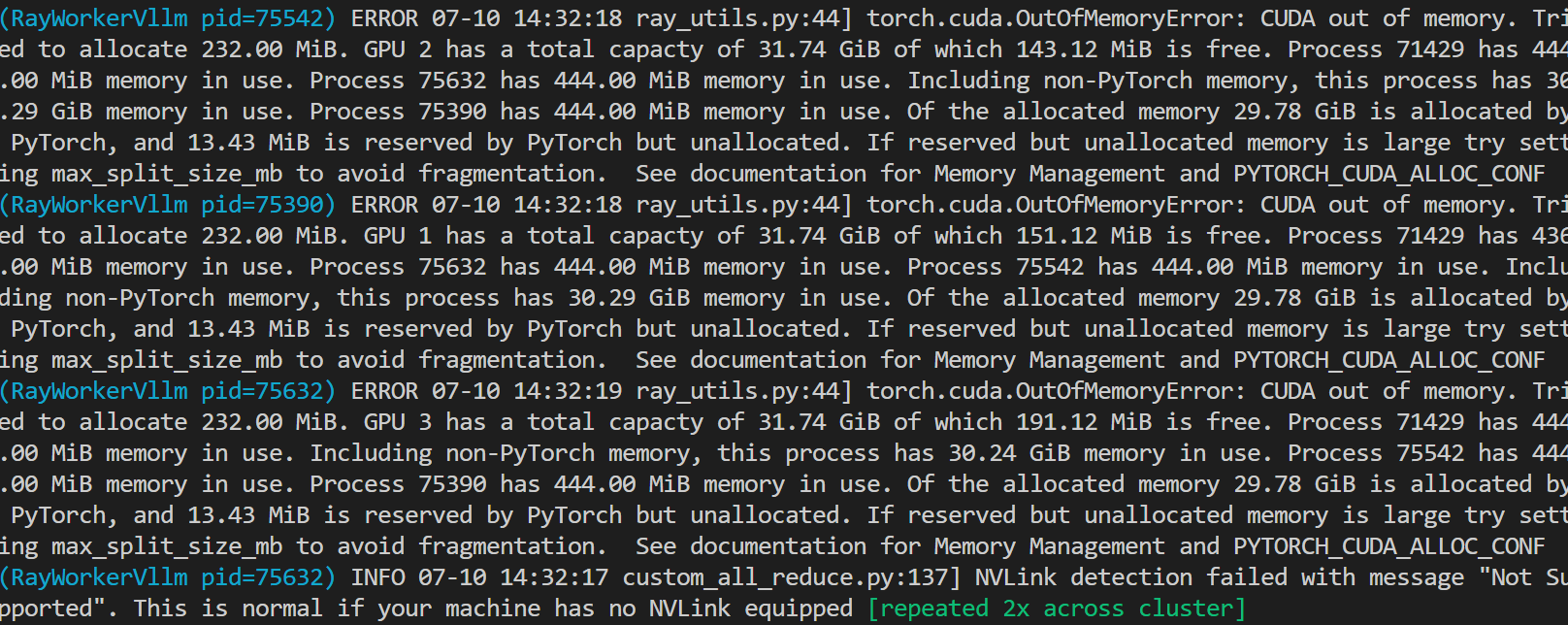
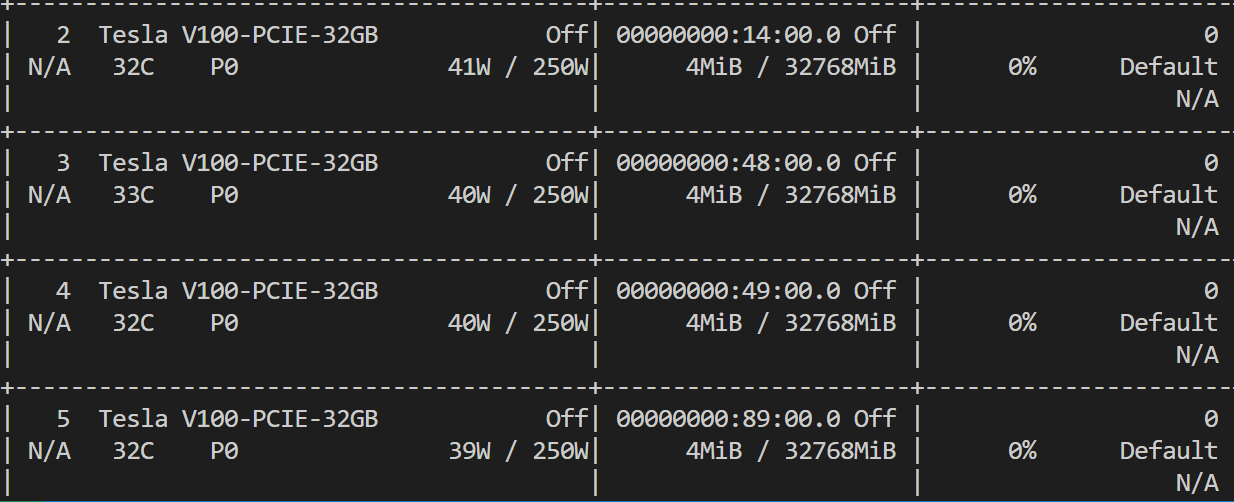
图一是报错,好像是说内存不足,但是机器状态是图2,感觉内存没被占用。这是代码import requestsfrom swift.llm import ( ModelType, get_vllm_engine, get_default_template_type, get_template, inference_vllm, inference_stream_vllm)# 设置环境变量os.environ['CUDA_VISIBLE_DEVICES'] = '2,3,4,5'os.environ['RAY_memory_monitor_refresh_ms'] = '0'# 启动 vLLM API 服务器server_process = subprocess.Popen([ 'python', '-m', 'vllm.entrypoints.openai.api_server', '--model', './qwen/Qwen2-72B-Instruct', '--dtype', 'half', '--tensor-parallel-size', '4' ])。请问以上ModelScope问题如何解决呢?"
您用这个文档中的部署命令呢,有多卡部署,参考以下链接
https://github.com/modelscope/swift/blob/main/docs/source/LLM/VLLM%E6%8E%A8%E7%90%86%E5%8A%A0%E9%80%9F%E4%B8%8E%E9%83%A8%E7%BD%B2.md
此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
