
自动语音识别 (ASR) 原始输出的文本不含标点,且口语的ASR识别结果通常包含大量不顺滑的短语。随着自动语音识别(ASR)技术的广泛应用,以标点预测和顺滑检测为代表的语音识别文本后处理技术越来越受到重视。文本后处理技术能提升语音识别输出文字的可读性。此外,ASR的下游文本处理应用,包括机器翻译、对话系统等等,通常开发在顺滑和含有标点的规范文本上。因此,文本后处理技术还能提升下游任务的性能。本文将揭秘阿里语音AI原创的可控时延后处理模型CT-Transformer,该成果即将发表在顶级国际会议ICASSP 2020上 [1]。
下面用一个典型的例子来说明什么是文本后处理技术中的标点预测和顺滑检测技术,如图1所示。例如,“I want a flight to Boston um to Denver”。对于标点预测,我们需要预测每个词后是否有某种标点,比如逗号、问号、句号。在这个例子中,Denver这个词后会有一个句号。对于顺滑检测,主要包括检测两种需要被顺滑的类型,RM(Reparandum)和IM(Interregnum)。RM是被后面纠正或者被丢弃的词组,包括重复词,被修复词等。IM则指停顿词、语气词等。对于前面的例子,词组“to Boston”需要被检测为RM,单词“um”需要被检测为IM。经过标点预测和去除检测出来的RM和IM词组,原来的ASR 输出文本转化为 “I want a flight to Denver.”
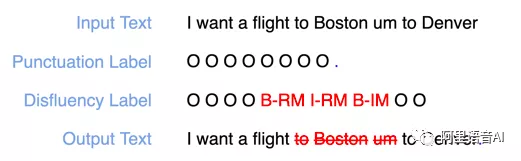
图1
对于一个实时的后处理系统而言,在保证高准确率的前提下,尽可能降低时延是至关重要的挑战。例如,同声传译系统中,要求后处理输出的口语文本提前固定从而降低整个系统的时延。阿里语音AI从建模方法和解码策略两个方面来应对这个挑战。
可控时延文本后处理算法图2是阿里语音AI原创的可控时延后处理模型Controllable Time-Delay Transformer (CT-Transformer) 示意图。模型的输入是口语ASR原始输出的文本。该文本经过词向量和位置向量编码,然后输入至CT-Transformer模型进行特征提取。最后,输出的隐层向量会分别送入标点标注分类器和顺滑标注分类器进行标点预测和顺滑检测。这里采用的是经典的序列标注框架,且利用的多任务学习的思想共享编码模型,来缩短pipelined系统带来的额外时延。
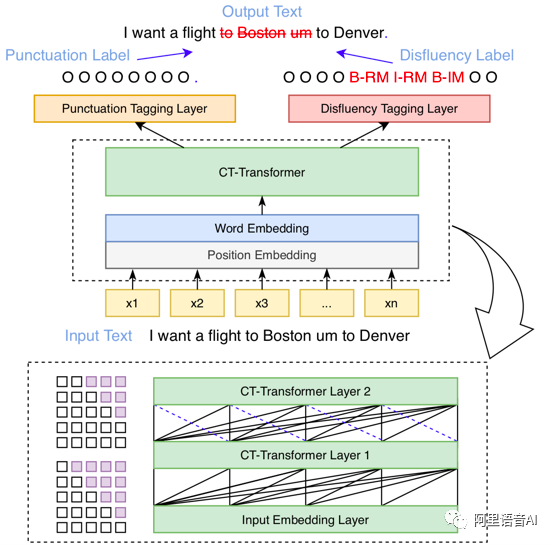
图2
图3 展示了CT-Transformer与传统的Full-Transformer模型的比较。Full-Transformer每个token会依赖全部序列;CT-Transformer只依赖未来固定长度的tokens和全部的历史序列,因此CT-Transformer可以满足下游任务所需要的提前固定部分输出结果的实时要求。
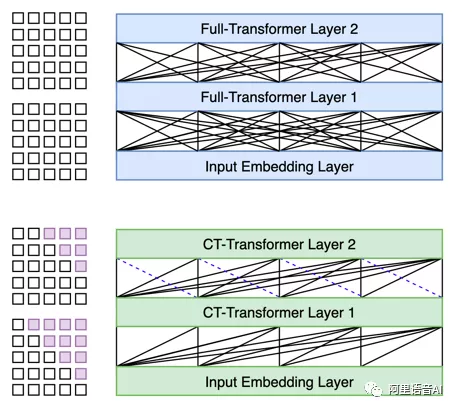
图3
除了CT-Transformer 的建模方法之外,我们提出了一种快速解码策略,如图4所示。其基本思路是在实时文本后处理系统的流式处理中,当第一个预测的句尾标点之后的字数超过预设的阈值时,句尾标点之前的句子将不再在解码中考虑,从而进一步降低后处理的时延。

图4
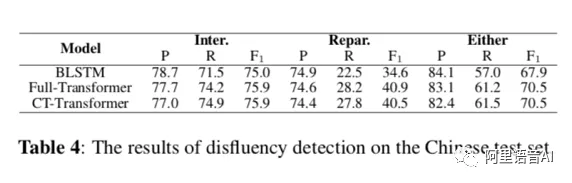
我们在英文和中文两个数据集上同目前最先进的后处理方法进行了实验比较。在英文的IWSLT2011数据集上,CT-Transformer比最先进的Self-attention-word-speech方法和Full-Transformer都有显著提高的标点预测准确率;在中文数据集上,CT-Transformer比BLSTM有显著提高的标点预测和顺滑检测准确率,和Full-Transformer准确率相同,且有更快的解码速度。


本技术在阿里集团内部的语音实时转写、实时字幕、实时翻译等领域有着广泛的应用,成为了阿里集团ASR 技术输出的一个必不可少的模块。
[1] Qian Chen, Mengzhe Chen, Bo Li and Wen Wang, “Controllable Time-Delay Transformer for Real-Time Punctuation Prediction and Disfluency Detection,” ICASSP (2020)
智能语音产品官网链接:https://ai.aliyun.com/nls

