
端到端语音识别技术在单语种任务上取得了哪些成果,但在多语种混说场景下存在什么问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
端到端语音识别 (End-to-End ASR) 技术在单语种任务上已经取得了比较好的效果,通过UNIVERSAL ASR 统一离线和流式识别系统架构进一步提升了流式场景的识别率,但在多语种混说 (Code-Switch) 场景下效果还不是很理想,比如中英文混说——“借你的ipad给我看下paper”,当突然切换到另一个语种时识别率会发生大幅下降,比如中文 ASR 突然遇到纯英文识别。
针对中英文自由说识别问题,我们借鉴了混合专家系统 (Mixture of Experts) 的思想。在端到端语音识别模型中,对中文和英文分别设计了一个子网络,每个子网络被称为专家,最后通过门控模块对每个专家网络的输出进行加权。同时为了减少模型参数量,中、英文子网络采用底层共享,高层独立的方式。通过这样的方式,使模型在中文、英文、中英文混说场景下都能取得比较好的效果。进一步我们结合达摩院语音实验室自研的 SAN-M 网络,打造了达摩院语音实验室新一代的端到端中英自由说语音识别系统。在不需要语种信息的前提下,用一个模型保证纯中文和纯英文相对于单语模型的识别性能基本不降,并且大幅度提升中英文混说场景下的识别性能。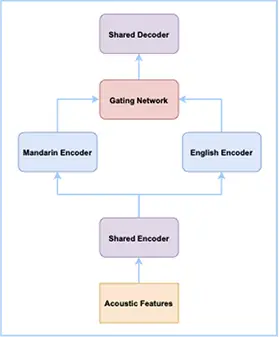
——参考链接。

