
目录
《Spatial Transformer Networks》的翻译与解读
3.2 Parameterised Sampling Grid
3.3 Differentiable Image Sampling
3.4 Spatial Transformer Networks
4.3 Fine-Grained Classification
《Spatial Transformer Networks》的翻译与解读
| 链接 | https://arxiv.org/pdf/1506.02025.pdf |
| 作者 | Max Jaderberg Karen Simonyan Andrew Zisserman Koray Kavukcuoglu Google DeepMind, London, UK {jaderberg,simonyan,zisserman,korayk}@google.com |
Abstract
| Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations. | 卷积神经网络定义了一种非常强大的模型,但仍然受到限制,因为在计算和参数有效的方式下,缺乏对输入数据的空间不变性。在这项工作中,我们引入了一个新的可学习模块,空间转换器,它明确地允许对网络内的数据进行空间操作。这个可微模块可以插入到现有的卷积架构中,使神经网络能够以特征映射本身为条件主动对特征映射进行空间变换,而无需任何额外的训练监督或修改优化过程。我们表明,空间转换器的使用会导致模型学习到平移、缩放、旋转和更一般的扭曲的不变性,从而在几个基准测试和许多类转换上获得最先进的性能。 |
1 Introduction
| Over recent years, the landscape of computer vision has been drastically altered and pushed forward through the adoption of a fast, scalable, end-to-end learning framework, the Convolutional Neural Network (CNN) [21]. Though not a recent invention, we now see a cornucopia of CNN-based models achieving state-of-the-art results in classification [19, 28, 35], localisation [31, 37], semantic segmentation [24], and action recognition [12, 32] tasks, amongst others. A desirable property of a system which is able to reason about images is to disentangle object pose and part deformation from texture and shape. The introduction of local max-pooling layers in CNNs has helped to satisfy this property by allowing a network to be somewhat spatially invariant to the position of features. However, due to the typically small spatial support for max-pooling (e.g. 2 × 2 pixels) this spatial invariance is only realised over a deep hierarchy of max-pooling and convolutions, and the intermediate feature maps (convolutional layer activations) in a CNN are not actually invariant to large transformations of the input data [6, 22]. This limitation of CNNs is due to having only a limited, pre-defined pooling mechanism for dealing with variations in the spatial arrangement of data. |
近年来,通过采用快速、可扩展、端到端学习框架——卷积神经网络(CNN)[21],计算机视觉领域发生了翻天覆地的变化。虽然不是最近才发明的,但我们现在看到大量基于cnn的模型在分类[19,28,35]、定位[31,37]、语义分割[24]和动作识别[12,32]任务等方面取得了最先进的结果。 一个能够对图像进行推理的系统的一个理想特性是将物体的姿态和部分变形从纹理和形状中分离出来。在cnn中引入局部最大池层有助于满足这一特性,因为它允许网络对特征的位置具有一定的空间不变性。然而,由于典型的对最大池的空间支持很小(例如:这种空间不变性仅在max-pooling和convolutions的深层层次上实现,而CNN中的中间特征映射(convolutional layer activation)对于输入数据的大变换实际上并不是不变的[6,22]。cnn的这种局限性是由于只有一种有限的、预定义的池机制来处理数据空间安排的变化。 |
| In this work we introduce a Spatial Transformer module, that can be included into a standard neural network architecture to provide spatial transformation capabilities. The action of the spatial transformer is conditioned on individual data samples, with the appropriate behaviour learnt during training for the task in question (without extra supervision). Unlike pooling layers, where the receptive fields are fixed and local, the spatial transformer module is a dynamic mechanism that can actively spatially transform an image (or a feature map) by producing an appropriate transformation for each input sample. The transformation is then performed on the entire feature map (non-locally) and can include scaling, cropping, rotations, as well as non-rigid deformations. This allows networks which include spatial transformers to not only select regions of an image that are most relevant (attention), but also to transform those regions to a canonical, expected pose to simplify recognition in the following layers. Notably, spatial transformers can be trained with standard back-propagation, allowing for end-to-end training of the models they are injected in. | 在这项工作中,我们介绍了一个空间转换器模块,它可以包含在一个标准的神经网络结构中,以提供空间转换能力。空间转换器的动作以个体数据样本为条件,并在任务训练中学习到适当的行为(没有额外的监督)。与接受域是固定和局部的池化层不同,空间转换器模块是一种动态机制,通过为每个输入样本生成适当的转换,可以主动地对图像(或特征地图)进行空间转换。然后在整个特征图(非局部)上执行转换,可以包括缩放、剪切、旋转以及非刚性变形。这使得包含空间变形器的网络不仅可以选择图像中最相关的区域(注意),而且可以将这些区域转换成规范的、预期的姿态,从而简化以下层中的识别。值得注意的是,空间转换器可以用标准的反向传播进行训练,允许对它们所注入的模型进行端到端的训练。 |
Figure 1: The result of using a spatial transformer as the first layer of a fully-connected network trained for distorted MNIST digit classification. (a) The input to the spatial transformer network is an image of an MNIST digit that is distorted with random translation, scale, rotation, and clutter. (b) The localisation network of the spatial transformer predicts a transformation to apply to the input image. (c) The output of the spatial transformer, after applying the transformation. (d) The classification prediction produced by the subsequent fully-connected network on the output of the spatial transformer. The spatial transformer network (a CNN including a spatial transformer module) is trained end-to-end with only class labels – no knowledge of the groundtruth transformations is given to the system. |
图1:使用空间转换器作为变形MNIST数字分类训练的全连接网络的第一层的结果。(a)空间变压器网络的输入是被随机平移、缩放、旋转和杂波扭曲的MNIST数字的图像。(b)空间转换器的定位网络预测将对输入图像进行转换。(c)空间变压器应用变换后的输出。(d)随后的全连接网络在空间变压器的输出上产生的分类预测。空间变压器网络(包括空间变压器模块的CNN)只使用类标签进行端到端的训练——没有向系统提供关于groundtruth转换的知识。 |
| Spatial transformers can be incorporated into CNNs to benefit multifarious tasks, for example: (i) image classification: suppose a CNN is trained to perform multi-way classification of images according to whether they contain a particular digit – where the position and size of the digit may vary significantly with each sample (and are uncorrelated with the class); a spatial transformer that crops out and scale-normalizes the appropriate region can simplify the subsequent classification task, and lead to superior classification performance, see Fig. 1; (ii) co-localisation: given a set of images containing different instances of the same (but unknown) class, a spatial transformer can be used to localise them in each image; (iii) spatial attention: a spatial transformer can be used for tasks requiring an attention mechanism, such as in [14, 39], but is more flexible and can be trained purely with backpropagation without reinforcement learning. A key benefit of using attention is that transformed (and so attended), lower resolution inputs can be used in favour of higher resolution raw inputs, resulting in increased computational efficiency. The rest of the paper is organised as follows: Sect. 2 discusses some work related to our own, we introduce the formulation and implementation of the spatial transformer in Sect. 3, and finally give the results of experiments in Sect. 4. Additional experiments and implementation details are given in Appendix A. |
空间转换器可以被纳入CNN受益繁杂的任务,例如:(i)图像分类:假设一个CNN训练来执行多路图像分类根据他们是否包含一个特定的数字,数字可能会有所不同的位置和大小明显与每个样本(和不相关的类);裁剪和尺度归一化适当区域的空间转换器可以简化后续的分类任务,并导致更高的分类性能,见图1;(ii)共定位:给定一组包含相同(但未知)类的不同实例的图像,空间转换器可以用于在每个图像中定位它们;(3)空间注意:空间转换器可以用于需要注意机制的任务,如[14,39],但更灵活,可以单纯用反向传播进行训练,无需强化学习。使用attention的一个关键好处是,转换(因此参与)的低分辨率输入可以用于更高分辨率的原始输入,从而提高计算效率。 本文的其余部分组织如下:第2节讨论了与我们相关的一些工作,第3节介绍了空间转换器的设计和实现,最后给出了第4节的实验结果。附录A给出了更多的实验和实现细节。 |

2 Related Work
| In this section we discuss the prior work related to the paper, covering the central ideas of modelling transformations with neural networks [15, 16, 36], learning and analysing transformation-invariant representations [4, 6, 10, 20, 22, 33], as well as attention and detection mechanisms for feature selection [1, 7, 11, 14, 27, 29]. Early work by Hinton [15] looked at assigning canonical frames of reference to object parts, a theme which recurred in [16] where 2D affine transformations were modeled to create a generative model composed of transformed parts. The targets of the generative training scheme are the transformed input images, with the transformations between input images and targets given as an additional input to the network. The result is a generative model which can learn to generate transformed images of objects by composing parts. The notion of a composition of transformed parts is taken further by Tieleman [36], where learnt parts are explicitly affine-transformed, with the transform predicted by the network. Such generative capsule models are able to learn discriminative features for classification from transformation supervision. |
在本节中,我们讨论了之前的相关工作,与神经网络覆盖模型转换的核心观点(15、16,36),学习和分析transformation-invariant表示(4、6、10、20、22、33),以及注意力和检测机制特征选择(1、7、11、14,27岁,29)。 Hinton[15]的早期工作是将标准的参考框架分配给对象部件,这是[16]中反复出现的主题,在这里,2D仿射转换被建模,以创建由转换部件组成的生成模型。生成训练方案的目标是转换后的输入图像,输入图像与目标之间的转换作为网络的额外输入。其结果是一个生成模型,该模型可以通过组成部件来学习生成转换后的物体图像。Tieleman[36]进一步提出了由转换部分组成的概念,学习到的部分通过网络预测的变换进行明确的仿射变换。这种生成胶囊模型能够从转换监督中学习判别特征进行分类。 |
| The invariance and equivariance of CNN representations to input image transformations are studied in [22] by estimating the linear relationships between representations of the original and transformed images. Cohen & Welling [6] analyse this behaviour in relation to symmetry groups, which is also exploited in the architecture proposed by Gens & Domingos [10], resulting in feature maps that are more invariant to symmetry groups. Other attempts to design transformation invariant representations are scattering networks [4], and CNNs that construct filter banks of transformed filters [20, 33]. Stollenga et al. [34] use a policy based on a network’s activations to gate the responses of the network’s filters for a subsequent forward pass of the same image and so can allow attention to specific features. In this work, we aim to achieve invariant representations by manipulating the data rather than the feature extractors, something that was done for clustering in [9]. | 在[22]中,通过估计原始图像和转换后图像的表示之间的线性关系,研究了CNN表示对输入图像转换的不变性和等效性。Cohen和Welling[6]分析了这种与对称群相关的行为,这也被Gens和Domingos[10]提出的架构所利用,从而产生了对对称群更不变的特征映射。设计变换不变表示的其他尝试包括散射网络[4]和构造变换滤波器组的CNNs[20,33]。Stollenga等人[34]使用一种基于网络激活的策略来屏蔽网络过滤器的响应,以便后续转发相同的图像,从而允许关注特定的特征。在这项工作中,我们的目标是通过操纵数据而不是特征提取器来实现不变表示,这在[9]中是为了聚类而做的。 |
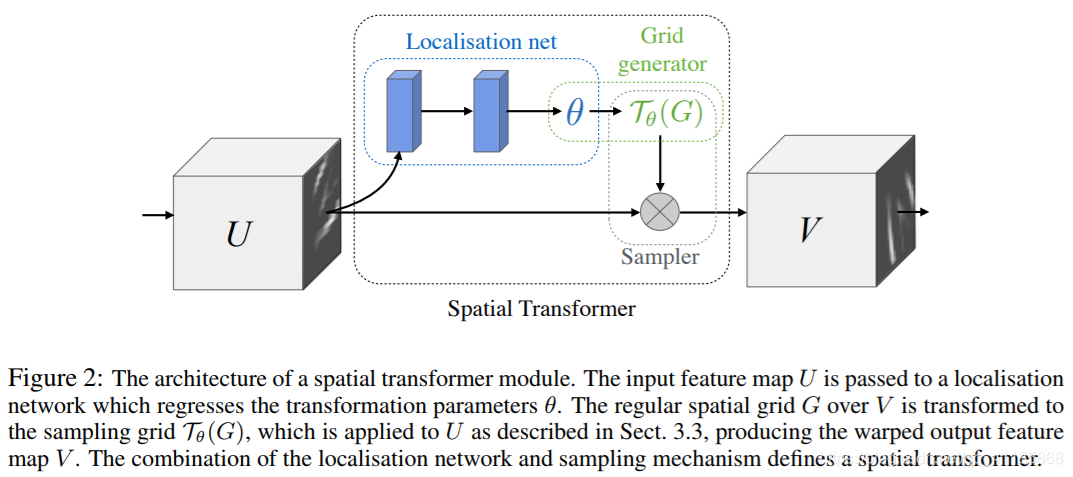
Figure 2: The architecture of a spatial transformer module. The input feature map U is passed to a localisation network which regresses the transformation parameters θ. The regular spatial grid G over V is transformed to the sampling grid Tθ(G), which is applied to U as described in Sect. 3.3, producing the warped output feature map V . The combination of the localisation network and sampling mechanism defines a spatial transformer. |
图2:空间变压器模块的架构。输入特征映射U被传递到一个定位网络,该网络回归转换参数θ。将规则空间网格G / V转换为采样网格Tθ(G),如3.3节所述,将采样网格应用于U,产生扭曲的输出特征映射V。定位网络和抽样机制的结合定义了一个空间转换器。 |
| Neural networks with selective attention manipulate the data by taking crops, and so are able to learn translation invariance. Work such as [1, 29] are trained with reinforcement learning to avoid the need for a differentiable attention mechanism, while [14] use a differentiable attention mechansim by utilising Gaussian kernels in a generative model. The work by Girshick et al. [11] uses a region proposal algorithm as a form of attention, and [7] show that it is possible to regress salient regions with a CNN. The framework we present in this paper can be seen as a generalisation of differentiable attention to any spatial transformation. | 具有选择性注意的神经网络通过获取作物来操纵数据,因此能够学习翻译不变性。像[1,29]这样的工作通过强化学习进行训练,以避免对可微分注意机制的需要,而[14]通过在生成模型中使用高斯核函数来使用可微分注意机制。Girshick等人的研究[11]使用区域建议算法作为注意的一种形式,[7]表明可以使用CNN回归显著区域。我们在本文中提出的框架可以看作是对任何空间变换的可微注意的推广。 |
3 Spatial Transformers
| In this section we describe the formulation of a spatial transformer. This is a differentiable module which applies a spatial transformation to a feature map during a single forward pass, where the transformation is conditioned on the particular input, producing a single output feature map. For multi-channel inputs, the same warping is applied to each channel. For simplicity, in this section we consider single transforms and single outputs per transformer, however we can generalise to multiple transformations, as shown in experiments. | 在本节中,我们将描述空间转换器的公式。这是一个可微模块,它在一个单独的前向过程中对特征映射进行空间变换,其中的变换以特定的输入为条件,产生一个单独的输出特征映射。对于多通道输入,对每个通道应用相同的翘曲。为简单起见,在本节中,我们考虑每个变压器的单一转换和单一输出,然而,我们可以推广到多个转换,如实验中所示。 |
| The spatial transformer mechanism is split into three parts, shown in Fig. 2. In order of computation, first a localisation network (Sect. 3.1) takes the input feature map, and through a number of hidden layers outputs the parameters of the spatial transformation that should be applied to the feature map – this gives a transformation conditional on the input. Then, the predicted transformation parameters are used to create a sampling grid, which is a set of points where the input map should be sampled to produce the transformed output. This is done by the grid generator, described in Sect. 3.2. Finally, the feature map and the sampling grid are taken as inputs to the sampler, producing the output map sampled from the input at the grid points (Sect. 3.3). The combination of these three components forms a spatial transformer and will now be described in more detail in the following sections. |
空间变换机构分为三部分,如图2所示。按照计算顺序,首先定位网络(第3.1节)获取输入特征地图,并通过若干隐藏层输出应该应用于特征地图的空间转换参数——这将在输入上给出一个有条件的转换。然后,使用预测的转换参数来创建一个采样网格,该网格是一组应该对输入映射进行采样以产生转换后的输出的点。这是由第3.2节中描述的网格生成器完成的。最后,将特征映射和采样网格作为采样器的输入,从网格点的输入产生采样的输出映射(第3.3节)。这三个组件的组合形成了一个空间转换器,下面几节将对其进行更详细的描述。 |
3.1 Localisation Network
| The localisation network takes the input feature map U ∈ R H×W×C with width W, height H and C channels and outputs θ, the parameters of the transformation Tθ to be applied to the feature map: θ = floc(U). The size of θ can vary depending on the transformation type that is parameterised, e.g. for an affine transformation θ is 6-dimensional as in (10). The localisation network function floc() can take any form, such as a fully-connected network or a convolutional network, but should include a final regression layer to produce the transformation parameters θ. | 定位网络取输入特征图U∈R H×W×C,宽W,高H, C通道,输出θ,应用于特征图的变换Tθ的参数:θ = floc(U)。θ的大小可以根据参数化的转换类型而变化,例如。对于仿射变换,θ是6维的,如(10)。定位网络函数floc()可以采取任何形式,例如完全连接的网络或卷积网络,但应该包括一个最终的回归层来产生转换参数θ。 |
3.2 Parameterised Sampling Grid
| To perform a warping of the input feature map, each output pixel is computed by applying a sampling kernel centered at a particular location in the input feature map (this is described fully in the next section). By pixel we refer to an element of a generic feature map, not necessarily an image. In general, the output pixels are defined to lie on a regular grid G = {Gi} of pixels Gi = (x t i , yt i ), forming an output feature map V ∈ R H0×W0×C , where H0 and W0 are the height and width of the grid, and C is the number of channels, which is the same in the input and output. | 要对输入特征映射执行扭曲,需要通过应用以输入特征映射中特定位置为中心的采样核来计算每个输出像素(下一节将对此进行详细描述)。像素指的是一般特征图的一个元素,不一定是图像。一般来说,躺在一个常规定义的输出像素网格G = {Gi}像素Gi = (x t,欧美我),形成一个输出特性映射V∈R H0×W0×C, H0和W0网格的高度和宽度,和C是通道的数量,输入和输出是相同的。 |
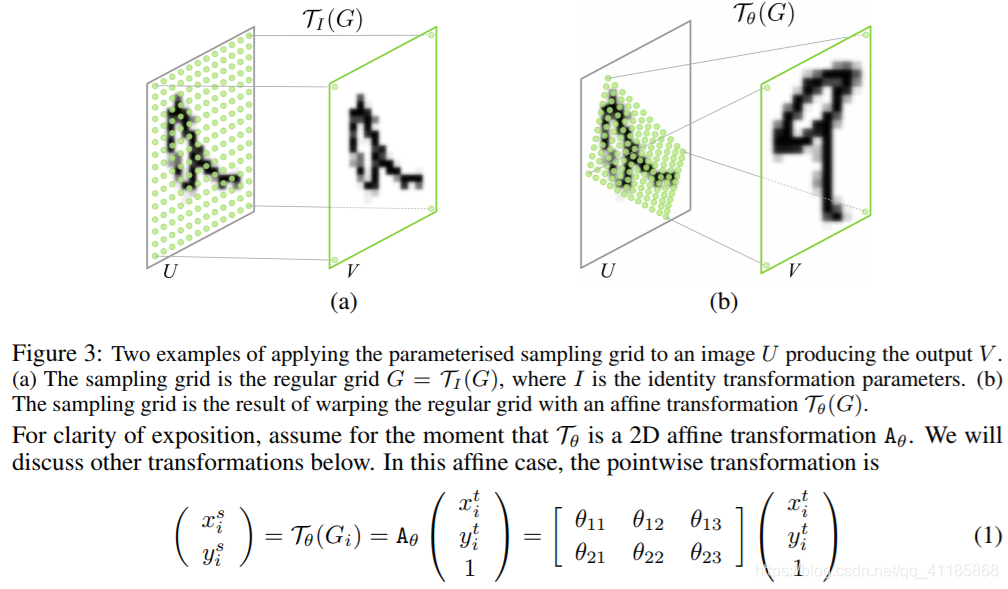
where (x t i , yt i ) are the target coordinates of the regular grid in the output feature map, (x s i , ys i ) are the source coordinates in the input feature map that define the sample points, and Aθ is the affine transformation matrix. We use height and width normalised coordinates, such that −1 ≤ x t i , yt i ≤ 1 when within the spatial bounds of the output, and −1 ≤ x s i , ys i ≤ 1 when within the spatial bounds of the input (and similarly for the y coordinates). The source/target transformation and sampling is equivalent to the standard texture mapping and coordinates used in graphics [8]. |
其中(x ti, yt i)为输出特征映射中规则网格的目标坐标,(x s i, ys i)为定义样本点的输入特征映射中的源坐标,Aθ为仿射变换矩阵。我们使用的高度和宽度正常化坐标,这样−1≤x t我次我≤1时在空间范围内的输出,和−1≤x, y≤1时在空间范围内的输入(同样的y坐标)。源/目标转换和采样等价于图形[8]中使用的标准纹理映射和坐标。 |
The class of transformations Tθ may be more constrained, such as that used for attention Aθ = s 0 tx 0 s ty (2) allowing cropping, translation, and isotropic scaling by varying s, tx, and ty. The transformation Tθ can also be more general, such as a plane projective transformation with 8 parameters, piecewise affine, or a thin plate spline. Indeed, the transformation can have any parameterised form, provided that it is differentiable with respect to the parameters – this crucially allows gradients to be backpropagated through from the sample points Tθ(Gi) to the localisation network output θ. If the transformation is parameterised in a structured, low-dimensional way, this reduces the complexity of the task assigned to the localisation network. For instance, a generic class of structured and differentiable transformations, which is a superset of attention, affine, projective, and thin plate spline transformations, is Tθ = MθB, where B is a target grid representation (e.g. in (10), B is the regular grid G in homogeneous coordinates), and Mθ is a matrix parameterised by θ. In this case it is possible to not only learn how to predict θ for a sample, but also to learn B for the task at hand. |
类的转换Tθ可能更多限制,比如用于注意θ= 0 0 tx泰(2)允许裁剪,翻译,和各向同性缩放到不同年代,tx,泰,变换Tθ也可以更普遍,如使用8参数平面射影变换,分段仿射或薄板样条。事实上,变换可以有任何参数化形式,只要它对参数是可微的——这至关重要地允许梯度通过样本点Tθ(Gi)反向传播到定位网络输出θ。如果转换以结构化、低维的方式参数化,这将降低分配给本地化网络的任务的复杂性。例如,一个泛型类的结构化和可微的转换,这是一个超集的关注,仿射,投影,和薄板样条转换,是M Tθ=θB, B是一个目标网格表示(例如在(10),B是定期在齐次坐标网格G),和Mθ是一个矩阵parameterisedθ。在这种情况下,不仅可以学习如何预测样本的θ,而且可以学习当前任务的B。 |

3.3 Differentiable Image Sampling
To perform a spatial transformation of the input feature map, a sampler must take the set of sampling points Tθ(G), along with the input feature map U and produce the sampled output feature map V . Each (x s i , ys i ) coordinate in Tθ(G) defines the spatial location in the input where a sampling kernel is applied to get the value at a particular pixel in the output V . This can be written as
|
为了对输入特征映射进行空间变换,采样器必须取采样点集Tθ(G),同时取输入特征映射U,并产生采样输出特征映射V。Tθ(G)中的每个(x s i, ys i)坐标定义了输入中的空间位置,采样核应用于此,以获得输出V中特定像素的值。这可以写成 |
where Φx and Φy are the parameters of a generic sampling kernel k() which defines the image interpolation (e.g. bilinear), U c nm is the value at location (n, m) in channel c of the input, and V c i is the output value for pixel i at location (x t i , yt i ) in channel c. Note that the sampling is done identically for each channel of the input, so every channel is transformed in an identical way (this preserves spatial consistency between channels). In theory, any sampling kernel can be used, as long as (sub-)gradients can be defined with respect to x s i and y s i . For example, using the integer sampling kernel reduces (3) to V c i = X H n X W m U c nmδ(bx s i + 0.5c − m)δ(by s i + 0.5c − n) (4) where bx + 0.5c rounds x to the nearest integer and δ() is the Kronecker delta function. This sampling kernel equates to just copying the value at the nearest pixel to (x s i , ys i ) to the output location (x t i , yt i ). Alternatively, a bilinear sampling kernel can be used, giving V c i = X H n X W m U c nm max(0, 1 − |x s i − m|) max(0, 1 − |y s i − n|) (5) To allow backpropagation of the loss through this sampling mechanism we can define the gradients with respect to U and G. For bilinear sampling (5) the partial derivatives are ∂V c i ∂Uc nm = X H n X W m max(0, 1 − |x s i − m|) max(0, 1 − |y s i − n|) (6) ∂V c i ∂xs i = X H n X W m U c nm max(0, 1 − |y s i − n|) 0 if |m − x s i | ≥ 1 1 if m ≥ x s i −1 if m < xs i (7) and similarly to (7) for ∂V c i ∂ys i . |
|
| This gives us a (sub-)differentiable sampling mechanism, allowing loss gradients to flow back not only to the input feature map (6), but also to the sampling grid coordinates (7), and therefore back to the transformation parameters θ and localisation network since ∂xs i ∂θ and ∂xs i ∂θ can be easily derived from (10) for example. Due to discontinuities in the sampling fuctions, sub-gradients must be used. This sampling mechanism can be implemented very efficiently on GPU, by ignoring the sum over all input locations and instead just looking at the kernel support region for each output pixel. | 这给了我们一个(子)可微的采样机制,不仅允许损失梯度回流的输入特性图(6),而且采样网格坐标(7),因此回转换参数θ和本地化网络自∂x我∂θ和∂x我∂θ可以很容易地由(10)为例。由于抽样函数的不连续,必须使用次梯度。这种采样机制可以在GPU上非常有效地实现,忽略所有输入位置的总和,而只是查看每个输出像素的内核支持区域。 |


3.4 Spatial Transformer Networks
| The combination of the localisation network, grid generator, and sampler form a spatial transformer (Fig. 2). This is a self-contained module which can be dropped into a CNN architecture at any point, and in any number, giving rise to spatial transformer networks. This module is computationally very fast and does not impair the training speed, causing very little time overhead when used naively, and even speedups in attentive models due to subsequent downsampling that can be applied to the output of the transformer. Placing spatial transformers within a CNN allows the network to learn how to actively transform the feature maps to help minimise the overall cost function of the network during training. The knowledge of how to transform each training sample is compressed and cached in the weights of the localisation network (and also the weights of the layers previous to a spatial transformer) during training. For some tasks, it may also be useful to feed the output of the localisation network, θ, forward to the rest of the network, as it explicitly encodes the transformation, and hence the pose, of a region or object. |
定位网络、网格发生器和采样器的组合形成了一个空间变压器(图。2).这是一个自包含的模块,可以在任意点,任意数量的放入CNN架构中,从而产生空间变压器网络。该模块的计算速度非常快,不影响训练速度,在天真地使用时造成的时间开销非常小,甚至在细心的模型中加速,因为后续的下采样可以应用到变压器的输出。在CNN中放置空间变压器可以让网络学习如何积极地转换特征图,以帮助在训练期间最小化网络的总体成本函数。在训练期间,如何转换每个训练样本的知识被压缩并缓存在本地化网络的权值中(以及空间转换器之前的层的权值)。对于某些任务,它也可能是有用的供给定位网络的输出,θ,向前到网络的其余部分,因为它明确编码转换,因此姿态,一个区域或对象。 |
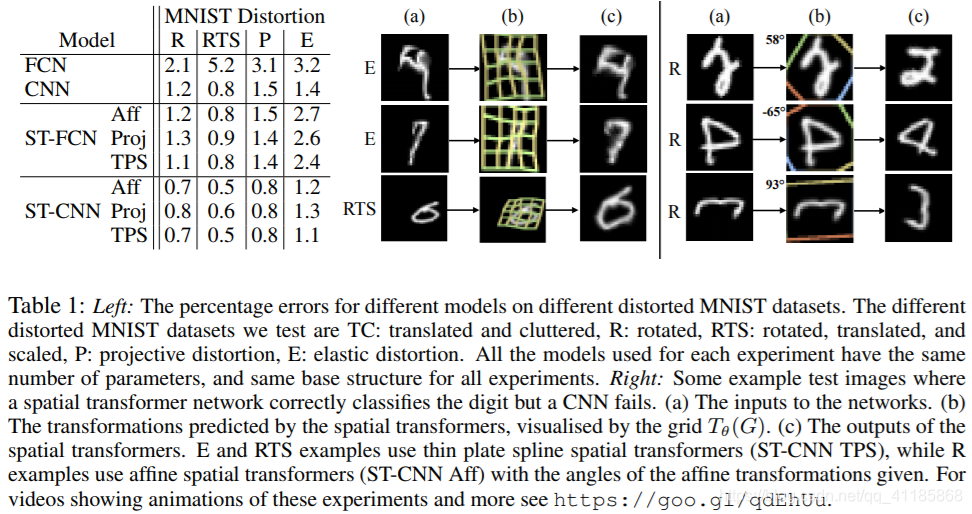
Table 1: Left: The percentage errors for different models on different distorted MNIST datasets. The different distorted MNIST datasets we test are TC: translated and cluttered, R: rotated, RTS: rotated, translated, and scaled, P: projective distortion, E: elastic distortion. All the models used for each experiment have the same number of parameters, and same base structure for all experiments. Right: Some example test images where a spatial transformer network correctly classifies the digit but a CNN fails. (a) The inputs to the networks. (b) The transformations predicted by the spatial transformers, visualised by the grid Tθ(G). (c) The outputs of the spatial transformers. E and RTS examples use thin plate spline spatial transformers (ST-CNN TPS), while R examples use affine spatial transformers (ST-CNN Aff) with the angles of the affine transformations given. For videos showing animations of these experiments and more see https://goo.gl/qdEhUu. |
表1:左:不同模型在不同失真MNIST数据集上的误差百分比。我们测试的不同扭曲MNIST数据集是TC:平移和杂波,R:旋转,RTS:旋转,平移和缩放,P:投影失真,E:弹性失真。各实验所用模型参数数目相同,基本结构相同。右图:一些测试图像的例子,其中空间变压器网络正确地分类数字,但CNN失败了。(a)网络的输入。(b)空间变压器预测的变换,由网格Tθ(G)可视化。(c)空间变压器的输出。E和RTS的例子使用薄板样条空间变压器(ST-CNN TPS),而R的例子使用仿射空间变压器(ST-CNN Aff),其仿射变换的角度是给定的。有关这些实验动画的视频和更多内容,请参见https://goo.gl/qdEhUu。 |
| It is also possible to use spatial transformers to downsample or oversample a feature map, as one can define the output dimensions H0 and W0 to be different to the input dimensions H and W. However, with sampling kernels with a fixed, small spatial support (such as the bilinear kernel), downsampling with a spatial transformer can cause aliasing effects. Finally, it is possible to have multiple spatial transformers in a CNN. Placing multiple spatial transformers at increasing depths of a network allow transformations of increasingly abstract representations, and also gives the localisation networks potentially more informative representations to base the predicted transformation parameters on. One can also use multiple spatial transformers in parallel – this can be useful if there are multiple objects or parts of interest in a feature map that should be focussed on individually. A limitation of this architecture in a purely feed-forward network is that the number of parallel spatial transformers limits the number of objects that the network can model. |
还可以使用空间变形金刚downsample或oversample功能地图,作为一个可以定义的输出尺寸H0和W0不同输入维度H和w .然而,与一个固定的采样内核,小空间(如双线性内核)的支持,将采样空间变压器可能导致混叠效应。最后,在一个CNN中可以有多个空间变压器。在网络的深度增加时放置多个空间转换器,可以实现越来越抽象的表示形式的转换,同时也为定位网络提供了潜在的更有信息的表示形式,从而可以根据预测的转换参数进行转换。还可以同时使用多个空间转换器——如果在一个特征图中有多个对象或感兴趣的部分需要分别关注,这可能会很有用。在纯前馈网络中,这种架构的一个限制是并行空间变压器的数量限制了网络可以建模的对象的数量。 |
4 Experiments
| In this section we explore the use of spatial transformer networks on a number of supervised learning tasks. In Sect. 4.1 we begin with experiments on distorted versions of the MNIST handwriting dataset, showing the ability of spatial transformers to improve classification performance through actively transforming the input images. In Sect. 4.2 we test spatial transformer networks on a challenging real-world dataset, Street View House Numbers [25], for number recognition, showing stateof-the-art results using multiple spatial transformers embedded in the convolutional stack of a CNN. Finally, in Sect. 4.3, we investigate the use of multiple parallel spatial transformers for fine-grained classification, showing state-of-the-art performance on CUB-200-2011 birds dataset [38] by discovering object parts and learning to attend to them. Further experiments of MNIST addition and co-localisation can be found in Appendix A. | 在本节中,我们将探索空间变压器网络在若干监督学习任务中的使用。在4.1节中,我们首先对MNIST笔迹数据集的扭曲版本进行实验,展示了空间变换器通过主动转换输入图像来提高分类性能的能力。在第4.2节中,我们在具有挑战性的真实世界数据集上测试了空间变压器网络,街道视图房号[25],用于数字识别,使用嵌入在CNN卷积堆栈中的多个空间变压器显示了最先进的结果。最后,在第4.3节中,我们研究了多个并行空间变形器用于细粒度分类的使用,通过发现对象部件并学习注意它们,展示了cube -200-2011 birds数据集[38]的最先进性能。进一步的MNIST添加和共定位实验可以在附录A中找到。 |
4.1 Distorted MNIST
In this section we use the MNIST handwriting dataset as a testbed for exploring the range of transformations to which a network can learn invariance to by using a spatial transformer. We begin with experiments where we train different neural network models to classify MNIST data that has been distorted in various ways: rotation (R), rotation, scale and translation (RTS), projective transformation (P), and elastic warping (E) – note that elastic warping is destructive and can not be inverted in some cases. The full details of the distortions used to generate this data are given in Appendix A. We train baseline fully-connected (FCN) and convolutional (CNN) neural networks, as well as networks with spatial transformers acting on the input before the classification network (ST-FCN and ST-CNN). The spatial transformer networks all use bilinear sampling, but variants use different transformation functions: an affine transformation (Aff), projective transformation (Proj), and a 16-point thin plate spline transformation (TPS) [2]. The CNN models include two max-pooling layers. All networks have approximately the same number of parameters, are trained with identical optimisation schemes (backpropagation, SGD, scheduled learning rate decrease, with a multinomial cross entropy loss), and all with three weight layers in the classification network. |
在本节中,我们使用MNIST手写数据集作为测试平台,来探索网络可以通过使用空间转换器学习到的不变性的转换范围。我们从实验开始训练不同的神经网络模型分类MNIST数据已经以各种方式扭曲:旋转(R)、旋转、尺度和翻译(RTS)、投影转换(P)和弹性变形(E) -注意,弹性变形是毁灭性的和在某些情况下不能倒。用于生成这一数据的扭曲的全部细节见附录a。我们训练基线全连接(FCN)和卷积(CNN)神经网络,以及在分类网络(ST-FCN和ST-CNN)之前使用空间变压器作用于输入的网络。空间变压器网络都使用双线性采样,但不同的变体使用不同的变换函数:仿射变换(Aff)、投影变换(Proj)和16点薄板样条变换(TPS)[2]。CNN的模型包括两个最大汇集层。所有的网络具有近似相同的参数数目,使用相同的优化方案(backpropagation, SGD,调度学习速率下降,有多项交叉熵损失)进行训练,并且在分类网络中都有三个权层。 |
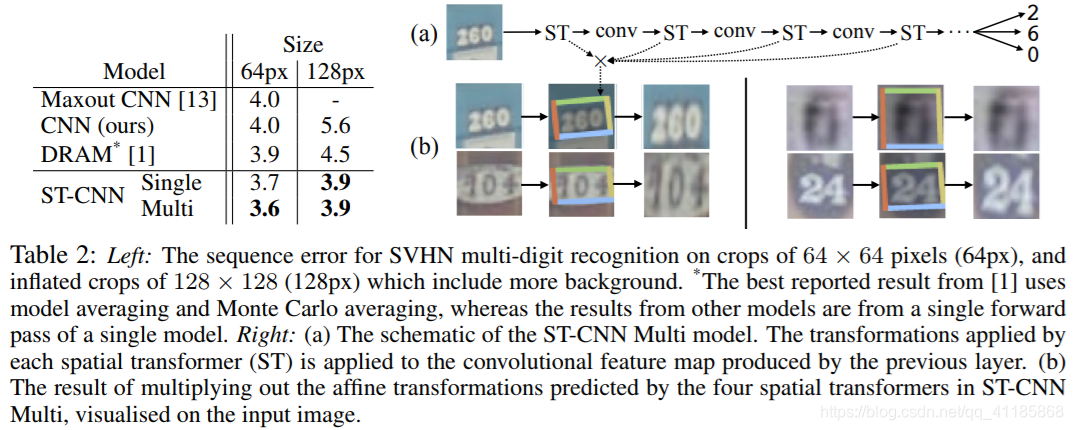
Table 2: Left: The sequence error for SVHN multi-digit recognition on crops of 64 × 64 pixels (64px), and inflated crops of 128 × 128 (128px) which include more background. *The best reported result from [1] uses model averaging and Monte Carlo averaging, whereas the results from other models are from a single forward pass of a single model. Right: (a) The schematic of the ST-CNN Multi model. The transformations applied by each spatial transformer (ST) is applied to the convolutional feature map produced by the previous layer. (b) The result of multiplying out the affine transformations predicted by the four spatial transformers in ST-CNN Multi, visualised on the input image. |
表2:左:64 × 64像素(64px)作物的SVHN多位数识别序列错误,128 × 128 (128px)膨大的作物包含更多的背景。*[1]报告的最佳结果使用了模型平均和蒙特卡罗平均,而其他模型的结果来自单个模型的单次向前传递。右:(a) ST-CNN多模型示意图。每个空间变换器(ST)的变换应用于前一层生成的卷积特征图。(b)将ST-CNN Multi中的四个空间变压器预测的仿射变换乘出来的结果,在输入图像上显示出来。 |
| The results of these experiments are shown in Table 1 (left). Looking at any particular type of distortion of the data, it is clear that a spatial transformer enabled network outperforms its counterpart base network. For the case of rotation, translation, and scale distortion (RTS), the ST-CNN achieves 0.5% and 0.6% depending on the class of transform used for Tθ, whereas a CNN, with two maxpooling layers to provide spatial invariance, achieves 0.8% error. This is in fact the same error that the ST-FCN achieves, which is without a single convolution or max-pooling layer in its network, showing that using a spatial transformer is an alternative way to achieve spatial invariance. ST-CNN models consistently perform better than ST-FCN models due to max-pooling layers in ST-CNN providing even more spatial invariance, and convolutional layers better modelling local structure. We also test our models in a noisy environment, on 60 × 60 images with translated MNIST digits and background clutter (see Fig. 1 third row for an example): an FCN gets 13.2% error, a CNN gets 3.5% error, while an ST-FCN gets 2.0% error and an ST-CNN gets 1.7% error. Looking at the results between different classes of transformation, the thin plate spline transformation (TPS) is the most powerful, being able to reduce error on elastically deformed digits by reshaping the input into a prototype instance of the digit, reducing the complexity of the task for the classification network, and does not over fit on simpler data e.g. R. Interestingly, the transformation of inputs for all ST models leads to a “standard” upright posed digit – this is the mean pose found in the training data. In Table 1 (right), we show the transformations performed for some test cases where a CNN is unable to correctly classify the digit, but a spatial transformer network can. Further test examples are visualised in an animation here https://goo.gl/qdEhUu. |
实验结果见表1(左)。观察任何特定类型的数据失真,可以清楚地看出空间转换器支持的网络性能优于其对应的基础网络。在旋转、平移和尺度失真(RTS)的情况下,ST-CNN根据用于Tθ的变换类别达到0.5%和0.6%,而使用两个maxpooling层来提供空间不变性的CNN达到0.8%的误差。这实际上与ST-FCN实现的错误相同,ST-FCN在其网络中没有单一的卷积或最大池化层,这表明使用空间转换器是实现空间不变性的另一种方法。ST-CNN模型的性能始终优于ST-FCN模型,因为ST-CNN中的max-pooling层提供了更多的空间不变性,卷积层更好地建模局部结构。我们也测试模型在一个嘈杂的环境中,在60×60与翻译MNIST数字图像和背景杂波(见图1第三行为例):一个FCN得到13.2%的误差,CNN获得3.5%的误差,而ST-FCN得到2.0%的误差和ST-CNN得到1.7%的错误。 观察结果之间的不同类型的转换,薄板样条转换(TPS)是最强大的,能够减少错误弹性变形数字通过重塑输入数字的一个原型实例,减少任务分类网络的复杂性,且不适合在简单的数据,比如r .有趣的是,对所有ST模型的输入进行转换,得到一个“标准”的直立姿势数字——这是在训练数据中发现的平均姿势。在表1(右)中,我们展示了在一些测试用例中执行的转换,其中CNN不能正确地分类数字,但空间转换器网络可以。更多的测试示例可以在一个动画中看到https://goo.gl/qdEhUu。 |
4.2 Street View House Numbers
| We now test our spatial transformer networks on a challenging real-world dataset, Street View House Numbers (SVHN) [25]. This dataset contains around 200k real world images of house numbers, with the task to recognise the sequence of numbers in each image. There are between 1 and 5 digits in each image, with a large variability in scale and spatial arrangement. We follow the experimental setup as in [1, 13], where the data is preprocessed by taking 64 × 64 crops around each digit sequence. We also use an additional more loosely 128×128 cropped dataset as in [1]. We train a baseline character sequence CNN model with 11 hidden layers leading to five independent softmax classifiers, each one predicting the digit at a particular position in the sequence. This is the character sequence model used in [19], where each classifier includes a null-character output to model variable length sequences. This model matches the results obtained in [13]. |
我们现在在一个具有挑战性的真实世界数据集上测试我们的空间转换器网络,街景房屋号码(SVHN)[25]。该数据集包含约20万张真实世界的门牌号图像,任务是识别每张图像中的数字序列。每张图像的数字在1 - 5位之间,在尺度和空间安排上有很大的变异性。我们遵循[1,13]中的实验设置,在每个数字序列周围取64 × 64个作物对数据进行预处理。我们还使用另一个更松散的128×128裁切数据集,如[1]中所示。我们训练了一个基线字符序列CNN模型,该模型有11个隐藏层,形成5个独立的softmax分类器,每个分类器预测序列中特定位置的数字。这是[19]中使用的字符序列模型,其中每个分类器都包含一个空字符输出来为可变长度序列建模。该模型与[13]得到的结果相匹配。 |
| We extend this baseline CNN to include a spatial transformer immediately following the input (STCNN Single), where the localisation network is a four-layer CNN. We also define another extension where before each of the first four convolutional layers of the baseline CNN, we insert a spatial transformer (ST-CNN Multi), where the localisation networks are all two layer fully connected networks with 32 units per layer. In the ST-CNN Multi model, the spatial transformer before the first convolutional layer acts on the input image as with the previous experiments, however the subsequent spatial transformers deeper in the network act on the convolutional feature maps, predicting a transformation from them and transforming these feature maps (this is visualised in Table 2 (right) (a)). This allows deeper spatial transformers to predict a transformation based on richer features rather than the raw image. All networks are trained from scratch with SGD and dropout [17], with randomly initialised weights, except for the regression layers of spatial transformers which are initialised to predict the identity transform. Affine transformations and bilinear sampling kernels are used for all spatial transformer networks in these experiments. | 我们扩展了这个基线CNN,包括一个紧跟输入的空间转换器(STCNN单),其中定位网络是一个四层的CNN。我们还定义了另一个扩展,在基线CNN的前四个卷积层之前,我们插入一个空间转换器(ST-CNN Multi),其中定位网络都是两层完全连接的网络,每层有32个单元。ST-CNN多模型、空间变压器之前第一个卷积层作用于输入图像与之前的实验一样,然而随后在回旋的空间变形金刚更深层次的网络行为特征图,预测一个转换和转换这些特征图(这是呈现在表2(右)(a))。这使得更深层的空间变换器能够根据更丰富的特征而不是原始图像来预测变换。除了空间变换的回归层被初始化以预测身份变换外,所有网络都用SGD和dropout[17]从零开始训练,并随机初始化权值。在这些实验中,所有的空间变压器网络都采用了仿射变换和双线性采样核。 |
Table 3: Left: The accuracy on CUB-200-2011 bird classification dataset. Spatial transformer networks with two spatial transformers (2×ST-CNN) and four spatial transformers (4×ST-CNN) in parallel achieve higher accuracy. 448px resolution images can be used with the ST-CNN without an increase in computational cost due to downsampling to 224px after the transformers. Right: The transformation predicted by the spatial transformers of 2×ST-CNN (top row) and 4×ST-CNN (bottom row) on the input image. Notably for the 2×ST-CNN, one of the transformers (shown in red) learns to detect heads, while the other (shown in green) detects the body, and similarly for the 4×ST-CNN. |
表3:左:CUB-200-2011鸟类分类数据集的精度。两个空间变压器(2×ST-CNN)和四个空间变压器(4×ST-CNN)并行的空间变压器网络可以实现更高的精度。448px分辨率的图像可以与ST-CNN一起使用,而无需增加计算成本,因为经过变压器后降采样到224px。右:空间变换2×ST-CNN(上一行)和4×ST-CNN(下一行)在输入图像上预测的变换。值得注意的是2×ST-CNN,其中一个变形金刚(红色显示)学习检测头部,而另一个(绿色显示)检测身体,4×ST-CNN也是如此。 |
| The results of this experiment are shown in Table 2 (left) – the spatial transformer models obtain state-of-the-art results, reaching 3.6% error on 64×64 images compared to previous state-of-the-art of 3.9% error. Interestingly on 128 × 128 images, while other methods degrade in performance, an ST-CNN achieves 3.9% error while the previous state of the art at 4.5% error is with a recurrent attention model that uses an ensemble of models with Monte Carlo averaging – in contrast the STCNN models require only a single forward pass of a single model. This accuracy is achieved due to the fact that the spatial transformers crop and rescale the parts of the feature maps that correspond to the digit, focussing resolution and network capacity only on these areas (see Table 2 (right) (b) for some examples). In terms of computation speed, the ST-CNN Multi model is only 6% slower (forward and backward pass) than the CNN. | 本实验的结果如表2(左)所示,空间转换器模型获得了最先进的结果,在64×64图像上的误差达到3.6%,而之前的最先进的误差为3.9%。有趣的是在128×128的图片,而其他方法降解性能,ST-CNN达到3.9%错误在之前的4.5%的误差是复发性注意力模型,它使用一个模型与蒙特卡罗平均——相比之下STCNN模型只需要一个传球前进的一个模型。之所以能达到这样的精度,是因为空间变换器只在这些区域对与数字对应的特征地图部分进行裁剪和缩放,集中分辨率和网络容量(一些例子见表2(右)(b))。在计算速度方面,ST-CNN Multi model仅比CNN慢6%(前向和后向传递)。 |

4.3 Fine-Grained Classification
| In this section, we use a spatial transformer network with multiple transformers in parallel to perform fine-grained bird classification. We evaluate our models on the CUB-200-2011 birds dataset [38], containing 6k training images and 5.8k test images, covering 200 species of birds. The birds appear at a range of scales and orientations, are not tightly cropped, and require detailed texture and shape analysis to distinguish. In our experiments, we only use image class labels for training. We consider a strong baseline CNN model – an Inception architecture with batch normalisation [18] pre-trained on ImageNet [26] and fine-tuned on CUB – which by itself achieves the state-of-theart accuracy of 82.3% (previous best result is 81.0% [30]). We then train a spatial transformer network, ST-CNN, which contains 2 or 4 parallel spatial transformers, parameterised for attention and acting on the input image. Discriminative image parts, captured by the transformers, are passed to the part description sub-nets (each of which is also initialised by Inception). The resulting part representations are concatenated and classified with a single softmax layer. The whole architecture is trained on image class labels end-to-end with backpropagation (full details in Appendix A). |
在本节中,我们使用一个并行地包含多个变压器的空间变压器网络来执行细粒度的鸟分类。我们在CUB-200-2011鸟类数据集[38]上评估我们的模型,该数据集包含6k的训练图像和5.8k的测试图像,涵盖200种鸟类。这些鸟出现在不同的尺度和方向上,没有被紧密裁剪,需要详细的纹理和形状分析来区分。在我们的实验中,我们只使用图像类标签进行训练。我们认为一个强大的基线CNN模型——一个在ImageNet[26]上预先训练并在CUB上进行调整的带有批处理标准化[18]的初始架构——它本身就达到了最先进的82.3%的精度(之前最好的结果是81.0%[30])。然后我们训练一个空间变压器网络ST-CNN,它包含2或4个平行的空间变压器,参数化的注意力和作用于输入图像。由变形金刚捕获的鉴别图像部件被传递到部件描述子网(每个子网也在Inception时初始化)。产生的部件表示用一个单一的softmax层连接和分类。整个体系结构是用图像类标签端到端的反向传播进行训练的(详细信息见附录A)。 |
| The results are shown in Table 3 (left). The ST-CNN achieves an accuracy of 84.1%, outperforming the baseline by 1.8%. It should be noted that there is a small (22/5794) overlap between the ImageNet training set and CUB-200-2011 test set1 – removing these images from the test set results in 84.0% accuracy with the same ST-CNN. In the visualisations of the transforms predicted by 2×STCNN (Table 3 (right)) one can see interesting behaviour has been learnt: one spatial transformer (red) has learnt to become a head detector, while the other (green) fixates on the central part of the body of a bird. The resulting output from the spatial transformers for the classification network is a somewhat pose-normalised representation of a bird. While previous work such as [3] explicitly define parts of the bird, training separate detectors for these parts with supplied keypoint training data, the ST-CNN is able to discover and learn part detectors in a data-driven manner without any additional supervision. In addition, the use of spatial transformers allows us to use 448px resolution input images without any impact in performance, as the output of the transformed 448px images are downsampled to 224px before being processed. | 结果见表3(左)。ST-CNN的准确率达到了84.1%,比基准高出1.8%。需要注意的是,ImageNet训练集和CUB-200-2011测试集1之间有一个小的(22/5794)重叠——在ST-CNN相同的情况下,从测试集中去除这些图像的准确率为84.0%。从2×STCNN(表3(右))预测的变换的可视化图中,我们可以看到人们学会了一些有趣的行为:一个空间变形器(红色)学会了成为头部探测器,而另一个(绿色)则专注于鸟的身体中央部分。从空间变压器的结果输出的分类网络是一个姿态归一化的鸟类表示。虽然之前的工作,如[3]明确地定义了鸟的部分,训练这些部分的单独的检测器与提供的关键训练数据,ST-CNN能够以数据驱动的方式发现和学习部分检测器,而不需要任何额外的监督。此外,空间转换器的使用允许我们在不影响性能的情况下使用448px分辨率的输入图像,因为转换后的448px图像的输出在处理之前会被向下采样到224px。 |
5 Conclusion
| In this paper we introduced a new self-contained module for neural networks – the spatial transformer. This module can be dropped into a network and perform explicit spatial transformations of features, opening up new ways for neural networks to model data, and is learnt in an end-toend fashion, without making any changes to the loss function. While CNNs provide an incredibly strong baseline, we see gains in accuracy using spatial transformers across multiple tasks, resulting in state-of-the-art performance. Furthermore, the regressed transformation parameters from the spatial transformer are available as an output and could be used for subsequent tasks. While we only explore feed-forward networks in this work, early experiments show spatial transformers to be powerful in recurrent models, and useful for tasks requiring the disentangling of object reference frames, as well as easily extendable to 3D transformations (see Appendix A.3). | 本文介绍了一种新的神经网络自包含模块——空间变压器。该模块可以放入网络中,对特征进行显式的空间转换,为神经网络建模数据开辟了新途径,并且可以在不改变损失函数的情况下以端到端方式学习。虽然cnn提供了一个令人难以置信的强大基线,但我们看到在多个任务中使用空间转换器的准确性有所提高,从而产生了最先进的性能。此外,从空间转换器返回的转换参数可作为输出,并可用于后续任务。虽然我们在这项工作中只探索了前馈网络,但早期的实验表明,空间转换器在循环模型中非常强大,对于需要解离对象参考框架的任务非常有用,而且很容易扩展到3D转换(见附录A.3)。 |


