
数据获取

以鸢尾数据为例,首先加载数据集。
from sklearn.datasets import load_iris
dataset = load_iris()
# print(dataset)
X = dataset.data
y = dataset.target
可以下查看下数据基本特征
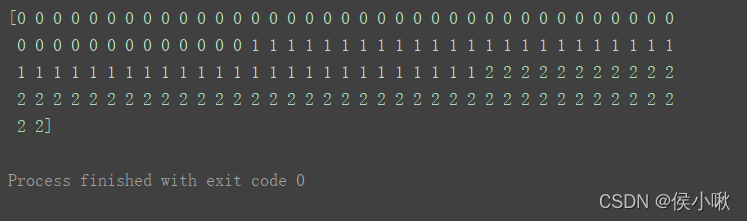
print(X)

print(y)
①归一化 MinMaxScaler
1.1默认调用
from sklearn.preprocessing import MinMaxScaler
X_transformed = MinMaxScaler().fit_transform(X)
print(X_transformed)
程序执行结果: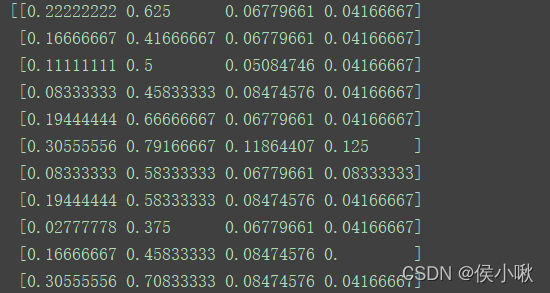
1.2了解相关属性/参数
实例化MinMaxScaler()时可传入相关属性
MinMaxScaler(self, feature_range=(0, 1), *, copy=True, clip=False)
- feature_range默认为元组(0,1),表示特征值范围
- copy默认为True,表示不改变原X,该为False后原X被改变。
- clip不知道是啥属性,一般应该也用不上,知道的大佬可以在评论区补充。
示例
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler(feature_range=(0, 0.5), copy=False).fit_transform(X)
print(X)
程序执行结果: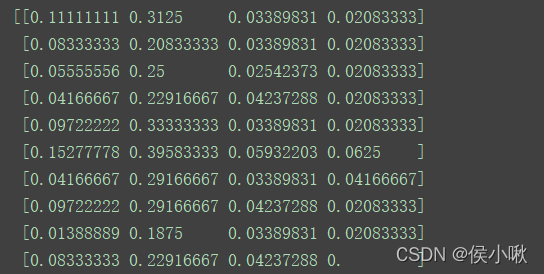
②正则化 Normalizer
2.1默认调用
from sklearn.preprocessing import Normalizer
X_transformed = Normalizer().fit_transform(X)
print(X_transformed)
程序执行结果: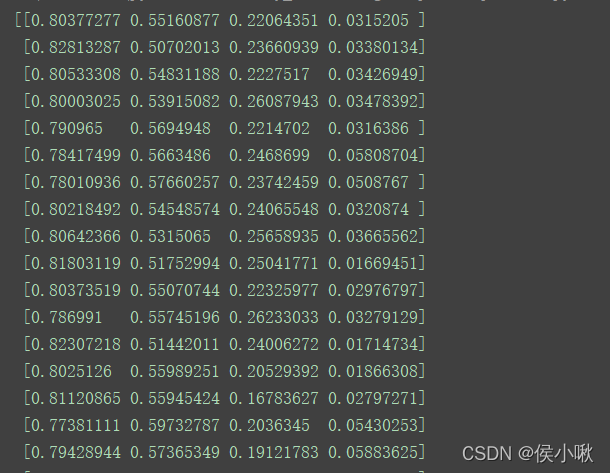
2.2相关属性/参数
(self, norm=‘l2’, *, copy=True)
norm默认为’l2’(是字母l不是数字1)。可以取的值有"l1",“l2”,“max”。
-
'l2’表示,变换方式为,每个特征值,转换为该特征值的平方,占该该样本所有特征值的平方之比。
即
-
'l1’表示,变换方式为,每个特征值,转换为 其占该样本每个特征值的绝对值之和之比。
-
'max’表示,变换方式为,各个特征值除以样本中特征值最大的值。
copy同上,即是否复制。默认为True表示复制,复制就不更改原数据集。
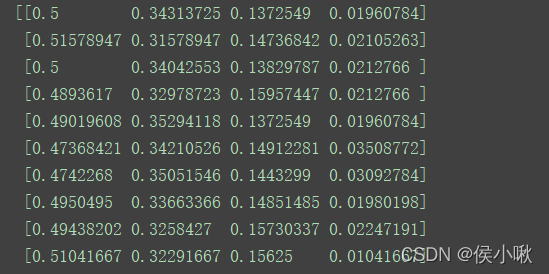
from sklearn.preprocessing import Normalizer
X_transformed = Normalizer(norm='l1').fit_transform(X)
print(X_transformed)
程序执行结果:
③标准化
3.1默认调用
from sklearn.preprocessing import StandardScaler
X_transformed = StandardScaler().fit_transform()
print(X_transformed)
程序执行结果: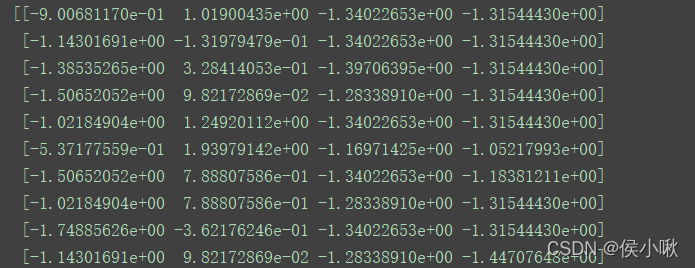
3.2相关属性/参数
StandardScaler(self, *, copy=True, with_mean=True, with_std=True)
- with_mean 考虑均值
- with_std 考虑标准差
- copy 是否复制(同上)
④二值化
4.1默认调用
阈值默认为0,即大于0的数据转换为1,小于0的数据都转换为0。
from sklearn.preprocessing import Binarizer
X_transformed = Binarizer().fit_transform(X)
print(X_transformed)
程序执行结果:
4.2相关属性/参数
(self, *, threshold=0.0, copy=True)
- threshold 阈值
- copy 是否复制(同上)
from sklearn.preprocessing import Binarizer
X_transformed = Binarizer(threshold=3).fit_transform(X)
print(X_transformed)
程序执行结果:
