
1.文件的打开
1.1 open()函数
文件(file)也通过Python程序来对计算机中的各种文件进行增删改查 的操作 。
文件的操作步骤:
- 打开文件
- 对文件进行各种操作(读、写)然后保存
- 关闭文件
示例
先创建我们要运行的py文件,在当前文件所在目录创建一个名为demo的文本文件(txt文档格式)。
然后在其中手动写入以下字符内容并保存
123456
abcdef
01010101
再在原py文件中写入以下代码:
# python 操作数据都是要通过操作这个数据创建的变量才可以实施
file_name = 'demo.txt' # 绝对路径
file_obj = open(file_name) # 打开的文件对象
print(file_obj)
如果不懂路径相关的,open()函数因为找不到文件而报错,也可以直接把file_name变量名定义成 "路径+demo.txt"的格式。这样无论demo.txt文件放在哪里都是可以找到的。
如图,open(file_name)成功创建出了一个对象。
可以将文件分为2种类型,
- 一种是纯文本文件(使用utf-8编码编写的文件)。
- 一种是二进制文件(图片 mp3 视频…)
open()打开文件时,默认是以文本文件的形式打开的,open()默认的编码为None,所以处理文本文件时要指定编码。这一环节在下边的读取部分中再体现。
1.2 with open(xxx) as xx: 语句
也可以用with open(xxx) as xx: 语句来代替直接进行对open()函数的调用。
file_name = 'demo.txt'
try:
with open(file_name, encoding='utf-8') as f: # 对于我们打开的这个文件对象取名为f
file_obj = open(file_name) # 打开的文件对象
print(file_obj)
except FileNotFoundError:
print('文件名没有找到')
2. 文件的读取
2.1 read()函数
通过read()函数读取文件内容时会将文件中所有的内容全部读取出来。。
file_name = 'demo.txt'
file_obj = open(file_name) # 打开的文件对象
content = file_obj.read()
输出结果如下:
demo.txt文档被打印出了。
如要查看read()函数说明的文本字符串:
help(file_obj.read) # 可以以这样的形式来查看read()函数的用法详情
结果如下: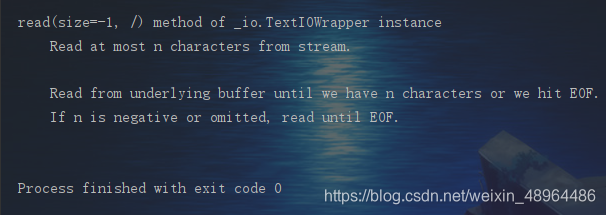
2.2 读取中文 encoding参数
如果demo.txt文本文件中有中文,(比如现在我们在其中再写入一行“云雀叫了一整天”七个字。)
再运行上述代码则会报错:
我们需要在open()函数中加入参数encoding=‘utf-8’,才可读取。
- (基础补充:Unicode及万国码 包含世界上所有语言和字符,编写程序一般都会使用Unicode编码。Unicode编码有多种实现: UTF-8 UTF-16 UTF-32。其中UTF-8支持的字符是最多的。UTF-16少一半,UTF-32又少一半。支持字符越多适用范围越广,支持字符越少越简洁高效。我们一般使用utf-8较多)
file_name = 'demo.txt'
file_obj = open(file_name, encoding='utf-8') # 打开的文件对象
content = file_obj.read()
结果正常打印出了:
2.3 较大文件的读取 readline()与readlines()
read()可以接收一个size作为参数,改参数用来指定读取字符的数量,默认为-1,表示读取全部内容。
file_name = 'demo.txt'
file_obj = open(file_name, encoding='utf-8') # 打开的文件对象
content = file_obj.read(25) # 读取25个字符
print(content)
结果:
如果读取的文件比较大的话,会一次性地讲文件加载到内容中。容易导致内存泄露。所有对于较大的文件通常不用read()函数读取。
readline()用于一行一行地读取,
readlines()用于一行一行地读取,一次性将读取到的内容封装到一个列表中返回。
file_name = 'demo.txt'
try:
with open(file_name, encoding='utf-8') as f: # 对于我们打开的这个文件对象取名为f
# content = f.read(4) # 给size传递参数,一次读取多少个字节
# content = f.readline() # 一行一行的读取,不再示例。
content = f.readlines() # 也是一行一行的读取,不过会读取完所有,并且存放到列表中
print(content)
except FileNotFoundError:
print('文件名没有找到')
输出结果:
3. 文件的关闭
- 调用close()方法来关闭文件
- with … as …语句自带关闭,不需要写close()。
示例如下:
file_name = 'demo.txt'
file_obj = open(file_name, encoding='utf-8') # 打开的文件对象
content = file_obj.read() # 文件读取
print(content)
file_obj.close() # 关闭文件之后就不能再继续读取了
con = file_obj.read() # 文件读取
print(con)

4. 文件的写入
write()用来向文件中写入内容
- 该方法可以分多次向文件中写入内容
- 写入完成后该方法会返回写入字符的个数
使用open()函数打开问件的时候,必须指定打开文件要做的操作(读,写,追加)。默认为只读。
具体如下: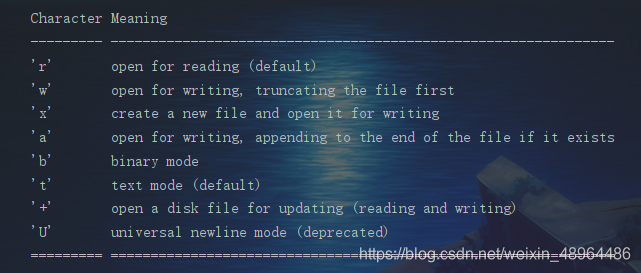
常用的有
- 只读:r,也是默认的。
- w可写,是覆盖写入,会清除原有的内容。如果文件不存在则会创建一个文件。
- a 追加写入,即在原文本后边append新内容,不覆盖。
代码示例:
file_name = 'demo.txt'
file_obj = open(file_name, encoding='utf-8')
content = file_obj.read()
print(content) # 输出原文本
file_obj.close()
try:
with open(file_name, 'a', encoding='utf-8') as f: # 对于我们打开的这个文件对象取名为f
f.write('\n1433223') #换行写入,其中\n表示换行
except FileNotFoundError:
print('文件名没有找到')
file_obj = open(file_name, encoding='utf-8')
content = file_obj.read()
print(content) # 输出追加写入后的文本
file_obj.close()
运行结果:
5. 二进制文件的读写操作
读取文本文件时,size是以字符为单位。而读取二进制文件时,size是以字节为单位。
同样还是使用 open()函数 或者 with open(xxx) as xx: 语句 ,只不过,我们在传入模式参数时,需要在后边加上一个’b’表示二进制文件(binary)。
如wb表示覆盖写入二进制文件,rb表示读取二进制文件,ab表示追加写入二进制文件。其它同文本文件的读写操作。
一个实例:
# 首先我们要准备两个mp3文件,如我选择歌曲 我的战争(巨人片头曲) 和 Tassel。
file_name = r'我的战争.mp3'
# 前边加r表示是告诉解释器所有字符按照原本的样子进行解释,即不存在转义字符。当此字符串包含文件路径时,作用就显而易见了。
# 将读取出来的二进制文件内容续写成一个新的二进制文件
with open(file_name, 'rb') as f: # 只读模式打开“我的战争.mp3”
# print(f)
new_file = 'Tassel.mp3'
with open(new_file, 'ab') as file: # 追加写入模式 打开"Tessel.mp3"
while True:
content = f.read() # 读取“我的战争.mp3”
if not content: # 当content为None的时候
break
file.write(content) # 将我的战争的二进制序列写在Tassel后边
运行后我们可以发现,再去听原Tassel.mp3文件的时候,我们战争.mp3也被拼接在了后边,歌曲长度变长了。
这里的read()函数,里边的size参数的数值表示字节,# 如read(1024*10),1024表示byte为1kb,后边乘以多少就表示读取 我的战争 多少kb。
本次分享就到这里,祝您学习顺利!
