
作者:楚牧
前言
在Dataphin核心功能: 规划功能一文中, 讲到过Dataphin的OneModel方法论将数据建设分为四层, 分别为主题域模型(建模), 概念模型, 逻辑模型和分析模型。前两个模型已在规划一文中介绍过, 本文将继续展开逻辑模型和分析模型的讲解。这四层都是属于Dataphin的智能研发,也称规范研发或逻辑化研发。除此之外, Dataphin还支持传统通用的各种研发方式, 如 SQL, MapReduce, Shell, Python 等,本文将重点解释智能研发。

数据分层
在介绍智能研发的逻辑模型和分析模型之前, 先简单说下另一种维度的数据分层。当前, 在数据中台领域, 通用的做法是根据数据的使用场景和生产方式, 将数据分为:
- ODS (Operational Data Source), 按照字面理解是操作数据来源, 通常的叫法是贴源数据层。ODS是从业务应用系统中同步过来的数据, 一般不对数据做任何清洗加工、镜像复制, 但是会保留多个版本,因为业务应用的数据一直在更新变化, ODS会保留部分中间过程版本数据。
- CDM (Common Data Model), 公共数据模型层, 数据的清洗加工, 建模都在这一层进行,智能研发也主要在这一层。
- ADS/ADM (Application Data Summary) 应用数据层, 面向具体业务场景的数据研发。
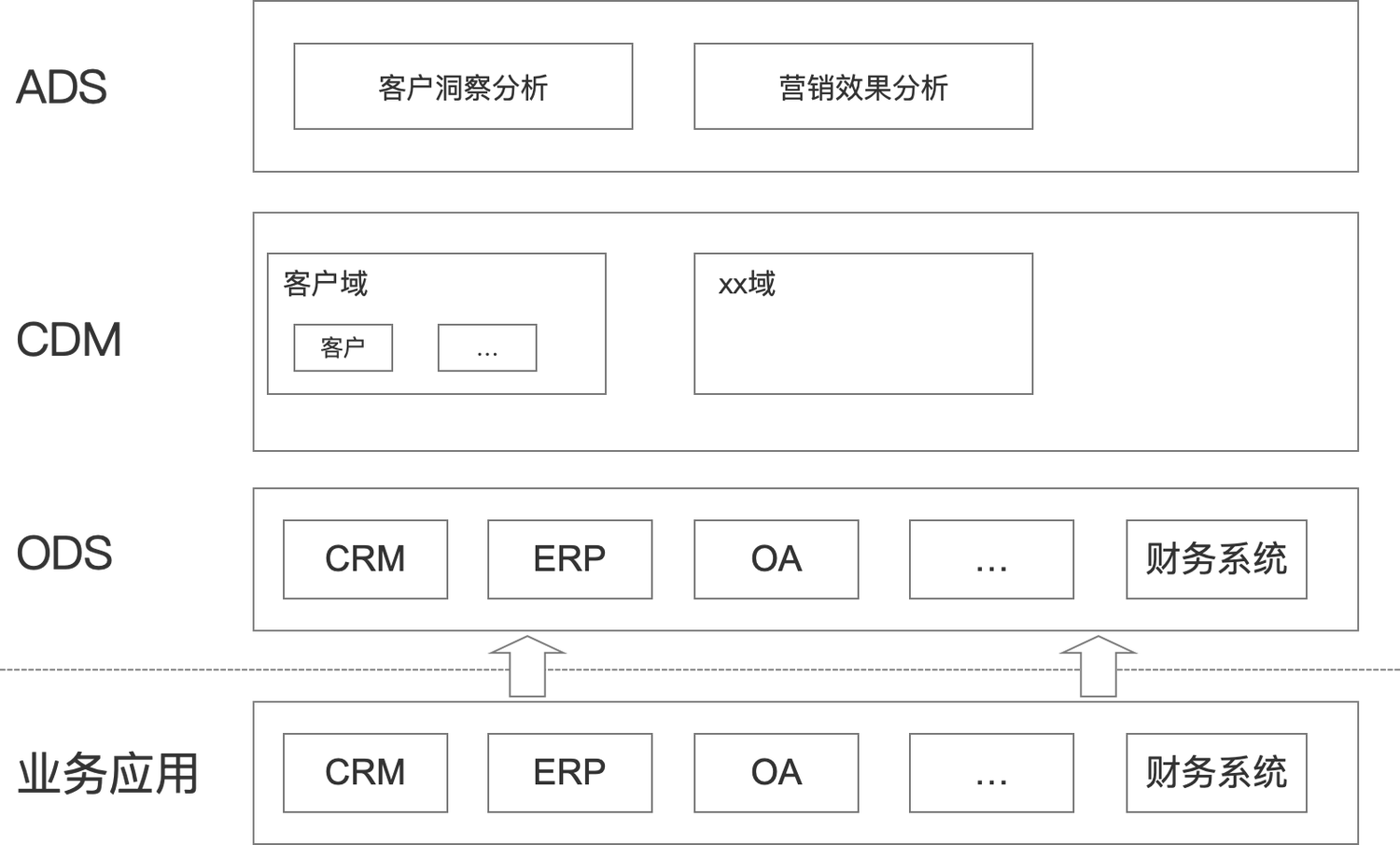
Dataphin中,规划到研发的流程一般是, 规划(板块划分->主题域建模->概念建模) -> 项目创建 -> ODS (数据上云/数据同步) -> CDM (逻辑建模->分析建模) -> ADS
逻辑模型
根据上一节的介绍, 现在假设 规划->项目创建->ODS 均已完成, 接下来就进入了逻辑建模
属性与约束
在概念建模中, 创建好实体, 配置好实体间的关系, 整个业务的大图就已经清晰的落地到数据中台。但是不同实体除了名字不同, 关系不一样之外, 还有哪些区别呢?例如,用户和会员有什么区别,这就是逻辑建模要来解决的问题。逻辑建模的核心工作是梳理实体的特征, 即给实体添加属性, 并明确属性的业务约束, 一个实体有很多属性(也叫特征), 这些属性可以用于区分实体。
属性按照类型, 可以分为:
- 标识属性, 即实体的某个具体实例的唯一标识。实体是一个抽象概念, 实体实例是具体事物。比如,商品鞋是一个实体。一双36码、白色、编码为6901234的鞋就是一个实例。一个实体可以有多个标识属性, 如商品ID, 商品编码
- 关联实体属性, 实体的某个属性本身可能也是一个实体。比如, 商品的卖家(货主)属性, 卖家是一个独立的实体
- 描述属性, 表述实体某一个维度的特征的一般属性, 实体中的定性属性, 一般是文本字符类型,如, 名称
- 度量属性, 某个维度数量程度的属性, 定量属性. 一般是数值类型, 如: 金额, 价格
- 时间属性, 描述实体某个行为的时间
根据实体的类型(业务对象或业务活动), 每个实体都有一些必须有的属性, 即关键属性:
- 业务对象至少有一个标识属性, 根据业务可以添加其他关键属性
- 业务活动必须有一个关联实体属性来标识活动的主体(发起人, 比如 订单活动中的买家), 一个或多个时间属性来明确活动时间。
实体丰富了属性之后还不能完全反映业务现实, 还需要给属性加上一些约束规则:
- 取值规则, 约束属性的取值范围, 即约束实体实例中该属性的具体内容的有效性
- 枚举值, 如 鞋子颜色只有黑色和白色两个
- 取值范围, 如 年龄一般是0~150
- 模式匹配, 如 身份证号码必须是15或者18位, 且最后一位才能有字母X, 其他必须是数字
- 唯一性, 除标识属性外, 其他属性也可能有唯一性要求
- 非空性, 不允许该属性出现空值
- 其他
实例化
定义好逻辑模型后, 映射数据到模型的过程就是模型的实例化, 浅白的说就是将物理的数据映射到逻辑模型。实例化的数据来源是ODS数据,少数情形下, ODS数据需要做一些额外处理, 将其按照一定的规则注册挂载到逻辑模型。Dataphin将根据映射自动生成计算代码和周期调度任务, 并基于属性约束生成数据质量校验规则。到这一步, 就完成了逻辑模型的构建。
分析模型
逻辑模型构建后之后, 基于逻辑模型可以构建分析模型, 即下图中的业务分析模型。分析模型的目标是快速生成业务分析中的指标,称为派生指标, 并且保障这些指标的可靠性和可维护性。通过把最终使用的指标拆解为四个基本组成部分,以最近30天按省份30岁以上男性下单金额为例:
- 统计周期, 业务发生的时间区段, 即例子中的 "最近30天"
- 原子指标, 分析指标不区分维度不加任何约束限制的基础抽象, 即例子中的 "下单金额", 原子指标是对实体的某个属性在所有实体实例上的整体刻画, 是一种统计性描述, 即原子指标一定是一个聚合表达式,如求和, 平均, 最大, 最小等
- 业务限定, 指标上的业务约束, 即例子中的 "30岁以上男性"
- 统计粒度, 分析的维度, 看业务的视角, 即例子中的 "省份"

以上描述可能还是让人无法准确明白分析模型是什么, 可以参照下图, 从传统SQL视角来理解:

分析建模的步骤是, 统计周期设置(系统内置了大部分常用统计周期)->原子指标/业务限定配置->派生指标配置, 所有配置完成后, 系统将自动生成计算代码(如上图)和周期调度任务。
Dataphin通过规范化、模块化的低代码配置式研发, 有效的保证了模型与代码的一致性。
关联阅读:
Dataphin产品核心功能大图(一)规划: 企业数据体系应该怎么规划
Dataphin产品核心功能大图(二)集成:如何将业务系统的数据抽取汇聚到数据中台
了解产品更多内容可以戳入:https://dp.alibaba.com/product/dataphin
数据中台是企业数智化的必经之路,阿里巴巴认为数据中台是集方法论、工具、组织于一体的,“快”、“准”、“全”、“统”、“通”的智能大数据体系。
目前正通过阿里云对外输出系列解决方案,包括通用数据中台解决方案、零售数据中台解决方案、金融数据中台解决方案、互联网数据中台解决方案、政务数据中台解决方案等细分场景。
其中阿里云数据中台产品矩阵是以Dataphin为基座,以Quick系列为业务场景化切入,包括:
- - Dataphin,一站式、智能化的数据构建及管理平台;
- - Quick BI,随时随地 智能决策;
- - Quick Audience,全方位洞察、全域营销、智能增长;
- - Quick A+, 跨多端全域应用体验分析及洞察的一站式数据化运营平台;
- - Quick Stock, 智能货品运营平台;
- - Quick Decision,智能决策平台;
官方站点:
数据中台官网 https://dp.alibaba.com
钉钉沟通群和微信公众号

