
在上一讲的基础上,我们来做来一个实际的例子来展示如何在实操中进行高效的hive查询作业。
(1)首先我们建立一个表
CREATE EXTERNAL TABLE pos_staging(
txnid STRING,
txntime STRING,
givenname STRING,
lastname STRING,
postalcode STRING,
storeid STRING,
indl STRING,
productid STRING,
purchaseamount FLOAT,
creditcard STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
LOCATION '/user/hdfs/staging_data/pos_staging';
我们建立一张外部表是为了初始化或者加载mapreduce或者pig作业产生的元数据,然后我们自己建立一张优化的表。
(2)建立调优表的时候,我们就要考虑使用哪种分区模式,比如按时间分区。

以下是两个关于动态分区的参数:
所有节点的动态分区的最大数以及每个节点的动态分区的最大数
hive.exec.max.dynamic.partitions=1000
hive.exec.max.dynamic.partitions.pernode=100(3)建立调优表
CREATE TABLE fact_pos
(
txnid STRING,
txntime STRING,
givenname STRING,
lastname STRING,
postalcode STRING,
storeidSTRING,
indl STRING,
productid STRING,
purchaseamountFLOAT,
creditcardSTRING
) PARTITIONED BY (part_dt STRING)!
CLUSTERED BY (txnid)
SORTED BY (txnid)
INTO 24 BUCKETS
STORED AS ORC tblproperties("orc.compress"="SNAPPY");CLUSTERED 和SORTED 使用都是同一个字段,它就是连接的时候需要使用的字段。
BUCKETS也出现了,前面一直不理解的概念,现在出现了还分了24个。
(4)把数据插入到调优表中
FROM pos_staging
INSERT OVERWRITE TABLE fact_pos
PARTITION (part_dt)
SELECT
txnid,
txntime,
givenname,
lastname,
postalcode,
storeid,
indl,
productid,
purchaseamount,
creditcard,
concat(year(txntime),month(txntime)) as part_dt
SORT BY productid;语句中使用了前面教的自动分区的语句,按照年月自动分区。

hadoop fs-setrep-R –w 5 /apps/hive/warehouse/fact_pos
上面的命令当中是个hdfs中存数的fact_pos表增加备份,因为hdfs的数据是存得很分散的,增加备份因为会使得节点上的数据增多,然后查询的时候,hive
从本地直接就可以获取到的数据的几率提高,增快查询速度。
当然考虑到空间的问题,可以减少一下备份的数量。
上述流程我们也可以把它放到oozie中自动执行。

。。。又一个熟悉的词出现了。
在hdfs-site.xml或者Ambari settings for HDFS, 设置完要重启。
dfs.block.local-path-access.user=hdfs
dfs.client.read.shortcircuit=true
dfs.client.read.shortcircuit.skip.checksum=false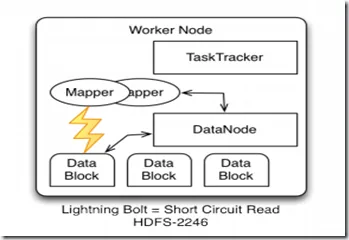
开启了这个东东有什么作用呢?当数据块在本地的时候,它可以不需要开启一个端口来读,可以直接访问,就像图中的闪电那样。
(5)执行查询
set hive.mapred.reduce.tasks.speculative.execution=false;
set io.sort.mb=300;
set mapreduce.reduce.input.limit=-1;
select productid, ROUND(SUM(purchaseamount),2) as total
from fact_pos
where part_dt between ‘201210’ and ‘201212’
group by productid
order by total desc
limit 100;
查询之前先对查询设置相应的运行参数。

