一. 什么时候需要HBase
半结构化或非结构化数据
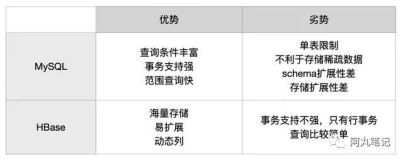
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。当业务发展需要增加存储比如一个用户的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加.
记录非常稀疏
RDBMS的行有多少列是固定的,为null的列浪费了存储空间。而如上文提到的,HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
多版本数据
根据Row key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。对于某一值,业务上一般只需要最新的值,但有时可能需要查询到历史值。
超大数据量
当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)
二. HTable一些基本概念
Row key
行主键, HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描,因此Row key需要根据业务来设计以利用其存储排序特性(Table按Row key字典序排序如1,10,100,11,2)提高性能。
Column Family(列族)
在表创建时声明,每个Column Family为一个存储单元。
Column(列)
HBase的每个列都属于一个列族,以列族名为前缀,如列article:title和article:content属于article列族,author:name和author:nickname属于author列族。
Column不用创建表时定义即可以动态新增,同一Column Family的Columns会群聚在一个存储单元上,并依Column key排序,因此设计时应将具有相同I/O特性的Column设计在一个Column Family上以提高性能。
Timestamp
HBase通过row和column确定一份数据,这份数据的值可能有多个版本,不同版本的值按照时间倒序排序,即最新的数据排在最前面,查询时默认返回最新版本。Timestamp默认为系统当前时间(精确到毫秒),也可以在写入数据时指定该值。
Value
每个值通过4个键唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value
存储类型
- TableName 是字符串
- RowKey 和 ColumnName 是二进制值(Java 类型 byte[])
- Timestamp 是一个 64 位整数(Java 类型 long)
- value 是一个字节数组(Java类型 byte[])。
将HTable的存储结构理解为

即HTable按Row key自动排序,每个Row包含任意数量个Columns,Columns之间按Column key自动排序,每个Column包含任意数量个Values。理解该存储结构将有助于查询结果的迭代。
三. 模式设计应遵循的原则
列族的数量以及列族的势
列族的数量越少越好,牵扯到了hbase的flushing;同一个表中不同列族所存储的记录数量的差别也需要考虑(列族的势),会造成记录数量少的列族的数据分散在多个region上,影响查询效率。
行键的设计
避免使用时序或者单调(递增/递减)行键,否则会导致连续到来的数据会被分配到统一region中。
尽量最小化行键和列族的大小
避免hbase的索引过大,加重系统存储的负担
版本的数量
HColumnDescriptor设置版本的数量,避免设置过大,版本保留过多。