
在最近的活字格项目中使用ActiveReports报表设计器设计一个报表模板时,遇到一个多级分类的难题:需要将某个部门所有销售及下属部门的销售金额汇总,因为下属级别的层次不确定,所以靠拼接子查询的方式显然是不能满足要求,经过一番实验,利用了CTE(Common Table Expression)很轻松解决了这个问题!
举例:有如下的部门表

以及员工表

如果想查询所有西北区的员工(包含西北、西安、兰州),如下图所示:

如何用CTE的方式实现呢?
Talk is cheap. Show me the code
-- 以下代码使用SQLite 3.18.0 测试通过 WITH [depts]([dept_id]) AS( SELECT [d].[dept_id] FROM [dept] [d] JOIN [employees] [e] ON [d].[dept_id] = [e].[dept_id] WHERE [e].[emp_name] = '西北-经理' UNION ALL SELECT [d].[dept_id] FROM [dept] [d] JOIN [depts] [s] ON [d].[parent_id] = [s].[dept_id] ) SELECT * FROM [employees] WHERE [dept_id] IN (SELECT [dept_id] FROM [depts]);
可能有些同学对CTE(Common Table Expression)还不太熟悉,这里简单说一下,有兴趣的同学可以google或者百度,介绍很多(这里以SQLite举例):
我还是更喜欢称CTE(Common Table Expression)为“公用表变量”而不是“公用表达式”,因为从行为和使用场景上讲,CTE更多的时候是产生(分迭代或者不迭代)结果集,供其后的语句使用(查询、插入、删除或更新),如上述的例子就是一个典型的利用迭代遍历树形结构数据。
CTE的优点:
- 递归的特点使得原本需要使用临时表、存储过程才能完成的逻辑,通过SQL就可以完成,尤其针对一些树或者是图的数据模型
- 因为是会话内的临时结果集,不需要去显示的声明或销毁
- 改写后的SQL语句可读性提高(看的明白才能修改)
- 给数据库引擎优化执行计划的可能性(这个不是肯定的,需要根据具体CTE的实现有关),优化了执行计划,自然地性能就能上升
为了更好的说明CTE的能力,这里附上两个例子(转自SQLite官网文档)
曼德勃罗集合(Mandelbrot set)
-- 以下代码使用SQLite 3.18.0 测试通过 WITH RECURSIVE xaxis(x) AS (VALUES(-2.0) UNION ALL SELECT x+0.05 FROM xaxis WHERE x<1.2), yaxis(y) AS (VALUES(-1.0) UNION ALL SELECT y+0.1 FROM yaxis WHERE y<1.0), m(iter, cx, cy, x, y) AS ( SELECT 0, x, y, 0.0, 0.0 FROM xaxis, yaxis UNION ALL SELECT iter+1, cx, cy, x*x-y*y + cx, 2.0*x*y + cy FROM m WHERE (x*x + y*y) < 4.0 AND iter<28 ), m2(iter, cx, cy) AS ( SELECT max(iter), cx, cy FROM m GROUP BY cx, cy ), a(t) AS ( SELECT group_concat( substr(' .+*#', 1+min(iter/7,4), 1), '') FROM m2 GROUP BY cy ) SELECT group_concat(rtrim(t),x'0a') FROM a;
运行后的结果,如下图:(使用SQLite Expert Personal 4.2 x64)

数独问题(Sudoku)
假设有类似下图的问题:

-- 以下代码使用SQLite 3.18.0 测试通过 WITH RECURSIVE input(sud) AS ( VALUES('53..7....6..195....98....6.8...6...34..8.3..17...2...6.6....28....419..5....8..79') ), digits(z, lp) AS ( VALUES('1', 1) UNION ALL SELECT CAST(lp+1 AS TEXT), lp+1 FROM digits WHERE lp<9 ), x(s, ind) AS ( SELECT sud, instr(sud, '.') FROM input UNION ALL SELECT substr(s, 1, ind-1) || z || substr(s, ind+1), instr( substr(s, 1, ind-1) || z || substr(s, ind+1), '.' ) FROM x, digits AS z WHERE ind>0 AND NOT EXISTS ( SELECT 1 FROM digits AS lp WHERE z.z = substr(s, ((ind-1)/9)*9 + lp, 1) OR z.z = substr(s, ((ind-1)%9) + (lp-1)*9 + 1, 1) OR z.z = substr(s, (((ind-1)/3) % 3) * 3 + ((ind-1)/27) * 27 + lp + ((lp-1) / 3) * 6, 1) ) ) SELECT s FROM x WHERE ind=0;
执行结果(结果中的数字就是对应格子中的答案)

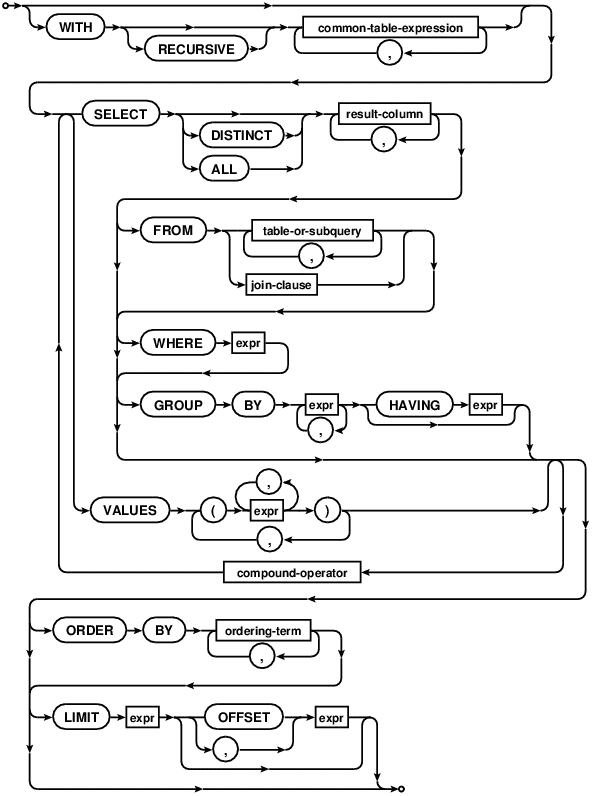
附:SQLite中CTE(WITH关键字)语法图解:
WITH

cte-table-name

Select-stmt:
总结
CTE是解决一些特定问题的利器,但了解和正确的使用是前提,在决定将已有的一些SQL重构为CTE之前,确保对已有语句有清晰的理解以及对CTE足够的学习!Good Luck~~~
附件:用到的SQL脚本
相关阅读:

