

1、序言
自从互联网从web1.0跨入到SNS时代,用户开始从站点获取数据跨入到用户自己产生数据,分享数据,这时用户的数据存储开始急剧增长。更重要的是时代的发展,用户内容从文字时代跨入到了图片时代,这个时代的明星产品--qq相册的诞生,更是让用户分享数据达到了一个顶峰。在这个数据开始飞速增长的时代,当时是没有合适的存储引擎和方案来支持的。在qq相册飞速发展的同时,由当时存储系统的万金油--mysql搭建的存储解决方案,遇到了访问延时高,扩容困难,成本高,等问题。而这一类问题也同样困扰着所有的互联网公司。因为那时是一个没有真正存储系统的混乱时代。这个时代,我们的存储还不到1PB。
这时在GFS,bigtable等论文中,各大互联网公司从困扰中找到灵感,纷纷效仿推出类GFS存储引擎。腾讯也不例外,由TEG--架构平台部研发的TFS存储家族横空出世,并推进了由没有定制存储系统的混乱时代向TFS1.0的演进。
2、TFS家族诞生
TFS家族1.0整体设计中包含对开发,运维,资源管理等各个要素的考虑,并由各个相关要素的组件组成。其中最重要的两个引擎组件为基于SAS和内存的KV索引存储引擎,以及基于SATA的数据存储引擎。正是这两个核心引擎解决了腾讯存储在跨越PB级别中,所遇到的存储上的难题。
2.1 KV存储引擎特性
以农牧场为代表,基于社交关系的各种应用和游戏越来越多。这类应用或游戏的特点是单个用户的一个操作会涉及大量数据的读写,而且是对于数据的部分读写,对后台数据存储带来的极大的性能挑战。传统关系型数据库如Mysql更偏向数据一致性的保证,复杂的引擎设计注定了性能相对较低,虽然读性能可以通过实现Cache解决,但是写性能始终是一个不能规避的难题。因此,key-value形式数据库特别适合,特点是小块数据的快速存取、数据弱一致性。TFS家族的KV存储引擎就是为这种业务场景而诞生的通用、高速、持久化Nosql存储系统。KV存储引擎具备高性能 、低成本、高可用的良好业务体验,能轻松应对海量数据访问、存储成本敏感、延时敏感等问题,并且安全可靠 ,拥有多份热点数据和流水落盘,备份中心备份数据和流水,具备回档能力。
业务根据数据读写时延的需求,可以自由选择内存,SSD,SAS等做为存储介质,甚至可以更通用的让系统自动选择冷热数据存储在不同的介质上。在内存中存取延时达到极致的us级别,支持超高并发的读写请求,普通单机可跑到30w/s读或11w/s 写。在加入多队列支持和10G网卡后单机性能超过100w/s。这种读写性能,完美的解决了农牧场的高并发写问题。
KV引擎最重要的特性是多个介质集群中,可以自动调度数据,下图就内存集群和SSD集群之间的数据自动调度。将热数据存储在内存集群,冷数据存储在成本更低的SSD存储集群有几个优点:用户访问是透明的,成本是降低的,体验是提升的。
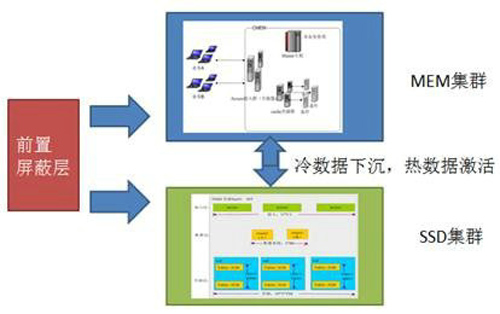
2.2 文件存储引擎特性
TFS文件存储引擎分为数据层、索引层和逻辑层三个部分。数据层负责文件数据的存储,提供k-v接口,Value长度一般限定为1M,大文件由逻辑层切分成多个片顺序存储。索引层包含文件索引、目录索引和去重索引。文件索引保存文件的元信息(创建时间、修改时间、文件长度)、分片信息和业务自定义的blob字段。目录索引提供按照目录树组织的索引结构,索引中只保存文件、目录的元信息和在文件中的key。去重索引保存了分片的哈希值与数据层key的对应关系,用于上传时查找已经存在的数据分片,避免重复上传。逻辑层串联文件上传、下载、删除、修改等所有接口的流程控制,提供原子操作。

TFS文件存储引擎主要解决了索引数据的存储问题,数据层的管理,以及业务文件存储特性的需求。
在TFS1.0家族的强力支撑下,我们解决了在图片时代,SNS场景的存储问题,这时用户的数据依然急剧增长,由PB级别,飞速发展到几百P级别。用户的SNS场景依然猛烈的发展,但用户内容却慢慢的由图片在向视频转变,随着IT技术的发展,用户的内容质量越来越高,视觉体验越来越好,这都意味着最底层的数据存储爆发式的增长。而这些增长下,TFS1.0家族显得越来越跟不上时代的发展,从而暴漏出了索引层成本高,功能不够丰富,数据层的数据安全与成本之间的矛盾。在新时代新存储矛盾的触发下,TFS家族由1.0升级到了2.0版本,从而应对降低存储成本以及新存储功能的需求。
3、新TFS时代
3.1.1 数据存储引擎的升级
为了降低数据存储成本,我们采取用计算换取空间的做法,与传统3副本存储方式相比, TFS新文件存储引擎的副本数只有1.X份,在保证数据可靠性的前提下,TFS通过牺牲一部分访问性能,换取更大的成本收益。采取的是RS编码方式,在M份业务数据块的基础上编码计算出X份校验块, 一共M+X个块组成一个条带落地存储。
3.1.2 索引存储引擎的升级
我们使用了多年的KV存储引擎,也遇到了新的挑战,不支持范围查询接口。业务有相关需求时,需要通过大量数据组织逻辑,以构建出适用的数据模型。所以TFS家族推出新的类LevelDB存储引擎,丰富TFS家族中的组件,主要设计如下:
通过业务场景和底层平台的深度配合,对外提供了丰富的数据处理接口。
3.1.3 业务形态的深度理解
在TFS家族核心组件全面升级的过程中,我们不光需要底层平台的强力支持,更需要在对业务深度理解的前提下,做出精准的存储策略,打造出专业的定制存储系统。
在基于TFS打造的专业图片平台,图片平台以稳定可靠的图片存储及加速下载为基础,配套以强大的图片处理、自动化的违禁图审核功能,并针对业务模型做冷热流量调度、存储数据降冷等一系列成本体验优化,为图片客户提供了一套完整的解决方案。强大的图片处理功能涵盖了各类应用场景,有图片缩放、裁剪、旋转,图片水印,格式转换,信息获取等,支持上传时处理后落地存储,也支持下载时实时生成。同时图片丰富的表现力,也让违禁图十分活跃,图片平台配有上传即可触发的全自动审核流程,平台具备整套审核及禁图操作,业务无需参与即可轻松享有。
在文件存储平台上,在TFS家族中推出了一系列针对不同用户场景使用的分支存储系统,包括适应腾讯视频等高频存储业务使用的多副本存储引擎,适应QQ离线传文件等临时存储业务使用的即删即用存储引擎,等等。往往一个业务的文件不可能只适应一个存储系统,大多数文件随着时间的推移会逐渐变冷,通过对各个业务的深入理解,对用户行为的深度理解,以及大量的数据分析,平台实现了文件在各个存储引擎之间的智能调度,大大节省了存储成本。
3.1.4 自动的运营体系

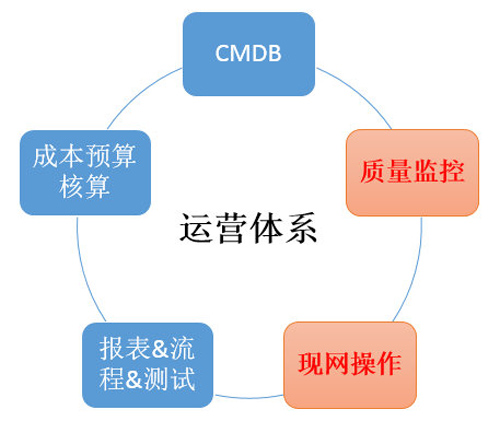
架平的运营体系主要包括基础配置CMDB、成本预算核算、报表&流程&测试、质量监控、现网操作这五大块,这五大部分组合成一个完整的运营体,为部门业务安全可靠高效的运营保驾护航。
CMDB:基础性的配置管理,包括了设备、机房、业务等基础信息,主要提供设备资源提前报备、到货验收初始化、高危端口管理、设备转移退役等功能;
成本预算核算:部门本身不直接对外营收,但却承载了公司海量的存储、CDN服务,部门每年的运营成本占了公司总运营成本的相当一部分,必然要有全面、严谨的成本管控核算,然后分摊到服务的各个业务部门;
报表&流程&测试:业务多报表多,需要有个报表系统来统一管理,现网变更的管理、突发事件产生后在哪里跟进、验证是否解决等,以及对现网质量关键的保障一环就是模块开发完成后发布到现网前,还需要先过自动化测试这一环节,以便发现潜在的BUG;
质量监控:我们的眼睛,时刻盯着数十万台服务器、成百上千个业务,一旦出现异常,最快秒级主动通知到负责人,降低对业务的影响时长;
现网操作:服务器达到数十万台、分布在各种不同运营商、甚至海外机房、aws等场景,我们有一套专用系统来支撑对现网安全、高效的操作。
4、结束语
正是有了新TFS家族,定制的KV引擎,文件存储引擎,以及对业务数据的深度理解,多年来积累的现网运营经验,才确保了EB级的数据,安全稳定的运行。在这个过程中,我们积累了多年的海量数据运营经验,也会在接下来的系列文章中,依次呈现,敬请期待。
本文作者:佚名
来源:51CTO

