
本文讲的是大数据玩家们对2013年趋势的预测,本文来自ZDnet的记者Adrew Brust的博客文章。主要陈述大数据业内人士对2013年发展的预测和作者自己的一些观点。
在大数据领域,虽然对技术产业的预测是不可缺少的,但是Adrew对宣传一个具体公司的计划明显缺乏兴趣,而且许多业内公司都把他们明年的计划发给了Adrew,所以他认为:如果能把这些2013年的预测整合一下,再融入自己的观点,将是一件非常有意思的事情。
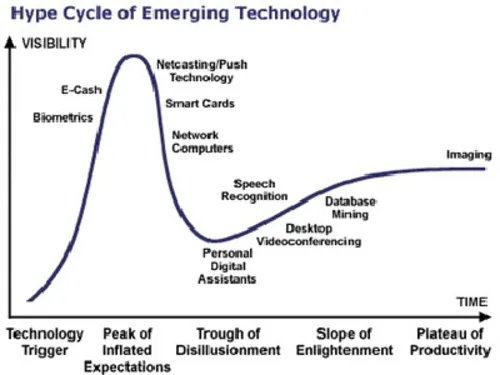
▲图:Big Data将会在2013发展到哪个阶段?
Hadoop的2013
首先从Hadoop说起。做为大数据领域的代表技术,许多企业都把明年的计划聚焦在Hadoop之上。MapR的执行总监John Schroeder预测,“用户对Hadoop的优化将更注重硬件”。同时,Pervasive Software的技术总监Mike Hoskins也指出,“对企业友好的Hadoop技术市场将达到前所未有的高峰”。
Adrew认为这两个预测都会发生,从整体上说,不仅是Hadoop本身本会得到迅猛的发展,同时Hadoop在多个数据中心中的配置和无缝集成技术也将成为热门。或许因为于此,MapR的Schroeder会说,“Hadoop的专业知识正在飞速增长,但是这方面优秀的人才仍然很缺乏”,他还预测,“基于SQL的Hadoop工具将会得到持续发展”。对于后面的这个预测我们没法提出反对的意见,因为仅仅在过去的一个季度里,这样的工具就取得了巨大的发展,并且目前的发展势头也有减弱。
然而并不是所有的观点都一致。Rainstor自己就有基于SQL-Hadoop的混合产品,它预测一旦当企业需要对大数据进行管理,在明年将会寻找新技术,而不仅仅局限于Hadoop,这就和Pervasive的预测形成了强烈的对比,“MapR将占领传统数据仓库的市场,Hadoop将会成为大数据分析的不二选择”。
Hadoop上层
过去Hadoop已经给我们带来了许多微妙的预测。Rainstor预测,“企业的大数据热情将从底层研究中释放出来,他们会更多地关注一系列清晰的业务和技术。”MapR预测,“开源(增加收入)的应用将胜过节流应用”。其他公司的预测基本上都认为,明年的用户将会转移到成熟的更高层次的大数据模型之上。
虽然他们是对的,但是从底层中转移出来并不容易,其中还有许多问题尚未解决。许多预测师似乎都有同感,普遍的说法是,Data Quality将会继续成为企业的烫手山芋”。Progress DataDirect的专家预测,“企业将会被他们自己的数据淹没,同时分散的数据也会带来新的麻烦。”这些预测似乎有点危言耸听,但是在商务智能的世界里,这些预测已经不新鲜了。如果说大数据的世界能避免这些问题,那恐怕只会是一场美好愿景下的炒作。一旦这些炒作过去,那些问题就会凸显,使你无法逃避。
数据分析和虚拟化
业界人士发给Adrew预测的并不只有Rainstor, Pervasive, MapR 和 Progress DataDirect。Adrew同样收到了关注市场分析的BlueKai和iOS数据虚拟的供应商Roambi的预测。他们的预测都是基于自己的服务,普遍涉及了用户这个主题,指出他们必然会遇到更多、更复杂的问题。
例如Roambi提到,“有一半的业务数据没法利用到,这影响到了决策和预测的准确性”。BlueKai的执行总监Omar Tawakol指出,“有远见的品牌会重新评估他们的代理,基于最大化利用交叉频道听众的数据能力,去测量数据利用率和ROI。”
降低复杂度
大数据技术的落地将会有两个特点:一个是对MapReduce依赖越来越少,另外一个是会把Hadoop技术深入的应用到企业的软件架构中。
对于第一个特点,Adrew指的是像Cloudera的Impala和微软的PolyBase这样的软件会得到充分发展,他们绕开了MapReduce,直接对存在HDFS中的数据进行处理。MapR预测基于SQL的工具将和上面的软件一起继续发展,Pervasive预测,“YARN正在改变Hadoop的游戏规则,它不仅允许在Hadoop上运行MapReduce应用,同时还允许其他类型的应用在其上面部署。”
对于第二个特点,大规模的使用Hadoop是个必然趋势,渐渐的就会形成行业的标准,进而成为更有价值的软件基础,而不仅是自己内部使用。因此,Adrew认为我们会看到更多集成了Hadoop功能的商务智能和智能分析工具,这样我们对Hadoop专家的依赖就会逐渐降下来。
拭目以待
这些预言中哪些会成为现实,让我们一起拭目以待。
作者: 康文博
来源: IT168
原文标题:大数据玩家们对2013年趋势的预测
