本文讲的是
如何把NMAP扫描结果同步到Elasticsearch?,
如果您对信息安全感兴趣,那么您可能熟悉端口扫描工具nmap。扫描器是用于网络发现和安全审计的免费和开源(许可证)实用程序。许多网络管理员也会使用它发现网络以及监视主机或服务正常运行时间等任务。
$ nmap -T5 -Pn -A -oX report.xml scanme.nmap.org
$ cat report.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE nmaprun> <?xml-stylesheet href="file:///usr/bin/../share/nmap/nmap.xsl" type="text/xsl"?> <!-- Nmap 7.01 scan initiated Mon Jul 18 16:26:06 2016 as: nmap -T5 -Pn -A -oX report.xml scanme.nmap.org --> ...
$ mkdir nmap $ cd nmap
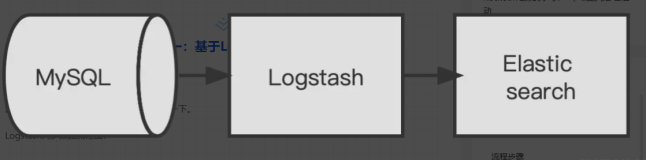
$ wget https://raw.githubusercontent.com/logstash-plugins/logstash-codec-nmap/master/examples/elasticsearch/elasticsearch_nmap_template.json
$ sudo service elasticsearch start $ cd〜/ kibana- * $ cd bin / $ ./kibana&
$ cd ~/nmap $ ls elasticsearch_nmap_template.json report.xml
$ cd/ opt /logstash $ sudo bin /logstash-plugin install logstash-codec-nmap
$ sudo apt-get install ruby-dev
input { file { path => "$HOME/nmap/*.xml" start_position => "beginning" sincedb_path => "/dev/null" codec => nmap tags => [nmap] } } filter { if "nmap" in [tags] { # Don't emit documents for 'down' hosts if [status][state] == "down" { drop {} } mutate { # Drop HTTP headers and logstash server hostname remove_field => ["headers", "hostname"] } if "nmap_traceroute_link" == [type] { geoip { source => "[to][address]" target => "[to][geoip]" } geoip { source => "[from][address]" target => "[from][geoip]" } } if [ipv4] { geoip { source => ipv4 target => geoip } } } } output { if "nmap" in [tags] { elasticsearch { document_type => "nmap-reports" document_id => "%{[id]}" # Nmap data usually isn't too bad, so monthly rotation should be fine index => "nmap-logstash-%{+YYYY.MM}" template => "./elasticsearch_nmap_template.json" template_name => "logstash_nmap" } stdout { codec => json_lines } } }
$/opt/logstash/bin/logstash - f nmap -logstash.CONF
$git clone https//github.com/ChrisRimondi/VulntoES $cd VulntoEs/ $sudo pip install elasticsearch
$curl -XPUT'localhost:9200/ nmap-vuln-to-es'
$python VulntoES.py -i ~/report.xml -e 127.0.0.1 -r nmap -I nmap-vuln-to-es

原文发布时间为:2017年7月4日
本文作者:愣娃
本文来自云栖社区合作伙伴嘶吼,了解相关信息可以关注嘶吼网站。