
VLA(视觉语言动作模型)已成为具身智能开发的主流范式。对于探索前沿技术的科研人员,以及推进落地的应用开发者而言,可灵活调用的模块化结构与标准化的工程底座,是 VLA 从实验室走向真实物理世界的关键基础。
为此,逐际动力LimX Dynamics 开发并正式开源FluxVLA Engine,一个面向具身智能科研创新、应用开发与落地的标准化VLA工程底座。FluxVLA Engine以统一配置、标准接口、模块解耦、加速部署为核心设计理念,将数据处理、模型训练、仿真评测到真机部署的每个环节标准化,大幅降低了 VLA 全研发周期的工程门槛。
👉 GitHub 仓库地址:
https://github.com/FluxVLA/FluxVLA
👉 文档与快速上手教程:
https://fluxvla.limxdynamics.com/
Model Scope权重:
https://modelscope.cn/models/LimXDynamics/FluxVLAEngine

解决三大工程瓶颈,推动VLA走向真实世界
在具身智能落地的研发链路中,以下三类结构性壁垒在当前的科研和工程实践中普遍存在:
数据格式碎片化:训练、仿真与部署阶段通常依赖不同的数据格式与处理逻辑。不同方法之间缺乏统一数据规范,导致数据格式需要反复转换与适配,工程成本远高于算法本身。
代码架构高耦合:数据处理、模型定义与训练评测逻辑往往深度绑定。无论是替换视觉编码器,还是接入新任务或新数据集,均需对现有框架代码进行深入修改,既耗费时间,也容易引入新的错误,造成“换个模型就要重新造轮子”的困境。
仿真到真机的迁移鸿沟:仿真环境中的理想条件无法覆盖真实系统中的延迟、噪声与硬件约束,导致模型在真实机器人上的性能显著下降,难以完成从算法验证到物理执行的闭环。
FluxVLA Engine:具身智能研发的标准化VLA工程底座
FluxVLA Engine 从工程体系层面对上述瓶颈逐一拆解,针对关键环节给出系统化解决方案。核心目标是:
以统一配置与标准化接口,将数据、训练、仿真到真机部署的每个环节规范化,为创新者提供可自由替换和组合的模块,无需每次从头适配。

FluxVLA Engine工程框架图
统一配置 + 标准接口:低门槛、高效率的开发体验
统一配置文件管理全流程(Unified):FluxVLA Engine采用 All-in-one 配置机制,通过单一配置文件,统一管理数据、模型、训练、评测、推理与部署参数。用户无需维护多套脚本与配置,即可切换各类模型。
模块化设计,标准化输入输出(Modular): FluxVLA Engine的核心设计是将海量数据处理、模型调用与部署相关模块解耦,并以标准化接口贯穿全流程。无论更换数据集、替换模型,还是从仿真切换到真机,格式与接口均可保持一致,无需重复适配。用户可以在不修改训练逻辑的情况下,单独替换视觉编码器、语言主干或动作头,也可以接入自定义数据集或新硬件平台,各模块之间互不干扰,便于灵活构建属于自己的VLA模型。
开箱即用的真机部署(Deployable):训练完成后的模型可直接导出,并通过标准化流程部署到真实机器人平台。
📎0bc3hucraaafhmanoio2tzuvkpodca6qkeaa.f10002.mp4
使用示例:半小时即可跑通训练流程
从 VLM 到 VLA,从仿真到真机,全功能覆盖
支持 VLM 与 VLA 全栈任务:原生支持视觉语言模型(VLM)和视觉语言动作模型(VLA),兼顾感知理解与动作训练。训练-仿真评测-真机部署均在同一框架完成,无需切换工具。



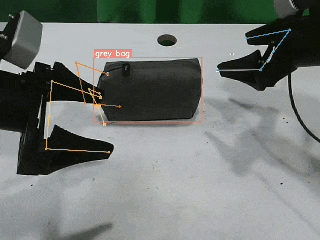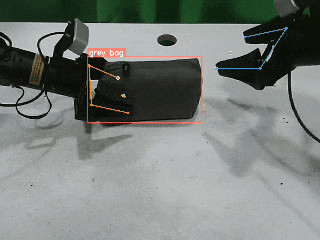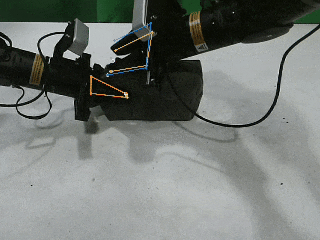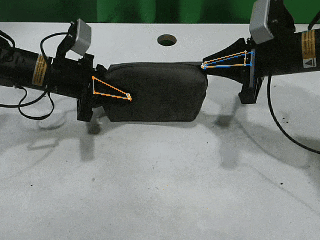
包括视觉跟踪、感知、精细化操作在内的多种训练模型
接入主流模型与仿真器:模型层统一接口,全面支持各类主流 VLM/VLA/WAM模型(如Qwen、GR00T、Pi全系列以及DreamZero等);仿真层无缝接入 Isaac Sim、LIBERO 等主流仿真器,告别繁琐的环境配置。

FLuxVLA Engine在LIBERO中的性能
兼容多元真机硬件:支持包括 UR 机械单臂、ALOHA 双臂系统,以及逐际动力自研多形态具身机器人TRON 2 等在内的多硬件平台,装上就能用!未来还会支持更多硬件。

FLuxVLA Engine可一键部署在多种真机硬件平台上
面向真实部署的系统优化:不仅能跑,更能稳定运行
推理加速:通过底层推理引擎优化和算子融合,FluxVLA Engine 实现了5-10倍推理速度提升,让机器人可以更快地响应环境变化,实现更流畅的实时控制。

轨迹平滑:FluxVLA Engine 集成了实时控制(RTC)等最新的轨迹平滑方法,有效规避模型输出的动作轨迹抖动,确保真机部署后机器人执行动作稳定、流畅。
持续迭代,共建开放生态,加速具身智能走向物理世界
FluxVLA Engine 源自逐际动力在具身智能和通用机器人研发和工程交付中的长期积累,是一套经过反复验证的基建设施。面向具身智能持续演进的技术浪潮,逐际动力不仅开源 FluxVLA Engine,更将以企业级的资源与服务来进行维护与迭代,目标是将其从工程平台发展为一个开放的具身智能技术生态平台。
未来,陆续集成更多先进方法,包括:
强化学习(RL):支持结合强化学习的 VLA 训练范式,让机器人在交互中持续优化自身行为。
世界模型(World Models):更多元的世界模型,让机器人能够对未来状态进行预测与规划,提升复杂任务的泛化能力。
构建开源社群:构建全球开发者社群,共同将最新研究成果(如灵巧手、基于 3D 的 VLA 等)融入 FluxVLA Engine,让平台生长成为不断焕发生命力的生态系统。
点击直达模型链接https://modelscope.cn/models/LimXDynamics/FluxVLAEngine



