
近日LLaDA 2.0 系列的首个多模态 MoE 模型LLaDA2.0-Uni正式开源。LLaDA2.0-Uni 是统一的离散扩散大语言模型(dLLM),专为原生多模态理解与生成而设计。
核心突破:不同于常规的自回归路径,LLaDA2.0-Uni 采用全离散扩散建模,彻底打破了文本单向生成与图像全局扩散之间的底层范式壁垒,为构建视觉-语言原生统一的多模态架构提供了全新的解法。
全能表现:一个模型,搞定一切。无论是图像理解、图像生成还是图像编辑,LLaDA2.0-Uni 在三大领域均已达到统一模型的领先水准。


全面开源:
GitHub:https://github.com/inclusionAI/LLaDA2.0-Uni
模型
Hugging Face:https://huggingface.co/inclusionAI/LLaDA2.0-Uni
ModelScope:https://modelscope.cn/models/inclusionAI/LLaDA2.0-Uni
论文:
https://arxiv.org/abs/2604.20796
架构设计
LLaDA2.0-Uni 采用 LLaDA-2.0-mini 作为 dLLM 骨干网络,这是一个总参数量为 16B 的 MoE 模型。模型架构具体设计:
- 极简统一离散扩散建模:
依托 LLaDA 2.0 的 MoE 基座,将多模态理解与生成任务深度整合为统一的分块掩码预测(block-wise mask prediction)范式。通过纯粹的掩码预测目标进行全离散扩散建模,彻底打破了传统多模态模型对自回归(AR)范式的依赖,并原生具备并行解码的极速推理优势。
- 语义离散视觉表征:
彻底摆脱传统 VQ 方法依赖像素重建的局限,将图像转化为纯粹的语义离散 Token。通过将旋转位置编码(RoPE)与灵活的尺寸设计巧妙结合,在实现零架构改动的前提下,原生解锁了对任意分辨率的完美支持。
- 极致高效的定制化 Diffusion Decoder:
为语义离散 Token 专属设计了高保真 Diffusion Decoder。配合少步蒸馏技术大幅优化解码效率,仅需 8 步推理即可实现高质量、细节丰富的视觉生成。


LLaDA2.0-Uni 性能表现解析
多模态理解能力 在多模态理解方面,LLaDA2.0-Uni 在 21 个权威基准上表现优异,在通用 VQA、逻辑推理与 OCR/文档理解三大核心场景中均表现出顶尖水准,性能足以媲美专有视觉语言模型(VLMs)。
- 通用与复杂推理:
综合实力基准 MMBench-EN 高达 81.5 分,通用 VQA 任务 MMStar 斩获 64.1 分,数学推理 MathVista-mini 达 68.1 分。
- 高难度视觉解析:
面对复杂的排版与文字,DocVQA 取得 89.5 分的优异成绩,OCRBench 达到 75.7 分,展现了精准的细粒度特征捕捉能力。


图像生成能力 我们通过多维度的测试(通用生成、文字渲染、基于推理的生成)对 LLaDA 2.0-Uni 进行了全面评估。模型展现出超越强基线的卓越表现:
- 语义对齐:
在通用基准中展现了强大的组合生成实力。其 GenEval上获得0.89的分数,并在DPG-Bench 斩获 87.76 高分。在UniGenBench以及One-IG-En评测榜单上也位于前列。
- 文本渲染:
在极具挑战的 CVTG-2K 评测中取得 0.765 分,并在多区域复杂文本生成中保持了极高的稳定性。
- 推理类生成:
在开启“思维链生成模式”后,模型在 WISE-Bench 上的得分达到 0.78,生动印证了逻辑前置对复杂图像生成质量的显著提升。


图像编辑能力 在图像编辑领域,LLaDA 2.0-Uni 展现了极高的稳定性与超强的能力:
- 高保真双语响应:
在 GEdit 基准测试中,中英文指令(英 6.61 / 中 6.66)均获得高分。特别是在“感知质量”子项表现强劲,证明了模型具备在完美保留原图视觉质感的前提下,精准执行编辑指令的“无损级”修改能力。
- 多参考复杂编辑:
在极度考验多图能力的 MICo-Bench 评测中获得 47.1 分,成功超越现有基线模型。
进阶能力:从「理解与生成」到「推理与思考」
思维链生成(Chain-of-Thought Generation) 多模态大模型不应只是被动的“画笔”,更应是具备逻辑的“创作者”。LLaDA2.0-Uni具备“先思考,再生成”的底层能力。这意味着,生成图像不再是简单的像素概率堆砌,而是一场经过严密推演的创作过程。
在推理类多模态生成基准 WISE-Bench 上,LLaDA2.0-Uni 常规状态下便展现出 0.68 的强劲竞争力;而值得一提的是,当引入“思维链生成”后,模型性能直接迎来了额外 10% 的显著跃升,综合得分飙升至 0.78。
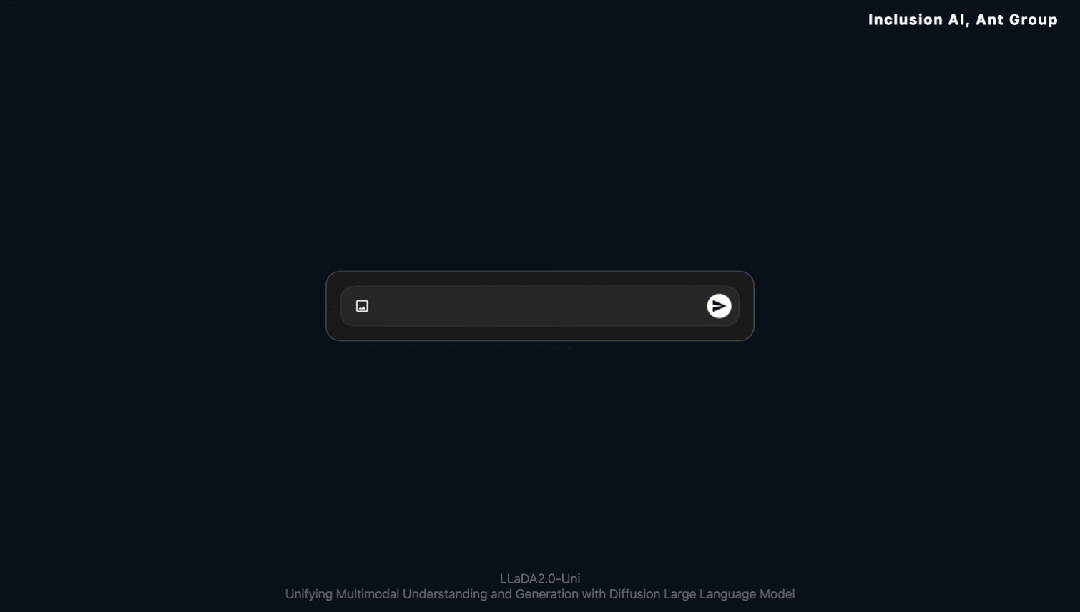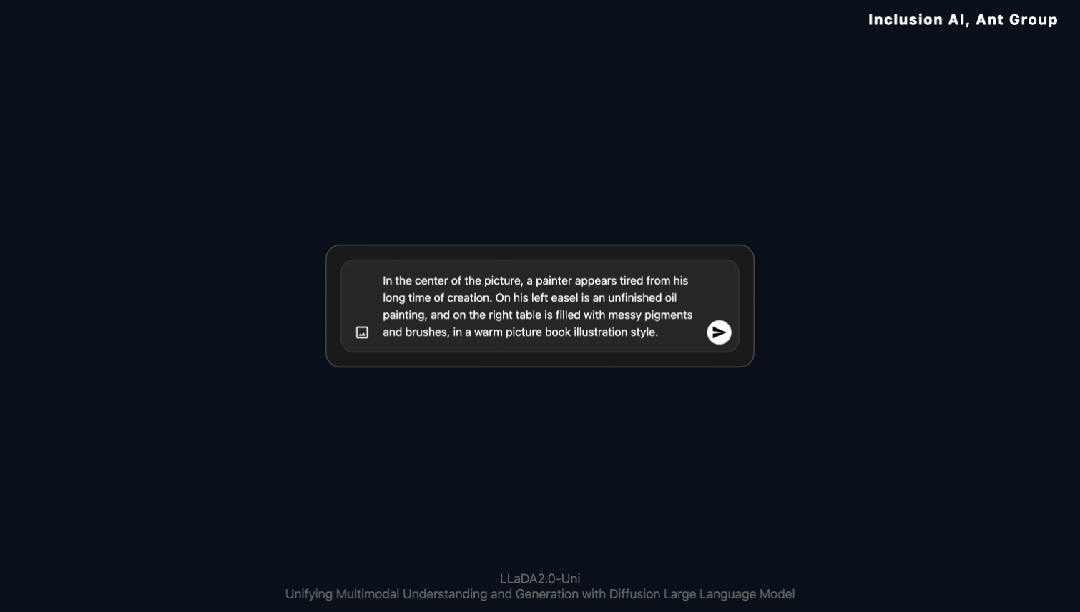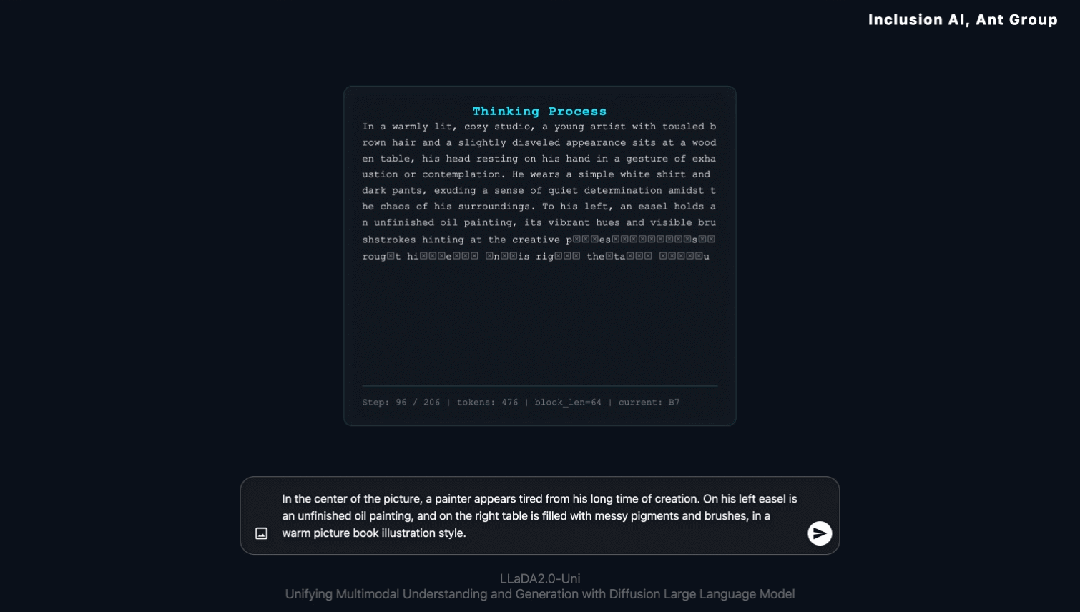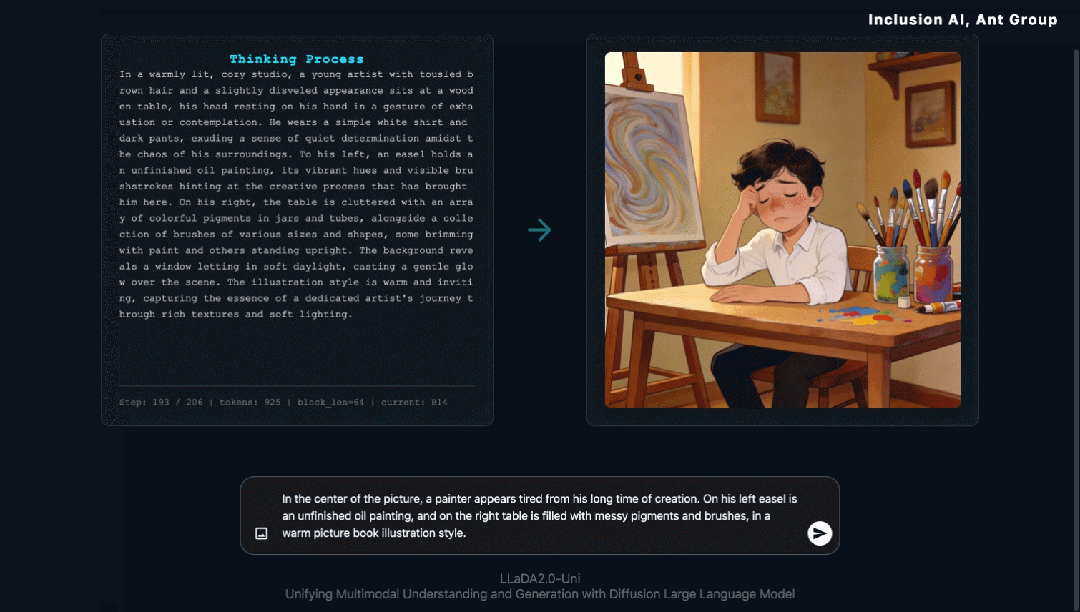

交错生成与推理(Interleaved Generation & Reasoning) 尽管目前许多统一模型已初步具备图文交错生成(Interleaved Generation)的能力,但这往往局限于形式上的“图文排版”。如何在此基础上,利用图文交错推理来解决复杂的逻辑问题,不仅是下一代多模态大模型的核心演进方向,更是实现“理解与生成”相互促进、闭环演进的关键途径。
LLaDA2.0-Uni 在该方向上迈出了重要一步,它可以在逻辑推演的过程中,自发地生成中间态的图像来辅助认知与表达,真正实现了从“形式上的交错”向“认知深度上的交错”的跨越。


总结
LLaDA2.0-Uni 代表了多模态模型的新范式。通过离散扩散架构,它实现了单一训练目标下的理解与生成统一,并为图文交错生成与深度推理打下了坚实的底层基石。研究团队正在将 LLaDA2.0-Uni 与高性能推理框架 SGLang 进行深度集成以进一步加速推理,将很快面向社区。期待与社区一起,推动下一代统一基础模型的发展。
https://github.com/inclusionAI/LLaDA2.0-Uni
 魔搭社区672 搭子 · 509 讨论 圈子
魔搭社区672 搭子 · 509 讨论 圈子




