一文讲懂扩散模型

扩散模型(Diffusion Models, DM)是近年来在计算机视觉、自然语言处理等领域取得显著进展的一种生成模型。其思想根源可以追溯到非平衡热力学,通过模拟数据的扩散和去噪过程来生成新的样本。以下将详细阐述扩散模型的基本原理、处理过程以及应用。
一、扩散模型的基本原理
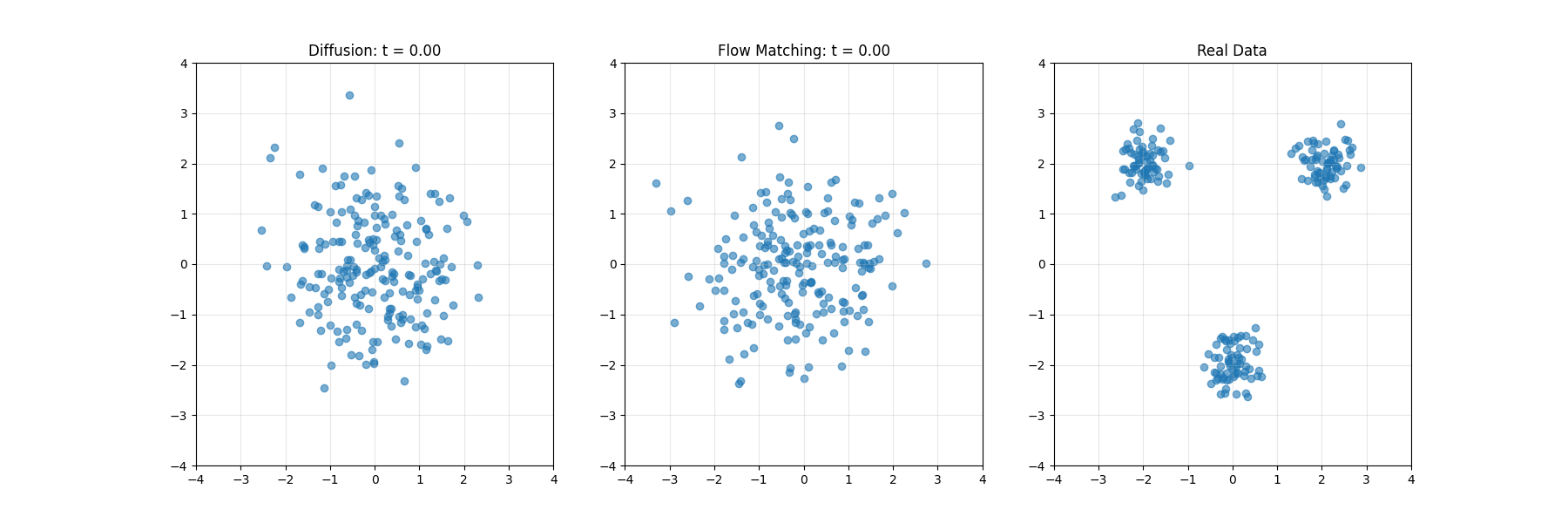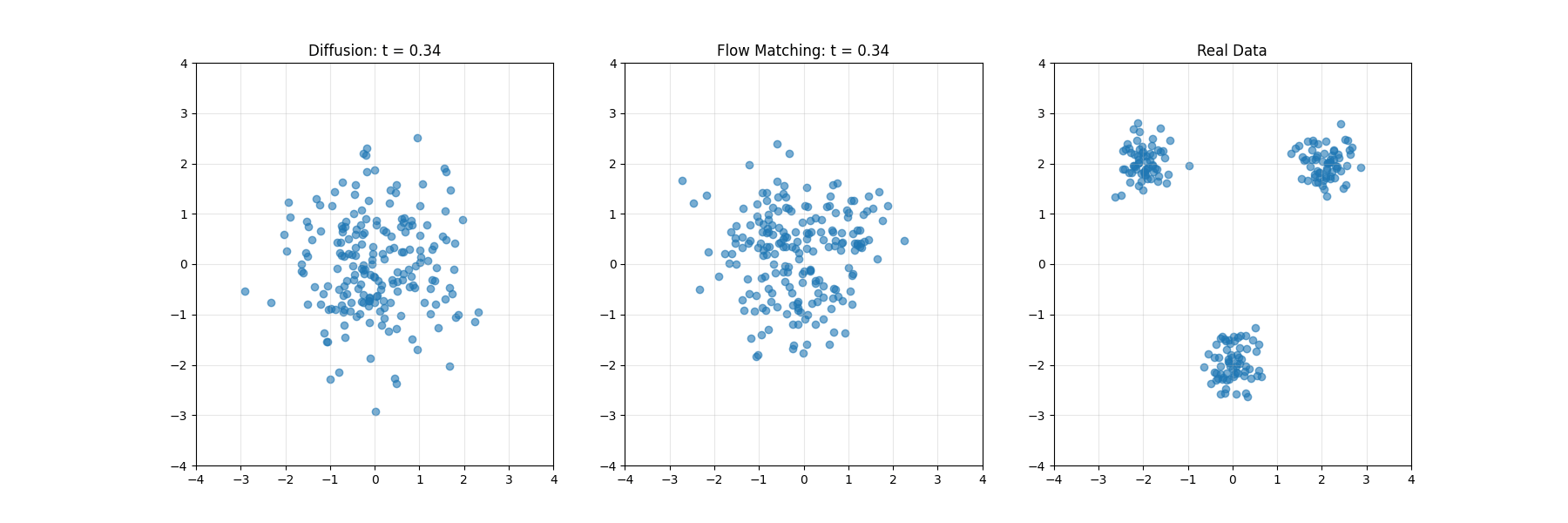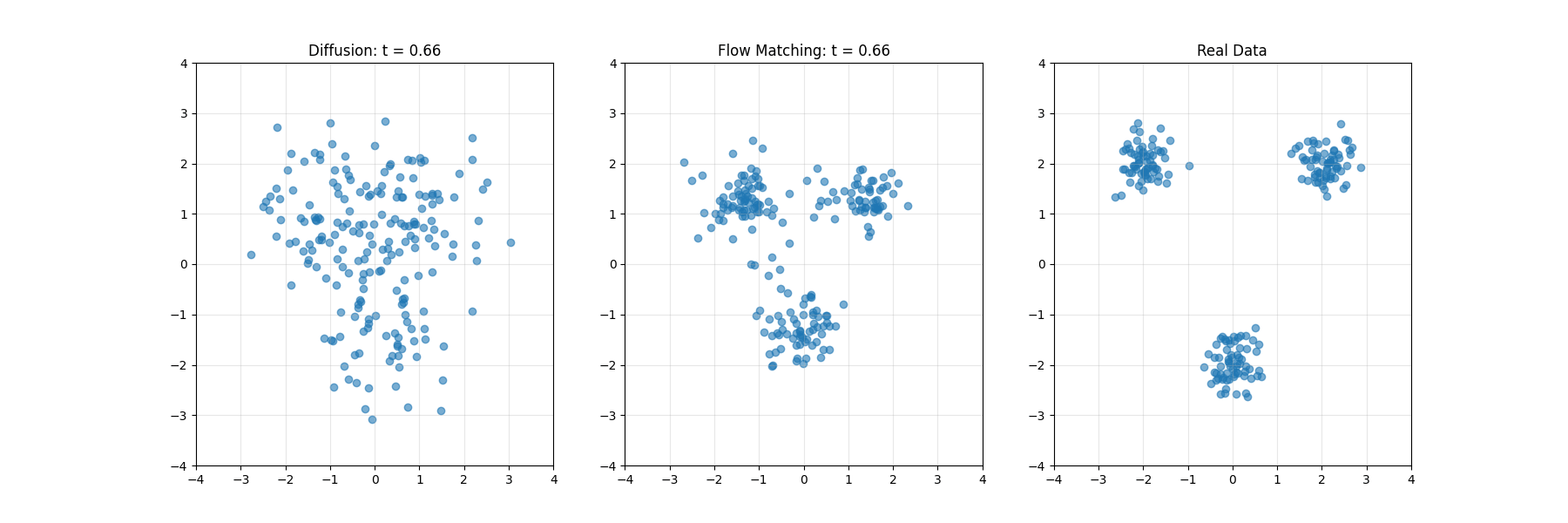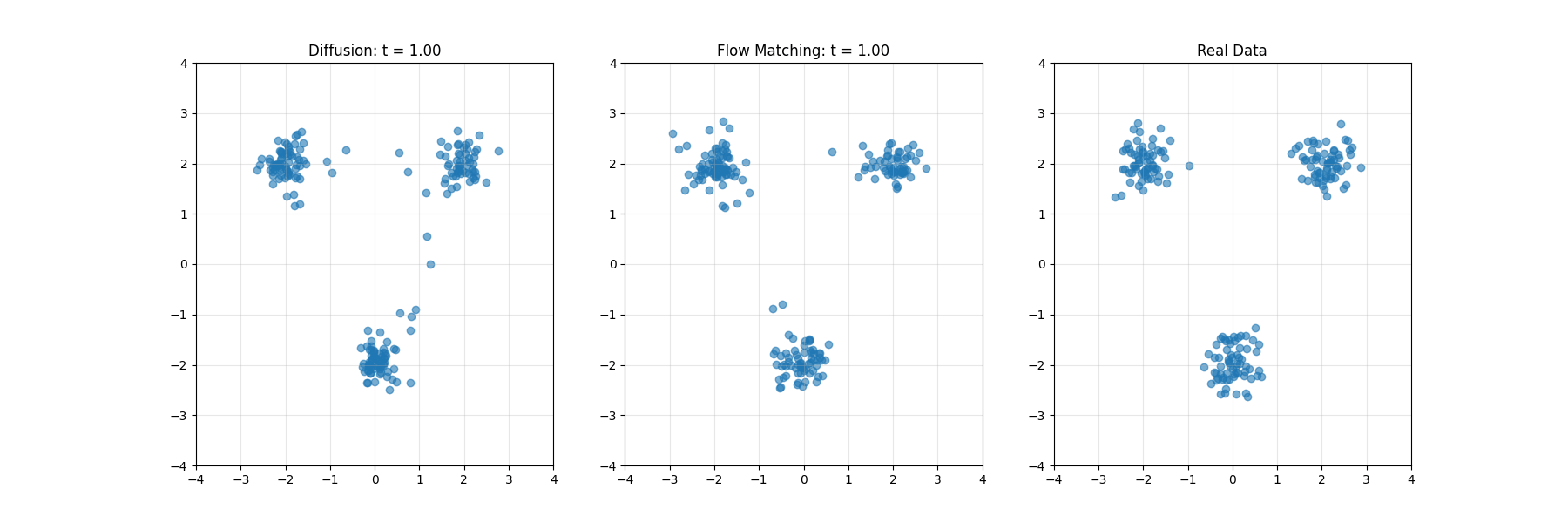
扩散模型的核心思想分为两个主要过程:前向扩散过程(加噪过程)和逆向扩散过程(去噪过程)。
前向扩散过程:
- 在这个过程中,模型从原始数据(如图像)开始,逐步向其中添加高斯噪声,直到数据完全变成纯高斯噪声。这个过程是预先定义的,每一步添加的噪声量由方差调度(Variance Schedule)控制。
- 数学上,这一过程可以表示为:$x_t = \sqrt{1 - \betat}x{t-1} + \sqrt{\beta_t}\epsilon$,其中$x_t$是$t$时刻的数据,$\beta_t$是控制噪声量的参数,$\epsilon$是从标准正态分布中采样的噪声。
逆向扩散过程:
- 逆向过程则是前向过程的逆操作,即从纯高斯噪声开始,逐步去除噪声,最终还原出原始数据。这个过程通常通过一个参数化的神经网络(如噪声预测器)来实现,该网络学习如何预测并去除每一步加入的噪声。
- 数学上,逆向过程可以表示为条件高斯分布:$p\theta(x{t-1}|xt) = \mathcal{N}(x{t-1};\mu_\theta(xt, t), \Sigma\theta(xt, t))$,其中$\mu\theta$和$\Sigma_\theta$是由神经网络预测的均值和方差。
二、扩散模型的处理过程
扩散模型的处理过程可以分为训练阶段和推理(生成)阶段。
训练阶段:
- 在训练阶段,模型通过前向扩散过程得到一系列加噪后的数据样本,并使用这些样本及其对应的原始数据来训练噪声预测器。训练目标是最小化预测噪声与实际噪声之间的均方误差(MSE)。
- 通过变分推断(Variational Inference)技术,模型学习如何逆转前向扩散过程,即从加噪数据中恢复出原始数据。
推理(生成)阶段:
- 在推理阶段,模型从标准高斯分布中随机采样一个噪声向量,然后通过逆向扩散过程逐步去除噪声,最终生成一张清晰的图像或其他类型的数据样本。
- 推理过程需要多次迭代,每次迭代都使用噪声预测器来预测并去除当前数据中的噪声,直到生成满足要求的数据样本。
三、扩散模型的应用
扩散模型因其强大的生成能力,在多个领域得到了广泛应用,包括但不限于:
图像生成:
- 扩散模型可以生成高质量、多样化的图像样本,在艺术创作、图像编辑等领域具有广泛应用前景。
- 代表性的模型如OpenAI的DALL-E 2和Stability.ai的Stable Diffusion等,已经展示了令人惊叹的图像生成能力。
视频生成:
- 扩散模型也被应用于视频生成领域,通过模拟视频帧之间的连续性和复杂性来生成高质量的视频样本。
- 灵活扩散模型(FDM)等研究成果表明,扩散模型在视频生成方面具有巨大潜力。
自然语言处理:
- 扩散模型的思想也被引入到自然语言处理领域,用于文本生成等任务。通过模拟文本数据的扩散和去噪过程来生成流畅的文本样本。
其他领域:
- 扩散模型还被应用于波形生成、分子图建模、时间序列建模等多个领域,展示了其广泛的应用前景和强大的生成能力。
四、代码实战
以下是一个基于Python和PyTorch的扩散模型(Diffusion Model)的简单代码实战案例。这个案例将展示如何使用扩散模型来生成手写数字图像,这里我们使用的是MNIST数据集。
- 扩散模型还被应用于波形生成、分子图建模、时间序列建模等多个领域,展示了其广泛的应用前景和强大的生成能力。
首先,确保你已经安装了必要的库:
pip install torch torchvision
接下来是代码部分:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 超参数设置
batch_size = 128
num_epochs = 50
learning_rate = 1e-3
num_steps = 1000 # 扩散过程的步数
beta_start = 0.0001
beta_end = 0.02
# 定义beta调度(线性调度)
betas = np.linspace(beta_start, beta_end, num_steps, dtype=np.float32)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 定义简单的神经网络(噪声预测器)
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 1000)
self.fc2 = nn.Linear(1000, 1000)
self.fc3 = nn.Linear(1000, 784)
self.relu = nn.ReLU()
def forward(self, x, t):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x # 输出预测的噪声
# 初始化模型、优化器和损失函数
model = SimpleNN().to('cuda')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 训练过程
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, _) in enumerate(train_loader):
data = data.view(data.size(0), -1).to('cuda')
# 随机时间步t
t = torch.randint(0, num_steps, (data.size(0),), device='cuda')
# 前向扩散过程(只计算一次,实际中可能需要存储所有时间步的数据)
noise = torch.randn_like(data).to('cuda')
x_t = torch.sqrt(alphas_cumprod[t]) * data + torch.sqrt(1 - alphas_cumprod[t]) * noise
# 预测噪声
pred_noise = model(x_t, t.float().unsqueeze(1))
# 计算损失(与真实噪声的均方误差)
loss = criterion(pred_noise, noise)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {batch_idx}/{len(train_loader)}, Loss: {loss.item()}')
# 生成过程(推理)
model.eval()
with torch.no_grad():
# 从标准高斯分布中采样初始噪声
x = torch.randn(16, 784, device='cuda') # 生成16张图像
for step in range(num_steps, 0, -1):
t = (torch.ones(16) * (step - 1)).long().to('cuda') # 当前时间步
# 预测噪声(实际中需要使用更复杂的策略来逐渐减小噪声)
pred_noise = model(x, t.float().unsqueeze(1))
# 逆向扩散步骤(这里简化了方差的处理)
beta_t = betas[step - 1]
alpha_t = alphas[step - 1]
x = (x - torch.sqrt(1 - alphas_cumprod[step - 1]) * pred_noise) / torch.sqrt(alphas_cumprod[step - 1])
# 添加适量的噪声以保持生成过程的随机性(可选)
# x += torch.sqrt(beta_t) * torch.randn_like(x)
# 将生成的图像转换回像素值范围并可视化
x = (x + 1) / 2.0 # 因为数据是归一化的,所以需要还原
x = x.cpu().numpy()
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(x[i].reshape(28, 28), cmap='gray')
ax.axis('off')
plt.show()
注意:
- 这个代码是一个简化的示例,实际的扩散模型实现可能会更复杂,包括更复杂的网络结构、更精细的调度策略以及更高效的采样方法。
- 在生成过程中,我简化了逆向扩散步骤中的方差处理,并且没有添加额外的噪声。在实际应用中,可能需要更仔细地处理这些细节以获得更好的生成结果。
- 由于计算资源和时间的限制,这个示例只训练了很少的次数,并且使用了简单的网络结构。在实际应用中,可能需要更多的训练时间和更复杂的网络来获得高质量的生成图像。
- 代码中使用了CUDA来加速计算,确保你的环境支持CUDA并且有可用的GPU。如果没有GPU,可以将代码中的
.to('cuda')替换为.to('cpu')来在CPU上运行。
总结
扩散模型作为一种新兴的生成模型,通过模拟数据的扩散和去噪过程来生成新的样本。其基本原理简单明了但背后蕴含着丰富的数学原理和优化技巧。随着研究的不断深入和应用场景的不断拓展,扩散模型有望在更多领域发挥重要作用并推动相关技术的发展进步。