免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

检索增强生成(Retrieval Augmented Generation, RAG)
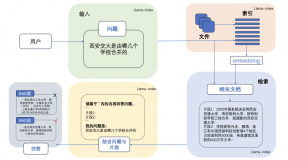
检索增强生成是指提供外部知识给大预言模型,对于用户提问,通过信息检索技术加载与问题相关的信息,LLM利用这些信息回答问题。下图是检索增强生成的简单示意图。检索增强生成可以解决大模型在以下四个方面的欠缺。

长尾知识
LLM的海量训练数据也无法覆盖所有知识,在有限的参数量下,LLM也无法完全记忆所有知识。实践证明,LLM对长尾知识回答的准确性相比于通用知识差不少。
数据时效性
训练数据中不包含未来的事实,LLM的知识存在过时的情况。
私有数据
训练数据都是公开的数据,LLM没有未学习过的私有知识,如企业内部规章制度,特定领域业务知识等。
来源和可解释性
LLM的生成结果是不可解释的,没有来源和参考依据,使用检索增强的方式可以追溯到信息来源。
知识库构建
文档处理
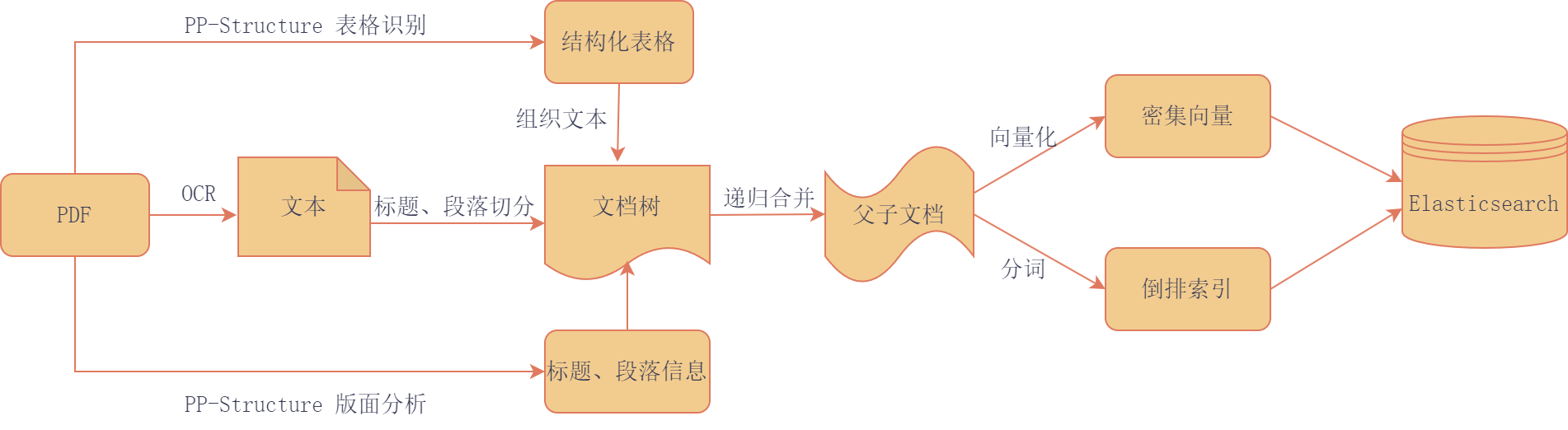
外部文档包括txt、pdf、word、html等格式,部分格式的数据是结构化的,可以比较完整地提取出文档的标题、段落、表格中的信息,如html、word;部分格式没有或无法识别到样式信息,是非结构化的,如pdf,txt,pdf中还可以包含图片、表格等信息。
知识库的质量是检索和生成的基础,文档切分需要尽可能保证知识的完整性和关联性。对于不同格式内容的文档,要采取不同的切分策略;由于向量模型和LLM输入长度的的限制,分块大小也是需要考虑的重要因素;文档的标题索引是对段落信息的浓缩,能提高跨段落问题的检索准确度。
规章制度主要是pdf文档。pdf内容的解析一直是业界的难题。由于pdf技术规范复杂,设计理念主要关注渲染结果,忽略了文档结构信息,机器无法准确识别文档的逻辑和语义结构。本文使用了基于规则和基于智能识别模型的方式提取pdf内容信息。
基于规则提取
对于按标题、章节、条目规范组织,有特定格式的文档可以使用基于正则表达式匹配的方式进行切分。首先对提取到的文本替换、删除特殊字符,按段落进行划分,匹配每个段落的章节条信息,组织成文档树的形式,每个叶子节点是文本段落,非叶子节点是标题,遍历整棵树,可以提取到文档的内容和结构信息,按照标题层级、块大小将叶子节点的文本段落合并为父文档,同时存储子文档和父文档,二者同时用于检索,最终返回上下文语义更完整的父文档。
由于各种文档格式多变,一些文档年限比较久远,实际处理过程中还有很多细节需要调整,部分文档难以达到理想的切分效果,但实际应用中对数据也没有严格的要求,该方案简单可行。
不规则文档处理
基于规则的切分方式无法处理标题组织个性化、pdf文字提取不完全的、包含表格、图片的文档,需要机器像人一样去识别文档结构,理解表格图片信息。
基于深度学习的PP-StructureV2是一个智能文档分析系统,支持对图片/pdf形式的文档进行版面分析,可以划分文字、标题、表格、图片、公式等区域,支持通用的中英文表格检测任务,表格区域进行结构化识别,最终结果输出Excel文件,在专门的数据集上进行训练后识别准确度更高。
多模态数据
除了最常见的各种格式文档外,外部数据还可能是多模态的,比如视频、音频、图片等格式,需要专门的多模态模型识别。
检索模块
使用Elasticseach进行全文检索和向量检索,对词汇和语义进行双路召回,对召回结果进行相关度重排,取评分最高的top k个文档片段,最终返回topk个语义更完整的父文档。
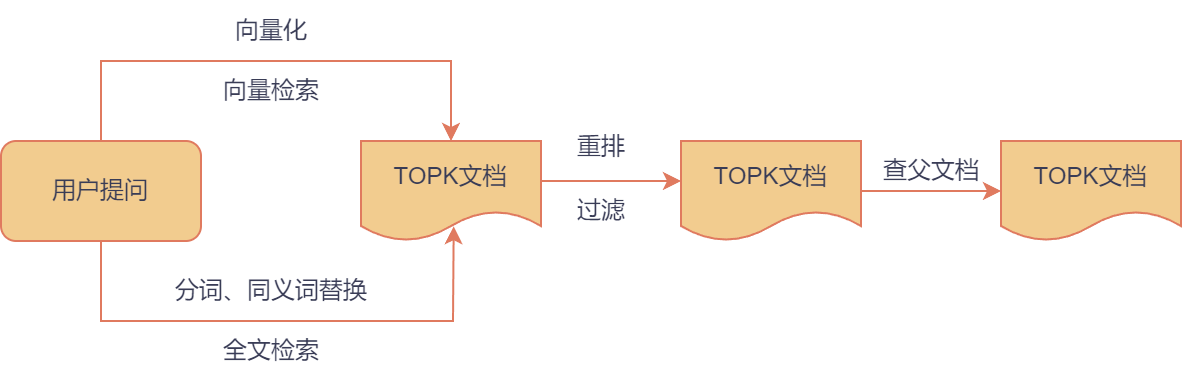
传统的相似语义判断是基于词汇匹配的,无法表示文本的内在特征。向量检索将文本表示为维度相同的特征向量,使用向量相似度度量的方式判断语义相关性。本文使用的向量模型来自MTEB(Massive Text Embedding Benchmark)评测榜单,并在专业数据上进行了微调,使用Elasticsearc的KNN向量检索,向量距离度量方式为点积,在检索速度和准确度方面都有不错的效果。
单一的查询实现简单高效,但受限于用户表达和模型能力,可能无法完全捕捉到用户意图返回完全的结果,可以使用LLM对用户问题生成多个相似的查询,对每组查询结果进行倒数融合排序(Reciprocal Rank Fusion)作为向量检索的结果。这种方式对LLM的基座能力有一定要求,需要生成多个有效的查询。
全文检索
基于概率的BM25检索算法是当前使用效果最好的算法之一,被广泛应用于信息检索领域。本文使用开源搜索分析引擎Elasticseach完成全文检索,其默认使用的算法就是BM25。文档切块之后,将标题、段落信息存入ES建立倒排索引,检索阶段对用户提问进行分词、去除停用词、同义词替换等处理,按BM25算法评分召回top k个段落。
分词策略、词库大小是影响检索准确度的重要因素,全文检索在一定程度上可以弥补向量检索在专业领域上的不足,因为向量模型的训练语料大多来自通用领域。
语义重排
对向量检索和全文检索的结果进一步进行相关度排序,使用重排模型对查询和答案计算相关性分数并重新排序,分数低于阈值直接过滤,重排后显著提高topk召回的准确率。
回答生成模块
对于检索出的topk个文本段落,尽可能多的在提示词中填充文本块,算力充足的情况下可以将问题和相关文本依次组合成提示词交给LLM总结、修正,最终生成准确的答案。
系统整个链路的耗时主要在此模块,LLM的推理需要大量显存和算力资源,可以考虑以量化方式或者推理加速框架部署模型。
为减少响应时间,可以根据用户对回答的满意度将命中的历史问题放入缓存,提高响应速度,减少资源占用。
结果分析
本文对基于检索增强生成的知识库问答系统进行了实践落地,对不同的检索策略、向量模型微调前后进行了对比分析。本系统在国产化和非国产化软硬件环境均进行了适配,能稳定运行。
检索策略对比
在2000多个测试问题上评估了各种检索策略的效果,在top1、top5和top10检索上,使用命中率和平均倒数排名(Mean Reciprocal Rank, MRR)两个评价指标评估检索效果。
测试问题来自LLM对每一个文档段落生成的问题——答案对,检索返回对应的原段落即为命中。由于切块效果和LLM能力限制,生成的部分问题可能并不合理,与文档段落的对应关系不一定准确,需要经过人工标注。
单一的向量检索效果一般,加入重排和全文检索后效果有明显提升,在top5准确度有80%,考虑到评测数据和计算方式,实际应用效果要优于这个值。

向量模型使用的是对比学习的训练方式,目标是由问题匹配段落,训练数据需要有问题、正例、负例,其中问题来自LLM生成的问题——答案对中的问题,正例即是对应的段落,负例通过检索问题并重排,依据相似度评分进行筛选生成。训练过程中为达到大的batch_size效果,需要开启梯度累加。
微调之后向量检索的准确率提升显著,提升近20%的准确率,但整体的检索效果提升在top10上只有3%。

不足与展望
基于规则和块大小的切片方法存在丢失语义,无法处理不规则文档,开源版面分析模型难以处理复杂文档;尝试更多的切块方法,尽可能保证语义的关联性和完整性,增加对复杂图片、复杂表格的处理,在自有数据集上进行版面分析模型的训练或微调。
向量模型和大语言模型正在持续发展,需要时刻关注,选择更优的向量模型,提升检索准确度;选用基座能力更强的LLM,提高总结回答能力。
专业词库小,查询向量单一;通过多向量查询、倒数融合排序、扩充词库等方式提升检索准确度。
人工标注数据,微调向量模型和大模型。
了解更多阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT