
8.1 基本概念
8.1.1 什么是目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
计算机视觉中关于图像识别有四大类任务:
- 分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位-Location:解决“在哪里?”的问题,即定位出这个目标的位置。
- 检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的位置并且知道目标物是什么。
- 分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标或场景”的问题。

8.1.2 目标检测要解决的核心问题
除了图像分类之外,目标检测要解决的核心问题是:
- 目标可能出现在图像的任何位置。
- 目标有各种不同的大小。
- 目标可能有各种不同的形状。
8.1.3 目标检测算法分类
基于深度学习的目标检测算法主要分为两类:
1、Two stage 目标检测算法
- 先进行区域生成(region proposal,RP)(一个有可能包含待检测的预选框),再通过卷积神经网络进行样本分类。
- 任务:特征提取→生成RP→分类/定位回归
- 常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R C-NN和R-FCN等。
2、One stage 目标检测算法
- 不用RP,直接在网络中提取特征来预测物体分类和位置。
- 任务:特征提取→分类/定位回归
- 常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。

8.1.4 目标检测有哪些应用
目标检测具有巨大的实用价值和应用前景。应用领域包括人脸检测、行人检测、车辆检测、飞机航拍或卫星图像中道路的检测、车载摄像机图像中的障碍物检测、医学影响在的病灶检测等。还有在安防领域中,可以实现比如安全帽、安全带等动态检测,移动侦测、区域入侵检测、物品看护等功能。
8.2 Two Stage 目标检测算法
8.2.1 R-CNN
R-CNN有哪些创新点
- 使用CNN(ConvNet)对region proposal 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
- 采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难训练甚至过拟合等问题。
注:ILSVRC其实就是众所周知的ImageNet的挑战赛,数据量极大;PASCAL数据集(包含目标检测和图像分割等),相对较小。
R-CNN 介绍
R-CNN作为R-CNN的系列的第一代算法,其实没有过多的使用“深度学习”的思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。

原论文中R-CNN pipeline只有4个步骤,光看上图无法深刻理解R-CNN的处理机制,下面结合图示补充相应文字:
1. 预训练模型。选择一个预训练(pre-trained)神经网络(如AlexNet、VGG)。
2. 重新训练全连接层。使用需要检测的目标重新训练(re-train)最后全连接层(connected layer)。
3. 提取proposals并计算CNN特征,利用选择搜索(Selective Search)算法提取所有proposals(大约2000幅images),调整(resize/wrap)它们成固定大小,以满足CNN输入要求(因为全连接层的限制),然后将feature map保存到本地磁盘。

4. 训练SVM。利用feature map训练SVM来对目标和背景进行分类(每一个类一个二进制SVM)。
5. 边界框回归(Bounding boxes Regression)。训练将输出一些校正因子的线性回归分类器。

R-CNN实验结果
R-CNN在VOC 2007测试集上mAP达到58.5%,打败当时所有的目标检测算法。

8.2.2 Fast R-CNN
Fast R-CNN有哪些创新点
- 只对整幅图像进行一次特征提取,避免R-CNN的冗余特征。
- 用Rol pooling层替换最后一层的max pooling层,同时引入建议框数据,提取相应建议框特征。
- Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练(建议框提取除外),也不需要额外的特征存储空间(R-CNN中的特征相需要保存到本地,来供SVM和Bounding-box regression进行训练)。
- 采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
Fast R-CNN 介绍
Fast R-CNN 是基于R-CNN和SPPnets进行的改进。SPPnets,其创新点在于计算整幅图像的the shared feature map,然后根据object proposal在shared feature map上映射到对应的feature vector(就是不用重复计算feature map)了。当然,SPPnets也有缺点:和R-CNN一样,训练是多阶段(multiple-stage pipeline)的,速度还是不够“快”,特征还要保存到本地磁盘中。
将候选区域直接应用于特征图,并使用Rol pooling将其转化为固定大小的特征图块。以下是Fast R-CNN的流程图:

Rol Pooling 层详解
因为Fast R-CNN使用全连接层,所以应用Rol Pooling将不同大小的ROI转换为固定大小。
Rol Pooling 是Pooling是一种,而且是针对Rol的Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定(如7x7).
什么是 Rol 呢
Rol是Region of Interest的简写,一般是指图像上的区域框,但这里指的是由Selective Search提取的候选框。

往往经过RPN后输出的不止一个矩形框,所以这里我们是对多个Rol进行Pooling。
Rol Pooling 的输入
输入有两部分组成:
- 特征图(feature map):指的是上面所示的特征图,在Fast RCNN中,它位于Rol Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;
- Rols:其表示所有的Rol的 N*5 的矩阵。其中N表示Rol的数量,第一列表示图像index,其余四列表示其余的左上角和右下角坐标。
在Faster RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框,形状为 1x5x1x1 (4个坐标 + 索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)。其实关于ROI的坐标理解一直很混乱,到底是根据谁的坐标来。其实很好理解,我们已知原图的大小和由Selective Search算法提取的候选框坐标,那么根据“映射关系”可以得出特征图(feature map)的大小和候选框在feature map上的映射坐标。至于如何计算,其实就是比值问题,下面会介绍。所以这里把ROI理解为原图上 各个候选框(region proposal),也是可以的。
注:说句题外话,由Selective Search 算法提取的一系列可能含有object的bounding box,这些通常称为region proposals 或者 region of interest(ROI)。
Rol 的具体操作
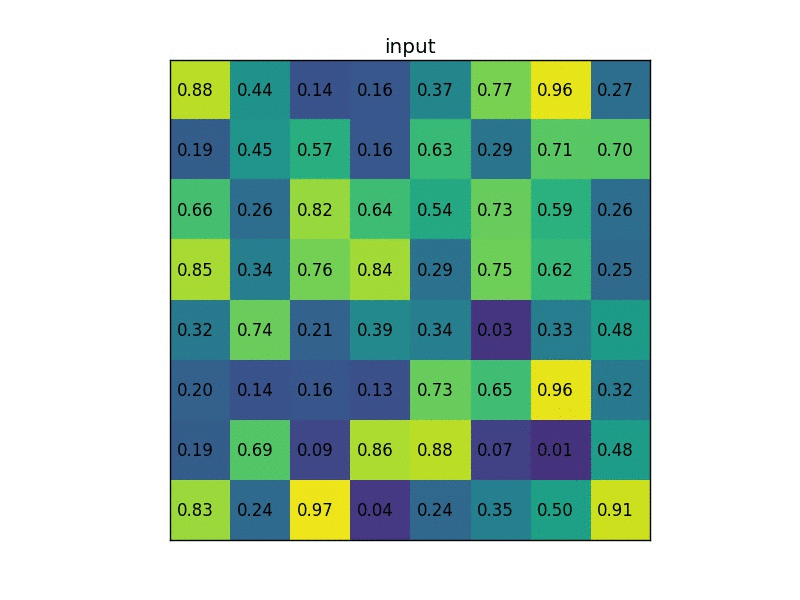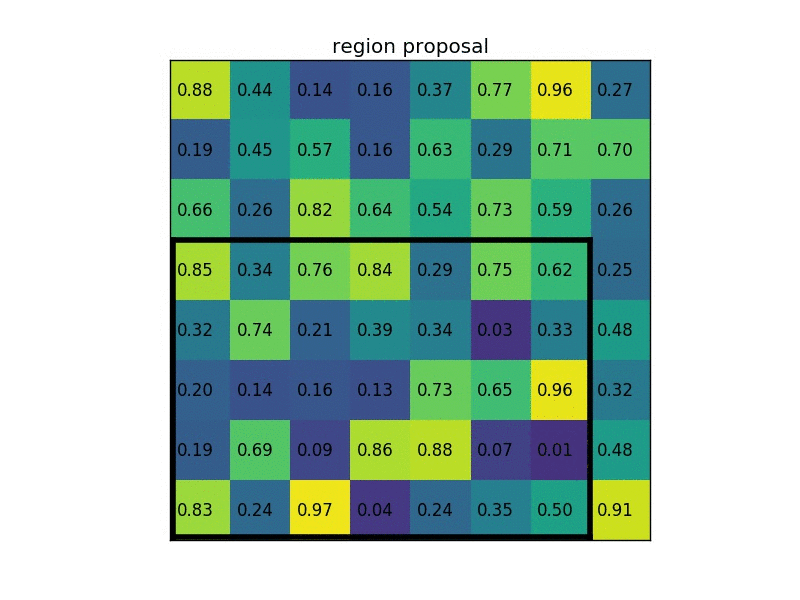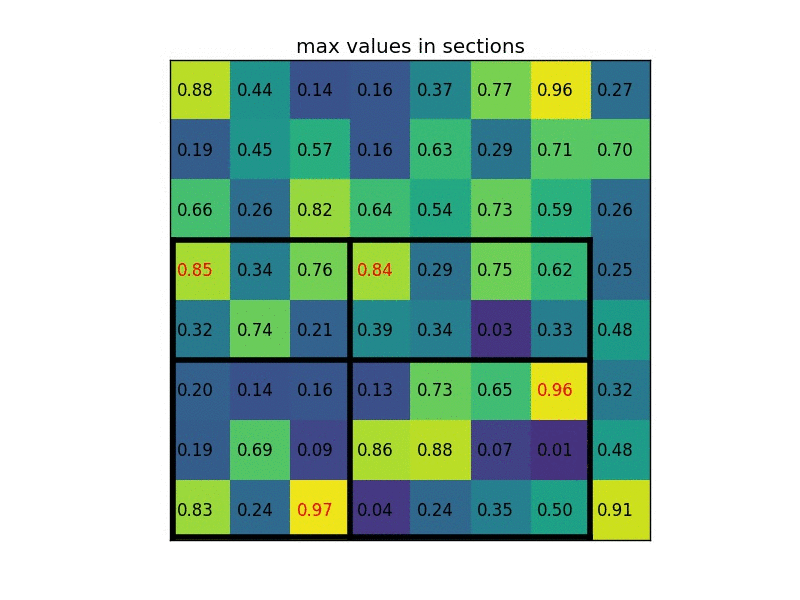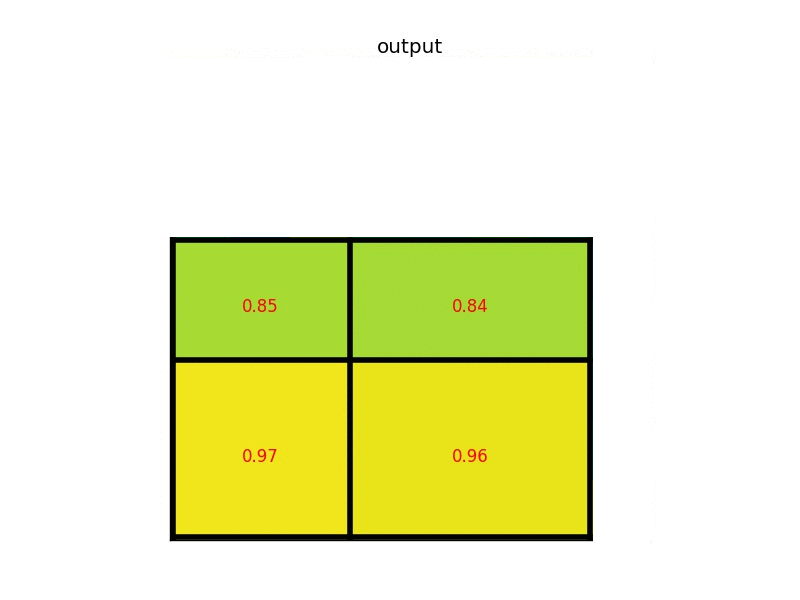
1. 根据输入image,将ROI映射到feature map对应位置
注:映射规则比较简单,就是把各个坐标除以“输入图片与feature map的大小的比值”,得到了feature map上的box坐标。
2. 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同)。
3. 对每个sections进行 max pooling 操作。
这样我们就i可以从不同大小的方框得到固定大小的相应的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。Rol Pooling最大的好处就在于极大地提高了处理速度。
Rol Pooling 的输出
输出是batch个vector,其中batch的值等于Rol的个数,vector的大小为channel * w * h;Rol Pooling的过程就是将一个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框。
Rol Pooling 的示例
8.2.3 Faster R-CNN
Faster R-CNN 有哪些创新点
Fast R-CNN依赖于外部候选区域方法,如选择性搜索。但这些算法在CPU上运行且速度很慢。在测试中,Fast R-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。Faster R-CNN采用与Fast R-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。

候选区域网络
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个 3x3的卷积核,以使用卷积网络(如下所示的ZF网络)构建与类别无关的候选区域。其他深度网络(如VGG或ResNet)可用于更全面的特征提取,但这需要以速度为代价。
ZF网络最后会输出256个值,它们将馈送到两个独立的全连接层,以预测边界框和两个objectness分数,这两个objectness分数度量了边界框是否包含目标。
我们其实可以使用回归器计算单个objectness分数,但为简洁起见,Faster R-CNN使用只有两个类别的分类器:即带有目标的类别和不带有目标的类别。

对于特征图中的每一个位置,RPN会做k次预测。因此,RPN将输出 4xk 个坐标和每个位置 2xk 个得分。
下图展示了 8x8的特征图,且有一个 3x3 的卷积核执行运算,它最后输出 8x8x3 个ROI(其中k=3)。下图(右)展示了单个位置的3个候选区域。

假设最好涵盖不同的形状和大小。因此,Faster R-CNN不会创建随机边界框。相反,它会预测一些与左上角名为锚点的参考框相关的偏移量(如x,y)。我们限制这些偏移量的值,因为我们的猜想仍然类似于锚点。

要对每个位置进行k个预测,我们需要以每个位置为中心的k个锚点。每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。

这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。这使得我们可以用更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。该策略使早期训练更加稳定和简便。

Faster R-CNN使用更多的锚点
它部署9个锚点框:3个不同宽高比的3个不同大小的锚点(Anchor)框。每一个位置使用9个锚点,每个位置会生成 2x9 个 objectness分数的 4x9 个坐标。

