K8s 事件简介
K8s 是基于状态机的设计,在不同状态之间迁移时会生成事件。正常的状态间转换会生成 Normal 事件,从正常状态转换为异常状态则会生成 Warning 事件。
使用 K8s 集群,我们关注业务、容器、集群三个层面稳定性,最基础的依赖是 K8s node 要稳定。可能影响 pod 运行的节点问题包括:
基础设施:ntp 服务不可用、网络故障等。
硬件:例如 CPU、内存、磁盘故障,使用 IaaS 会大大降低这类问题发生概率。
OS:Kernel deadlock,文件系统损坏等。
Container Runtime:例如 docker engine hang。
其它。
阿里云容器服务(ACK)提供开箱即用的容器场景事件监控方案,通过 NPD(node-problem-detector)以及 kube-eventer 提供容器节点的事件采集、存储能力。
NPD 是 K8s 集群节点异常事件监控组件,可以将 NPD 以 DaemonSet 或独立守护程序运行。用于监视和报告节点的健康状况,并将事件报告给 API Server。
kube-eventer 是 ACK 维护的 K8s 事件开源工具,可以将集群事件转储到钉钉、SLS、EventBridge 等系统,并提供不同等级的过滤条件,实现事件的实时采集、定向告警、异步归档。

阿里云日志服务(SLS)是云原生观测分析平台,为 Log/Metric/Trace 等数据提供大规模、低成本、实时平台化服务,支持数据采集、加工、分析、告警可视化与投递功能,帮助提升研发、运维、运营和安全等场景数字化能力。
使用 ACK 事件中心,设置 Sink 参数将 K8s 事件数据采集到 SLS,样例如下:
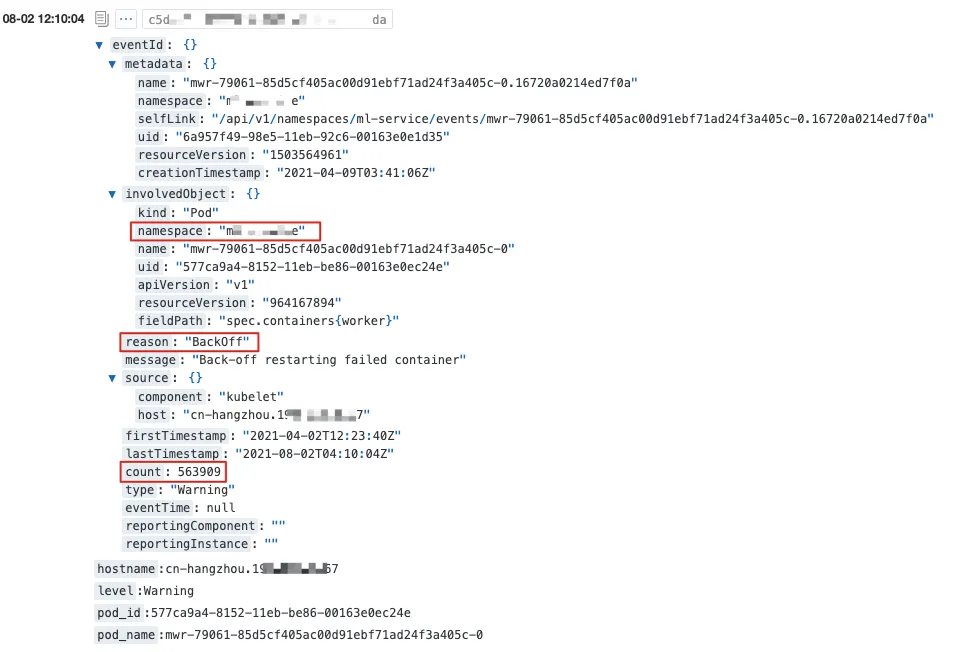
k8s.io/api/core/v1/types.go 对事件结构进行了定义,其中几个重要的字段是:
Message:当前操作对应状态的详细描述。
Reason:事件描述的简短枚举值。
Involved Object:事件所关联的对象,例如 Pod,Deployment,Node 等。
Source:汇报事件的模块,例如 kube-scheduler、kubelet 等。
Type:目前只有两种类型,Normal 或 Warning。
Count:事件发生的次数。
异常事件分析
以一个中型(~100 台) K8s 生产集群的为例,在 SLS 上通过 SQL 代码统计一天里 Pod 创建、启动次数的时间趋势:
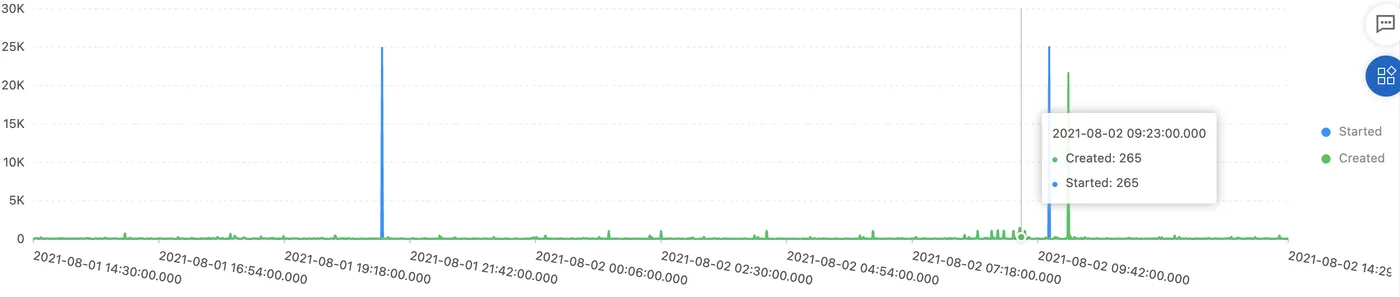
eventId.reason:Created or eventId.reason:Started | select from_unixtime(__time__ - __time__ % 60) as dt, "eventId.reason" as action, sum(cast("eventId.count" as bigint)) as event_count group by dt, action order by dt asc limit 10000看到会有 burst 情况,对于 K8s 集群稳定性是一个挑战:
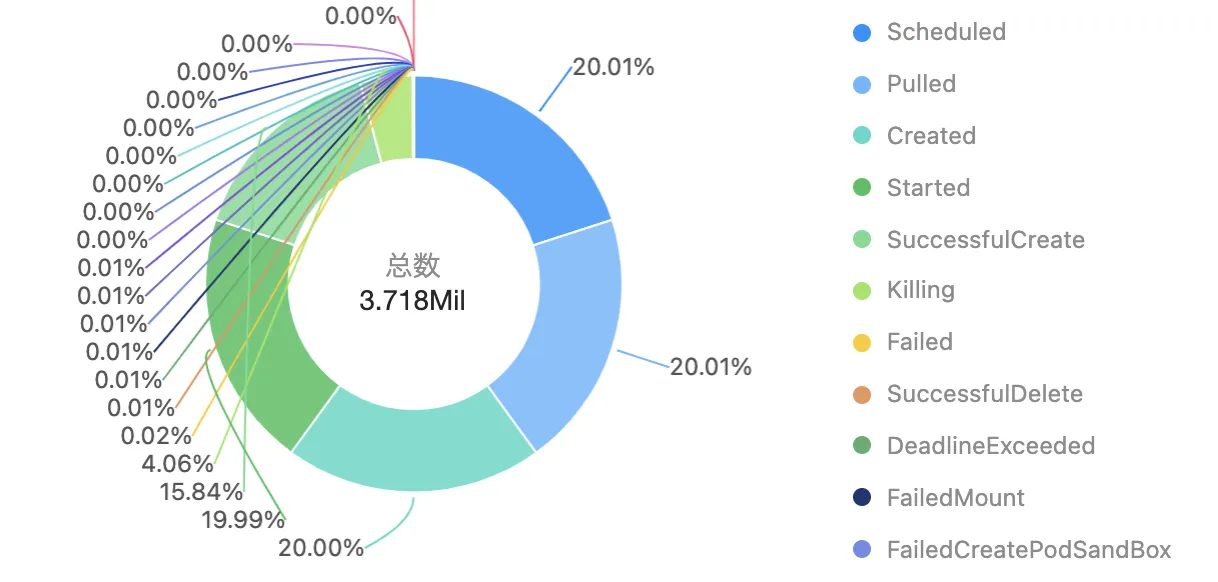
通过 SQL 代码统计不同事件类型关联的 Pod 数目分布:
* | select reason, count(DISTINCT "eventId.involvedObject.name") as object_count group by reason order by object_count desc limit 100发现有少量 Failed、DeadlineExceeded、FailedMount、FailedCreatePodSandBox 等异常事件,这些需要引起关注:
如何将这类事件分析操作变成一种常态化的工作,本文介绍一种周期性 SQL 计算方案。要实现:
优化事件中心长期存储(3个月以上)成本,对冷数据做降精度存储。
对长周期(例如时间跨度 1 个月以上)统计分析做响应延时优化,将全量数据计算拆分为多次增量计算。
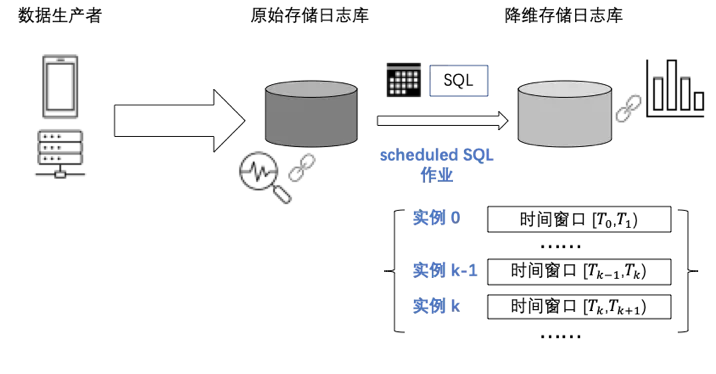
具体来说,是将 SQL 分析从控制台上的交互式操作转变为后台任务的周期性运行,得到一个个时间区间的统计值,将这些统计结果写入存储库,达到如下效果:
统计结果直接存储下来,可被多种下游系统直接使用,例如可视化大盘、告警监控、入库数仓等。
通过周期性计算任务相当于预先构建了 Cube,查询引擎在目标库的数据上计算,由于要处理的数据量大大降低,达到秒开的效果。
全量 K8s 事件随着时间推移,需要的存储量持续增加。在有了降维后的目标库数据后,如果不需要原文做问题调查,存储原文的日志库可以缩短存储周期。
Scheduled SQL 实践
Scheduled SQL 是一项由 SLS 全托管的功能,解决场景需求包括:
定时分析数据:根据业务需求设置 SQL 语句或查询分析语句,定时执行数据分析,并将分析结果存储到目标库中。
全局聚合:对全量、细粒度的数据进行聚合存储,汇总为存储大小、精度适合的数据,相当于一定程度的有损压缩数据。
本节演示通过 Scheduled SQL 完成对 K8s 异常事件的定时分析及结果存储。
分析预览
在 k8s-event 日志库上,过滤 Normal 级别事件,按照 namespace、object 类型、事件类型分组统计:关联的 object 数目、事件数目、关联的节点数目。
SQL 代码如下:
* not level : Normal | select "eventId.involvedObject.namespace" as namespace, "eventId.involvedObject.Kind" as kind, reason, arbitrary(message) as msg, count(DISTINCT "eventId.involvedObject.name") as object_count, sum(cast("eventId.count" as bigint)) as event_count, count(distinct hostname) as host_count group by namespace, kind, reason order by event_count desc在 SLS 控制台上分析预览:
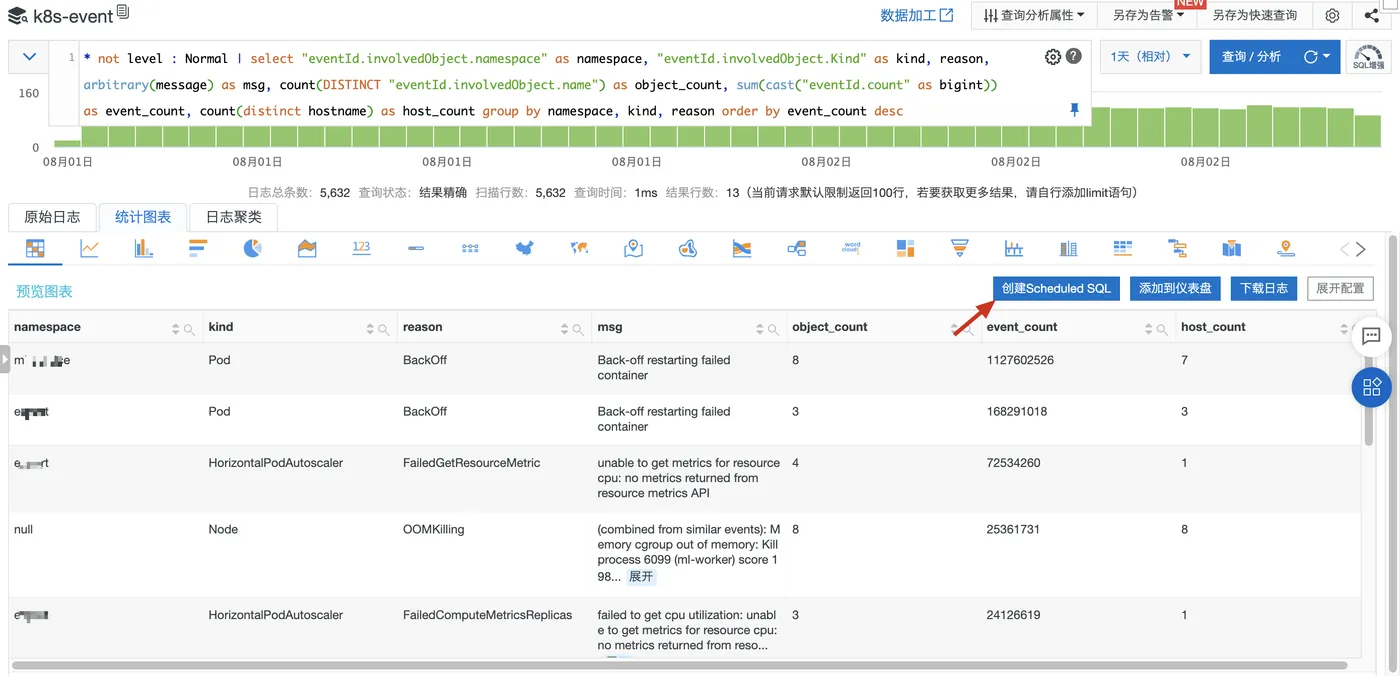
确认结果符合预期后,点击按钮创建 Scheduled SQL 作业。
计算配置
资源池有免费(Project 级别 15 并行度)、增强型(收费,但资源可扩展,适用于大量计算且有 SLA 要求的业务场景)两种,按照你的需求来设置即可。
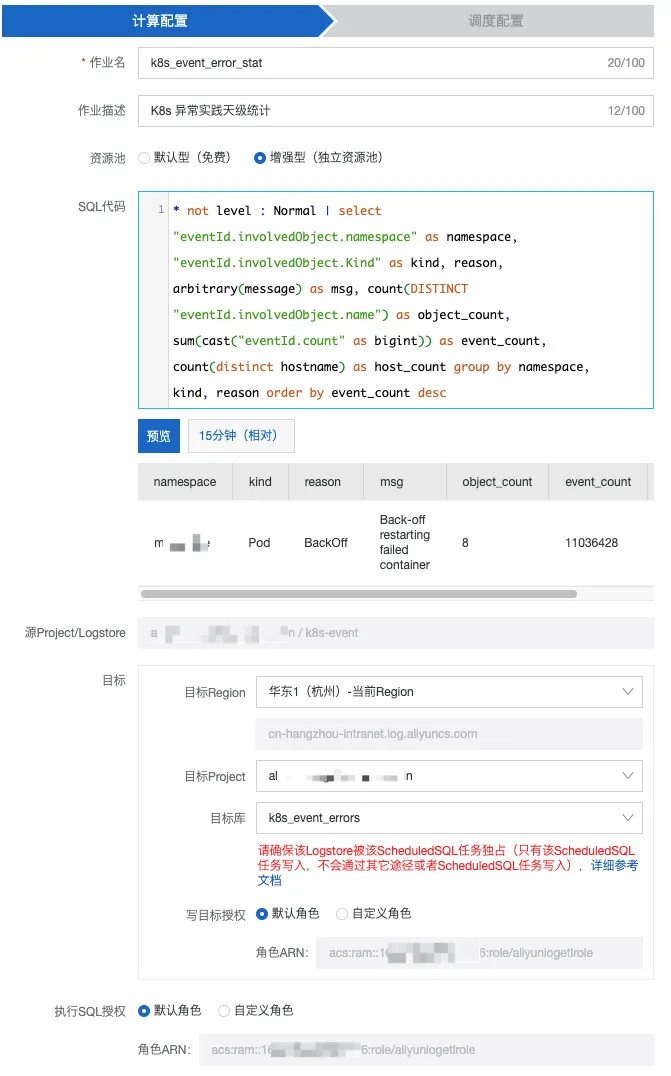
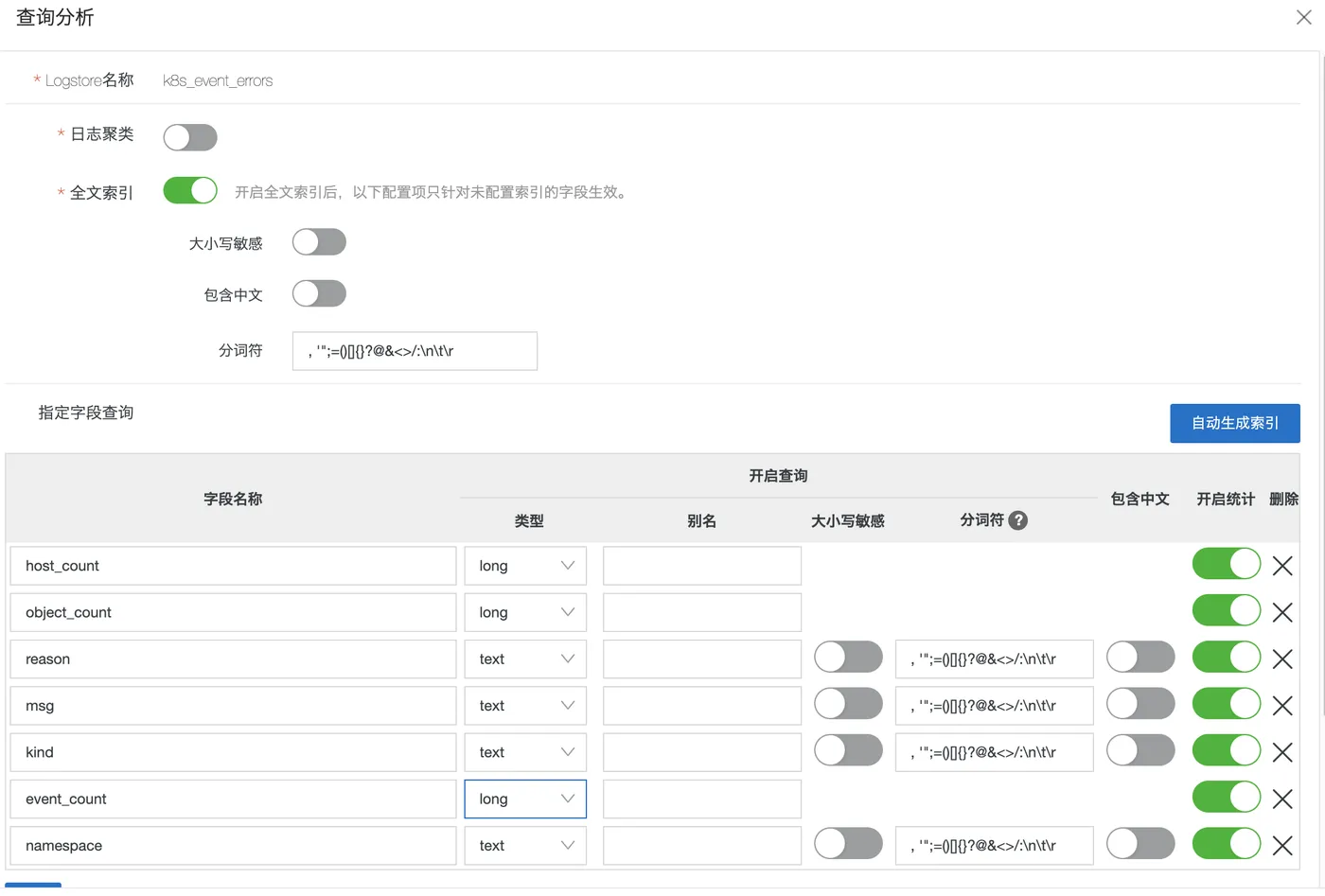
关于目标库(k8s_event_errors),注意提前为目标库准备好索引:
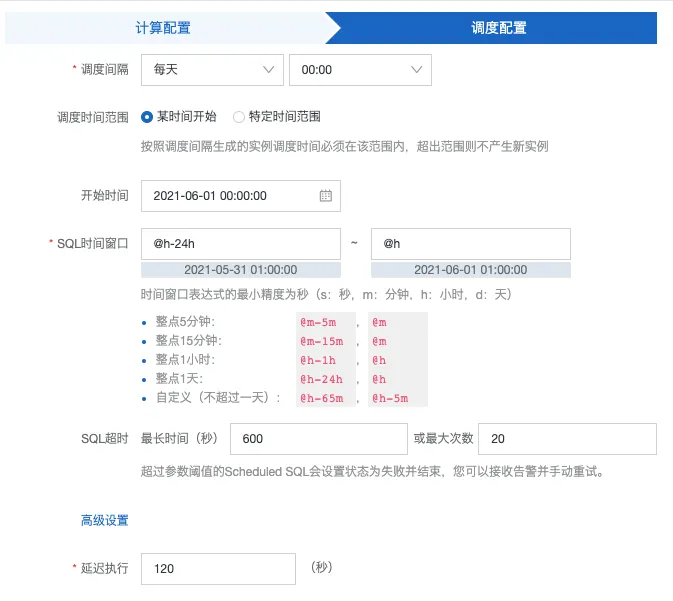
调度配置
设置 SQL 每天执行一次,查询前一天零点到当前零点时间窗口内的数据。因为上游事件数据到来可能延迟,这里设置 120 秒延迟等待来保证计算数据的完整性。
实例查看、管理
在控制台上查看刚才创建的 Scheduled SQL 作业,作业管理页面内可以查看到每一次执行的实例列表。
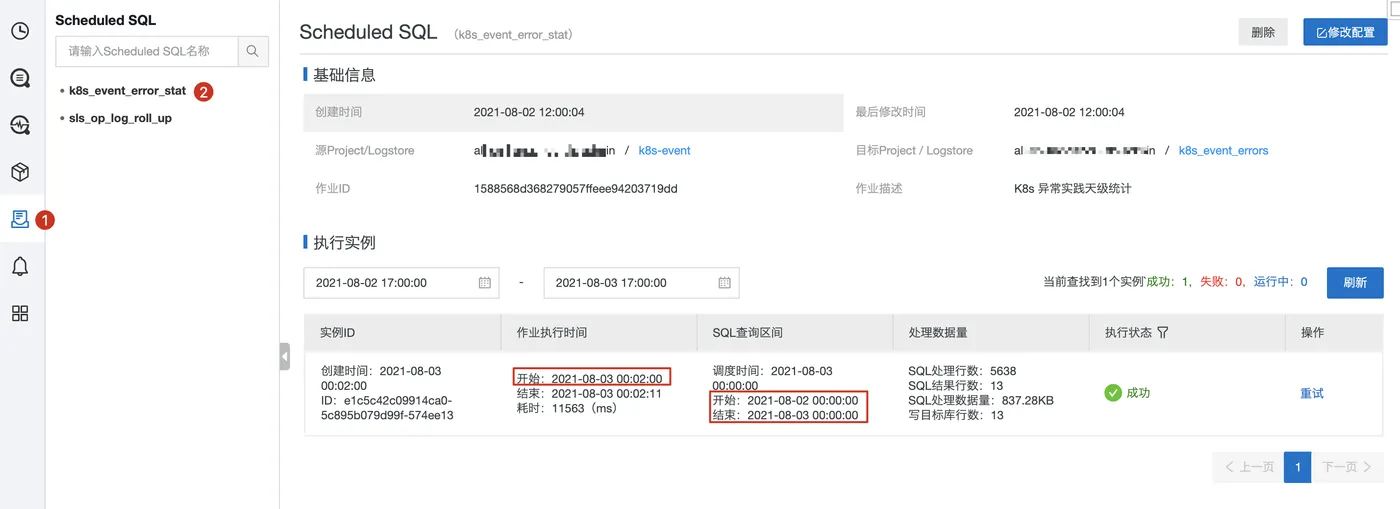
每个实例信息中有 SQL 查询区间,如果任务失败(权限、SQL 语法等原因)或 SQL 处理行数指标为 0(数据迟到或确实没有数据),可以对指定实例做重试。
效果
通过 Scheduled SQL 计算后的数据格式如下:
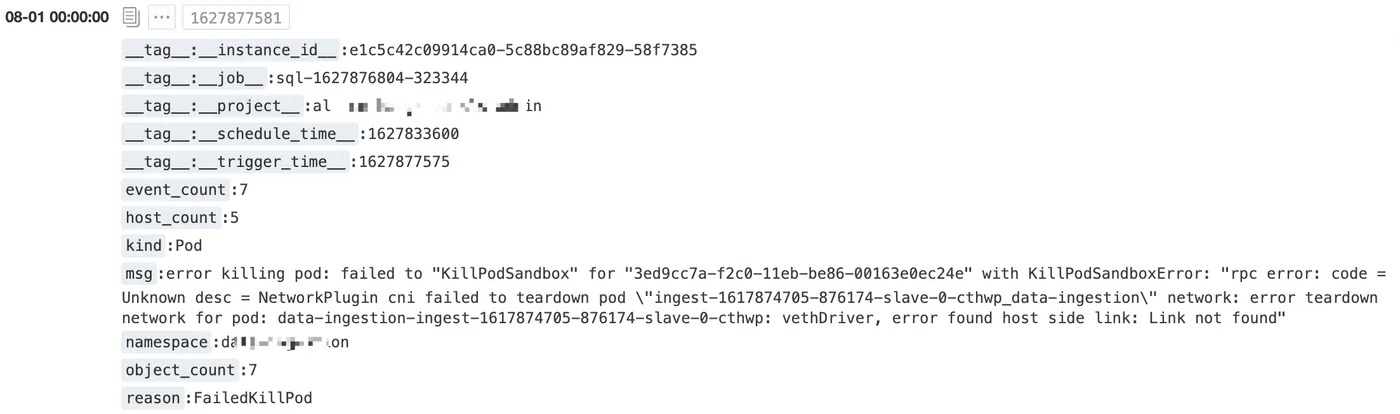
结果数据集的规模大大降低了,做一年时间范围的数据分析也没有压力,这里有两个例子。
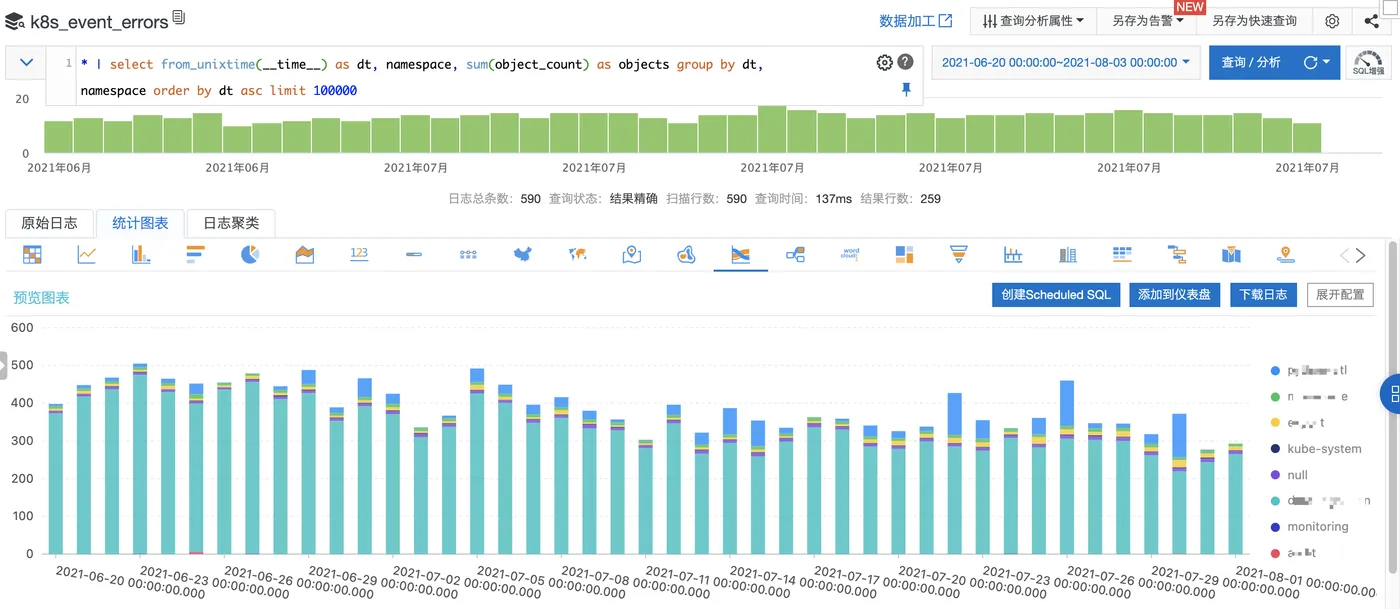
按 namespace 统计异常事件的时间趋势
SQL 代码:
* | select from_unixtime(__time__) as dt, namespace, sum(object_count) as objects group by dt, namespace order by dt asc limit 100000可视化图表:
按 object 类型统计异常事件的时间趋势
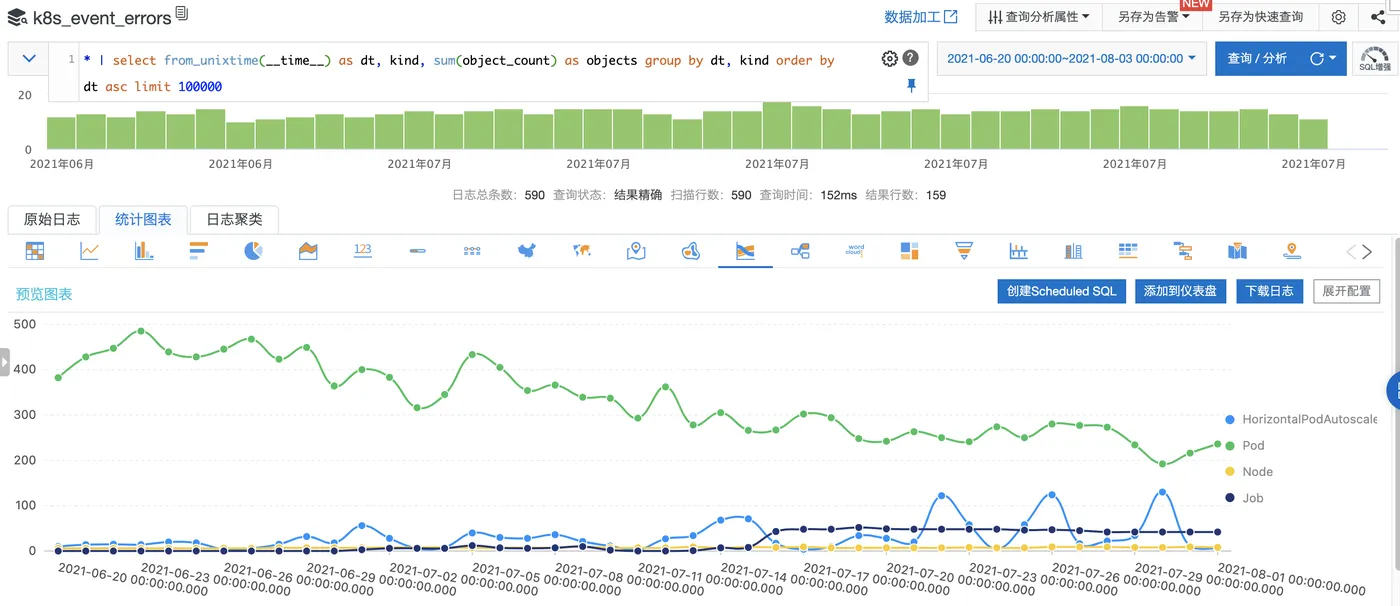
SQL 代码:
* | select from_unixtime(__time__) as dt, kind, sum(object_count) as objects group by dt, kind order by dt asc limit 100000可视化图表: