
说明
搭建集群首先要进行集群的规划【哪台做主节点,哪些做从节点】,这里简单搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 ResourceManager 服务。集群搭建跟单机版本的差别只体现在配置文件上,然后就是将文件同步给其他集群服务器。
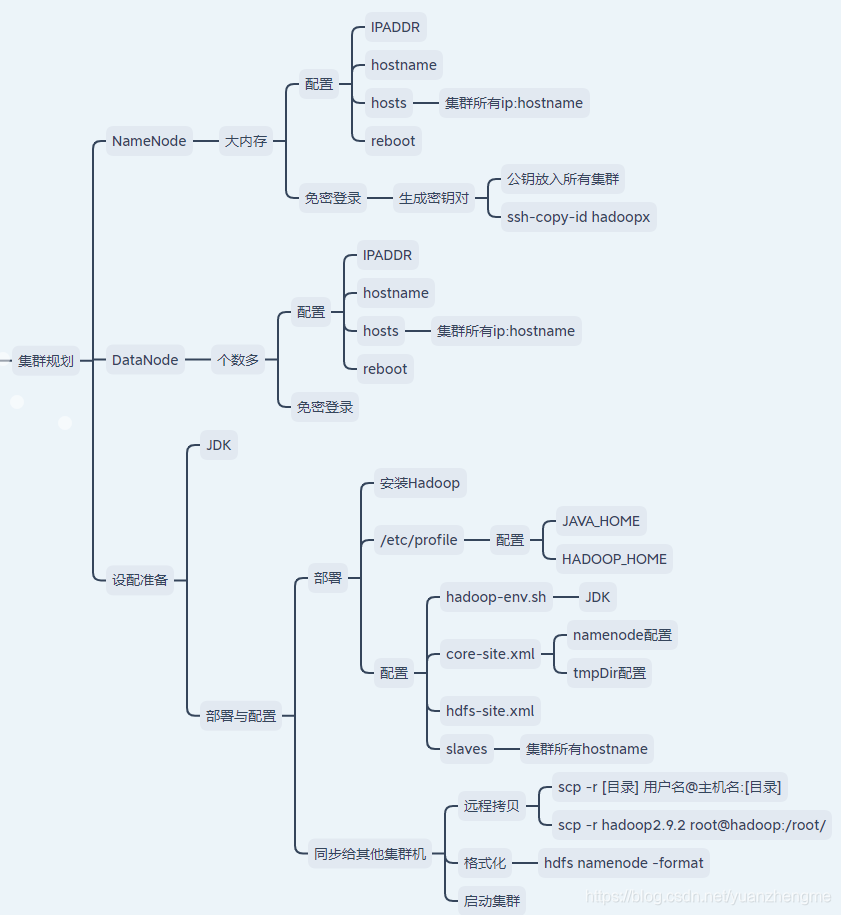
1.前置条件【每台服务器】
Hadoop 的运行依赖 jdk 我原本安装的是 openjdk11【由于yarn报错,换回了jdk8】。
[root@hadoop001 logs]# java -version
java version "1.8.0_251"
Java(TM) SE Runtime Environment (build 1.8.0_251-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode)
2.配置免密登录【每台服务器】
Hadoop 组件之间需要基于 SSH 进行通讯。
2.1 配置映射
配置 ip 地址和主机名映射:==很关键==通过ifconfig查询本机的ip地址,这个地方没有配置正确的话节点会有问题。
vim /etc/hosts
xxx.xx.x.x hadoop001 hadoop001
xxx.xx.x.x hadoop002 hadoop002
xxx.xx.x.x hadoop003 hadoop003
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
[root@hadoop001 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:BtWqdvRxf90QPhg5p2OOIBwgEGTu4lxAd92icFc5cwE root@tcloud
The key's randomart image is:
+---[RSA 2048]----+
|+*...o. +Eo... |
|+ .o...= =..+ o |
| o o.+...+ B . |
|. . .o.+ . * + |
|.. . +So * o oo|
|+ . o.. o . . +|
| o . . . |
| |
| |
+----[SHA256]-----+
2.3 授权
进入 /root/.ssh/ 目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@hadoop001 .ssh]# ll
total 16
-rw------- 1 root root 786 Jul 6 11:57 authorized_keys
-rw-r--r-- 1 root root 0 Jul 5 11:06 config
-rw-r--r-- 1 root root 0 Jul 5 11:06 iddummy.pub
-rw------- 1 root root 1679 Jul 27 17:42 id_rsa
-rw-r--r-- 1 root root 393 Jul 27 17:42 id_rsa.pub
-rw-r--r-- 1 root root 1131 Jul 6 13:31 known_hosts
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
2.4 集群间免密登录
# 1.生成密钥对
# 在每台主机上使用 ssh-keygen 命令生成公钥私钥对【上边已介绍】
[root@tcloud ~]# ssh-keygen -t rsa
# 2.免密登录
# 将hadoop001 的公钥写到本机和远程机器的 ~/ .ssh/authorized_key 文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
# 3.验证免密登录
ssh hadoop002
ssh hadoop003
3.HDFS环境搭建
3.1 解压
# 解压安装包并移动到/usr/local/下
tar -zxvf hadoop-3.1.3.tar.gz
mv ./hadoop-3.1.3 /usr/local/
3.2 配置环境变量【每台服务器】
配置环境变量的方法比较多,这里统一将环境变量放在 /tec/profile.d/my_env.sh 内。
# 配置环境变量:
vim /etc/profile.d/my_env.sh
# 添加 Hadoop的PATH要配置上bin和sbin
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 使得配置的环境变量立即生效:
# 首先是要赋权限【只操作一次就行】
chmod +x /etc/profile.d/my_env.sh
source /etc/profile.d/my_env.sh
3.3 修改配置
进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改配置文件。各个配置文件内容如下:
- hadoop-env.sh
# 指定JDK的安装位置 export JAVA_HOME=/usr/java/jdk1.8.0_201/ - core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp/data</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration> - hdfs-site.xml
<property> <name>dfs.namenode.http-address</name> <value>hadoop001:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop003:9868</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> - yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop002</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 以下参数要根据服务器情况进行配置--> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop001:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> - mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop001:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node245:19888</value> </property> </configuration> - slaves 特别注意:hadoop3.0 以后 slaves 变为 workers。
配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和NodeManager 服务都会被启动。hadoop001 hadoop002 hadoop003 - 修改启动和停止shell脚本
start-dfs.sh,stop-dfs.sh 这两个文件顶部添加以下参数:[root@hadoop001 hadoop]# vim /usr/local/hadoop-3.1.3/sbin/start-dfs.sh [root@hadoop001 hadoop]# vim /usr/local/hadoop-3.1.3/sbin/stop-dfs.shHDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh 这两个文件顶部添加以下参数:[root@hadoop001 hadoop]# vim /usr/local/hadoop-3.1.3/sbin/start-yarn.sh [root@hadoop001 hadoop]# vim /usr/local/hadoop-3.1.3/sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=yarn YARN_NODEMANAGER_USER=root3.4 关闭防火墙【每台服务器】
不关闭防火墙可能导致无法访问 Hadoop 的 Web UI 界面【使用云服务器还需要在安全组内开启端口】也会影响集群间的通讯:# 查看防火墙状态 [root@hadoop001 hadoop]# firewall-cmd --state not running # 如果是开启状态,关闭防火墙: [root@hadoop001 hadoop]# systemctl stop firewalld.service3.5 分发程序
将 Hadoop 安装包分发到其他两台服务器,分发后要在hadoop002、hadoop003服务器上也配置一下 Hadoop 的环境变量、映射、组件间的免密登录。# 将安装包分发到hadoop002 scp -r /usr/local/hadoop-3.1.3/ hadoop002:/usr/local/ # 将安装包分发到hadoop003 scp -r /usr/local/hadoop-3.1.3/ hadoop003:/usr/local/3.5 初始化【hadoop01】
在 Hadoop001 上执行 namenode 初始化命令:[root@hadoop001 bin]# ./hdfs namenode -format3.6 启动集群
进入到 Hadoop001 的 ${HADOOP_HOME}/sbin 目录下,启动 Hadoop。此时 hadoop002 和 hadoop003 上的相关服务也会被启动:
以下是启动和停止shell脚本【启动脚本要赋予可执行权限】:# hadoop001启动dfs服务 [root@hadoop001 sbin]# ./start-dfs.sh # hadoop002启动yarn服务 [root@hadoop002 sbin]# ./start-yarn.sh
```bash!/bin/bash
if [ $# -ne 1 ]
then
echo "args number is error!!!"
exit
fi
case $1 in
"start")
echo "============启动hadoop集群================"
echo "---------------启动hdfs------------------"
ssh hadoop001 $HADOOP_HOME/sbin/start-dfs.sh
echo "---------------启动yarn------------------"
ssh hadoop002 $HADOOP_HOME/sbin/start-yarn.sh
echo "---------------启动historyserver-------------"
ssh hadoop001 $HADOOP_HOME/bin/mapred --daemon start historyserver
;;
"stop")
echo "============关闭hadoop集群================"
echo "--------------关闭historyserver-----------"
ssh hadoop001 $HADOOP_HOME/bin/mapred --daemon stop historyserver
echo "-------------关闭yarn--------------------"
ssh hadoop002 $HADOOP_HOME/sbin/stop-yarn.sh
echo "-------------关闭hdfs--------------------"
ssh hadoop001 $HADOOP_HOME/sbin/stop-dfs.sh
;;
*)
echo "args info is error!!!"
;;
esac
### 3.7 查看集群
在每台服务器上使用 jps 命令查看服务进程【以下只是说明,并非在每台服务器上使用jps查询】:
```bash
# 【hdfs主节点】拥有 NameNode SecondaryNameNode
[root@hadoop001 sbin]# jps
1701 NameNode
1848 DataNode
7198 NodeManager
2095 SecondaryNameNode
# 【yarn主节点】拥有 ResourceManager
[root@hadoop002 sbin]# jps
1848 DataNode
7198 NodeManager
7055 ResourceManager
[root@hadoop003 sbin]# jps
1848 DataNode
7198 NodeManager
或直接进入 Web-UI 界面进行查看 ,根据配置的地址进行访问:
<property>
<name>dfs.namenode.http-address</name>
<value>tcloud:9870</value>
</property>
可以看到此时有三个可用的 Datanode 点击 Live Nodes 进入,可以看到每个 DataNode 的详细情况。也可以查看 Yarn 的情况,端口号为 8088。
3.8 提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交 Hadoop 内置的计算 Pi 的示例程序为例,在任何一个节点上执行都可以,命令如下:
[root@hadoop001 sbin]# hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 3 3
总结
集群搭建跟单机版不同的是要进行多台服务器的环境配置、hdfs配置、免密登录等。
