**作者:王刚、刘首维**
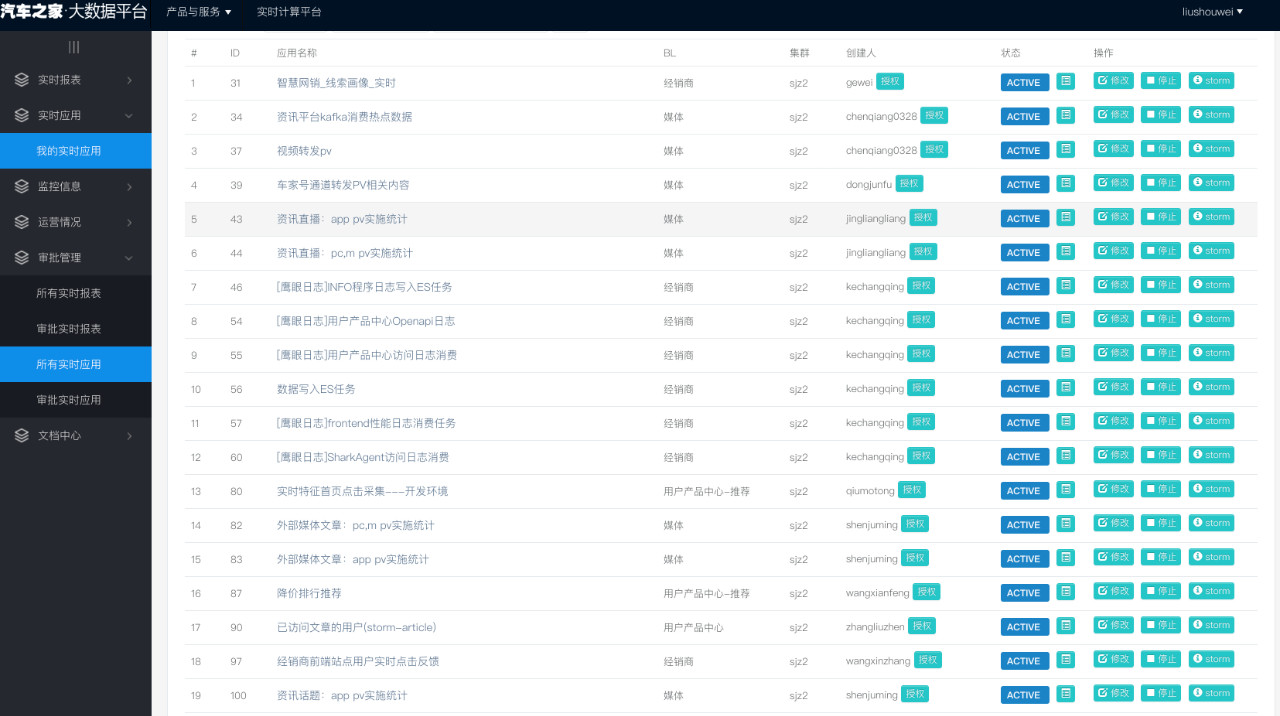
在 2019 年之前,之家的大部分实时业务都是运行在 Storm 之上的。Storm 作为早期主流的实时计算引擎,凭借简单的 Spout 和 Bolt 编程模型以及集群本身的稳定性,俘获了大批用户。下图是实时计算团队 Storm 平台页面:
自 2015 年至今 Storm 在之家已经运行 4 年之久,但随着实时计算的需求日渐增多,数据规模逐步增大,Storm 在开发及维护成本上都凸显了不足,这里列举两个痛点:
**1.翻译 SQL**
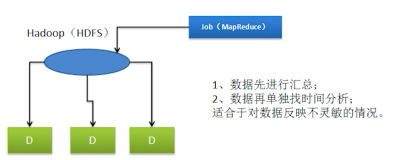
我们一直是 Lambda 架构,会用 T+1 的离线数据修正实时数据,即最终以离线数据为准,所以计算口径实时要和离线完全保持一致,实时数据开发的需求文档就是离线的 SQL,实时开发人员的核心工作就是把离线的 SQL 翻译成 Storm 代码,期间虽然封装了一些通用的 bolt 来简化开发,但把离线动辄几百行的 SQL 精准的翻译成代码还是很有挑战的,并且每次运行都要经过打包,上传, 重启的一系列的繁琐操作,调试成本很高。
**2.过于依赖外部存储**
Storm 对状态支持的不好,通常需要借助 Redis,HBase 这类 kv 存储维护中间状态,我们之前是强依赖 Redis。比如常见的计算 UV 的场景, 最简单的办法是使用 Redis 的 sadd 命令判断 uid 是否为已经存在,但这种方法会占用大量内存,如果没有提前报备的大促或搞活动导致流量翻倍的情况,很容易把 Redis 内存搞满,运维同学也会被杀个措手不及,同时 Redis 的吞吐能力也限制了整个作业的吞吐量。
在此背景下我们封装了基于 BloomFilter 的 bolt,BloomFilter 本身也会作为状态定期持久化到 reids 中,但是在多维度高基数的场景下,很难精确控制每个 BloomFilter 的大小,同样会占用很大内存。同时,过于依赖 Redis,在 Redis 集群 rtt 过长或部分节点负载高时会导致 Storm 作业 failed。
我们从 2018 年开始调研 Flink 引擎,其相对完备的 SQL 支持,天生对状态的支持吸引了我们,在经过学习调研后,2019 年初开始设计开发 Flink SQL 平台,目前平台已经服务于数仓、监控、日志、运维、测试等团队,2019 年 10 月已经有 160+ 线上作业,每日计算量 5000 亿条 支持实时数仓,实时推荐,UAS 系统,日志看板,性能测试等多种场景。单任务目前最高为 200 万 QPS。平台能够得到快速广泛的应用,主要得益以下几点:
- **开发成本低**:之家大部分的实时任务可以用 Flink SQL + UDF 实现。平台提供常用的 Source 和 Sink,以及业务开发常用的 UDF,同时用户可以自己编写 UDF。基于“ SQL + 配置”的方式完成开发,可以满足大部分需求。对于自定义任务,我们提供方便开发使用的 SDK,助力用户快速开发自定义 Flink 任务。平台面向的用户已经不只是专业的数据开发人员了,普通开发、 测试、运维人员经过简单培训都可以在平台上完成日常的实时数据开发工作,实现平台赋能化。
- **高性能**:Flink 可以完全基于状态(内存,磁盘)做计算,对比之前依赖外部存储做计算的场景,性能提升巨。在 818 活动压测期间,改造后的程序可以轻松支持原来几十倍流量实时计算流量,且横向扩展性能十分良好。
- **维护成本低**:用户将任务托管在平台上,任务的存续由平台负责,用户专注于任务本身的逻辑开发本身即可。对于 SQL 任务,SQL 的可读性极高,便于维护;对于自定义任务,基于我们 SDK 开发,用户可以更专注于梳理业务逻辑上。不论是 SQL 任务还是 SDK,我们都内嵌了大量监控,并与报警平台关联,方便用户快速发现分析定位并修复任务,提高稳定性。
- **支持数仓分层模型**:平台提供了良好的 SQL 支持,数仓人员可以借助 SQL,将离线数仓的建设经验应用于实时数仓的建设上。
- **数据资产管理**:SQL 语句本身是结构化的,我们通过解析一个作业的 SQL,结合 source、 sink 的 DDL,可以很容易的知道这个作业的上下游,天然保留血缘关系。
下面将分三部分给大家分享:
- 架构及设计思路
- 基于 Flink SQL 平台的实时数仓的实践及使用案例
- 后续规划
## 一. 架构及设计思路

### 1.表管理
在平台上我们把 source,sink 都抽象成表:
表管理: 目前我们是基于 Flink 1.7.2 的,这个版本还不支持 DDL,所以我们通过扩展 Calcite 语法,自己实现了 DDL 解析,把 source 和 sink 阶段使用的外部存储 (Kafka、Mysql 、ES、Redis、Http 等)中的目标对象都映射成关系型表管理起来,方便复用。如下图:


对于动态配置,可以在每个任务界面的配置功能灵活地进行指定。

血缘关系:每次运行任务我们都会解析出这个任务需要的源表(流表,维表)和结果表 ,可以很自然的保存各种表的血缘关系。
### 2.任务配置管理
#### 2.1 SQL
我们 SQL 任务支持两种模式:一种是直接 SELECT 查询,一种是 INSERT INTO 将数据写入外部存储的目标表 。
- 用户执行 SELECT 的时候,我们会在页面上滚动展示计算结果,以供查看结果及调试。
- SELECT 实现思路是 Flink 的计算结果会发送缓存服务器,并存储在 Ringbuffer 中。
- 同时,在同一个作业中可以编写多个 SQL,我们还提供了创建视图的 DDL,简化对复杂 SQL 的多次引用。
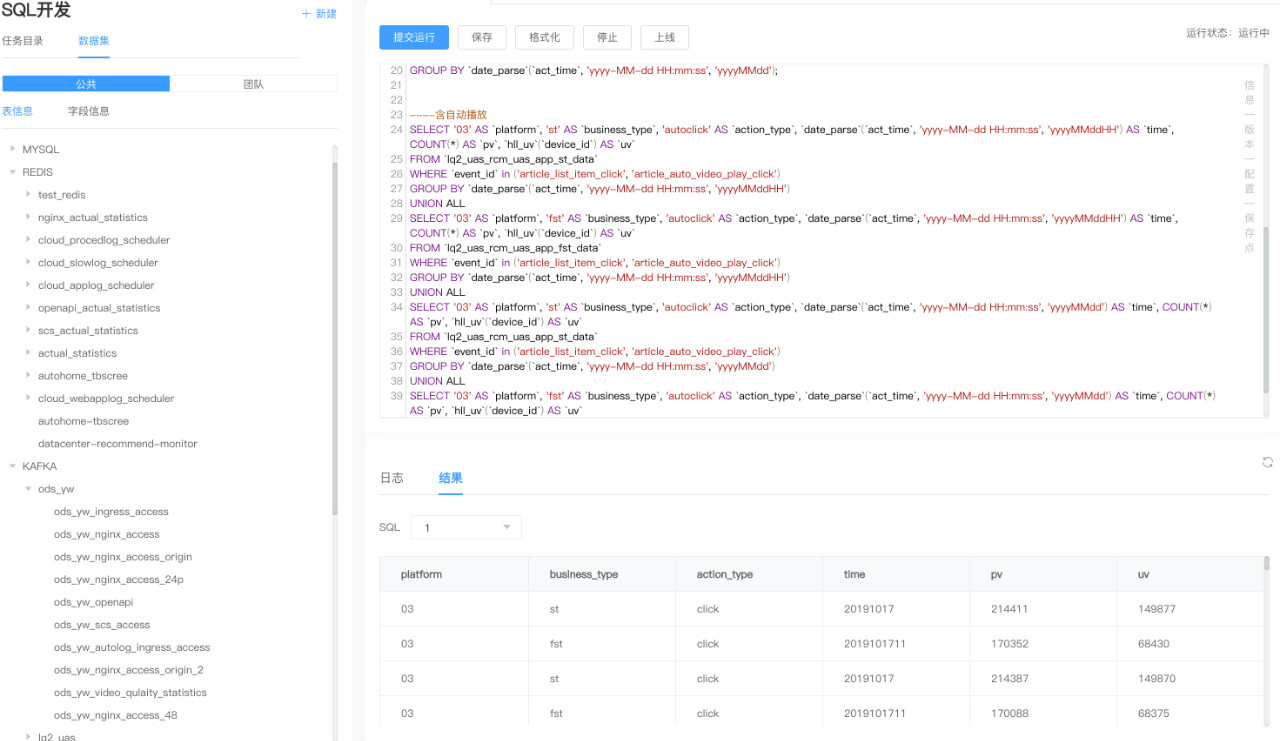
#### 2.2 任务配置
任务配置有三种 :
- **作业配置(jobConf)** : 如 checkpoint 时间间隔,状态过期时间,重启策略等等。
- **启动配置 (launchConf)** : 如 jobmanager 内存,taskmanger 个数,slot 数 ,使用的队列等资源相关的配置及执行代码的版本。
- **集群配置(clusterConf)** : 因为我们的任务模式是 perjob 的,即每个 Flink 作业都运行在一个独立的 Flink 集群中,我们可以很轻松的给每个作业配置个性化的集群参数。
### 3.权限管理
我们的平台是支持多租户的,目前在以下两方面做了权限控制:
- 作业级别:每个团队只能去管理自己团队内的作业。
- 表级别:平台上的表分两类,一类是团队内部的表,仅限于团队内部可见;另一类是公共表,对所有的用户可见,公共表中的流表(Kafka topic) 目前需要去消息平台去申请读/写权限才能使用。
### 4.UDF 管理
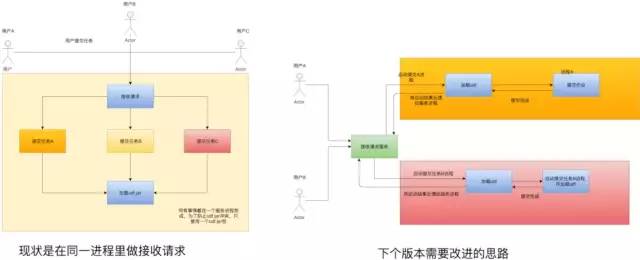
目前所有启动 Flink 作业的请求都是通过一个 client 进程去提交的,因为是同一个进程,所以不能做到频繁的加载 jar 包,导致目前还不能自助上传 UDF 。 我们接下来准备参考 athenax 的做法,在每次去运行任务的时候单独起个进程去编译 Jobgraph 对象再转发给提交进程,这样可以做到团队间的 UDF 不冲突。
### 5.资源调度框架
资源调度框架我们使用的是 YARN 和 k8s 状态存储在 hdfs 上。之家 Hadoop 服务器集群数量在几千台左右,并且在之家的业务场景下实时和离线计算是天生错峰的,白天流量高,离线的作业量少,YARN 计算资源充足,完全可以满足实时计算的需求。
而 k8s 对我们来说是未来发展的方向,有更高的稳定性和更方便的使用体验。 目前我们有少量作业运行在 k8s 上,接下来我们在考虑在 YARN 集群和 k8s 或者备用 YARN 集群之间做热备,比如 YARN 集群 down 掉重要的作业会从 hdfs 读取状态切到 k8s 上。
### 6.日志收集
我们首先定制了自己的 Log4j Layout 增加了辅助的日志信息。对于运行在 YARN 上的任务, 我们基于 Flume 的 Log4j Appender 定制了自己的日志收集器,从服务器异步发送日志到 Kafka 中,尽可能地降低对运行作业的影响;对于运行在 k8s 的任务,我们通过容器组同事提供的 API 直接采集即可。
日志会上报到公司统一的采集系统,途经 Kafka 最终写入 Elasticsearch 集群,通过 Kibana 可以方便的查看 Flink 日志 。
### 7.监控报警
监控报警这块主要依赖公司的统一监控平台。
- 统一监控平台提供了专用的 Promethues 服务,我们通过 Flink 的 promethues push gateway 上报 metric ,Flink 本身的 metric 比较完善,其监控的粒度精确到每个 subtask 的 operator。
- 我们自行开发的组件都定义了常用的 metric,用户可以通过查看监控图表定位组件的健康状态。
- 我们配置了一些默认的模版,包括 Flink Cluster, IO(task/operator 级别), JVM 、Kafka source、Elasticsearch sink、Redis sink 等,方便用户查看图表,在统一监控平台上,用户可以针对任意 metric 设置自定义报警。
- 同时对延迟,任务重启,等重要指标提供了默认的报警机制。
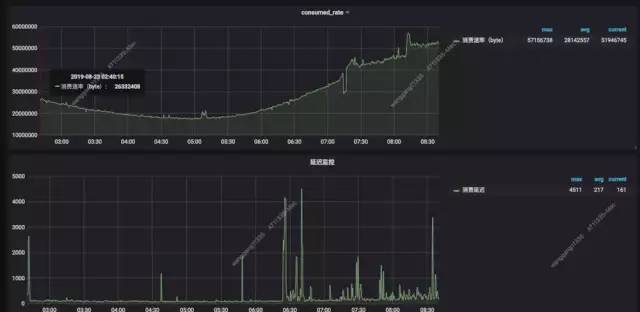
Kafka-connector监控
Redis-connector监控
## 二.基于 Flink 平台的实时数仓的实践

如上文提到,我们把 Kafka 的 topic 当做 table 并结合消息平台做权限控制。这样做的目的就是方便给做实时数仓做准备。数据源来自 mysql 的 binlog 日志、埋点的流量日志、及服务器系统日志。
其中在数据表打宽的过程我们借鉴了袋鼠云的维表 join 办法,用 calcite 再解析成 SqlNode 之后就把表合并成一张宽表,再修改原始的 SQL 语句。目前被用在表的清洗打宽还是没有问题的,但是这种方式在很复杂的 SQL 语句里就没那么好用了,只能借助 udtf。
我们把数据清洗成宽表,再基于宽表清洗成每个主题的汇总表,最终将汇总表和宽表开放给业务方使用,业务方可以直接在平台通过编写 SQL 完成实时计算的开发工作。
目前已经支持了推送,推荐,数仓,UAS,监控,日志,压测,罗盘大屏等多种业务场景。
### 1.使用案例:推荐系统实时指标计算
内容和资讯一直是之家的核心和根本。内容推荐系统更是支撑整个内容咨询体系的一个重要组成部分。基于实时计算平台的 SQL 模块计算了大量维度的实时指标,写入多种存储,帮助推荐系统快速而准确地反馈推荐物料的推荐效果,形成有效的闭环。
之家对于每个投放的物料/资源,都有唯一的业务类型(biztype)和物料 Id (objectid),通过这两个属性可以唯一表示一个资源。对于针对用户的不同的操 作和行为,我们定义了 eventid 这个概念,比如可见曝光,点击等。而从实验/ 策略的维度上,我们存在实验主题(topic)和分桶 id(bucketid)的概念。此外, 维度还包括但不限于地域,IP。另一方面,还以检测资源投放耗时和响应时间等指标。
众所周知,一个 Flink 的计算任务分为三个阶段 source -> transformation -> sink,那我们也结合 SQL 来看这三个阶段是如何完成的。
- **source**
用户行为日志(UAS)是写入 Kafka 的,格式是 JSON。我们首先做的事情是对原始日志进行清洗和整理抽象成关系型模型。利用平台的数据集解析创建功能搭配几 个 SQL 清洗数据任务还是比较容易的:
分析数据格式,利用平台建表功能创建对于产出的一系列关系型表的 Schema。
利用 SQL 模块编写清洗数据任务,对应步骤 1 的目标产出表。
- **kafkasource**

sink 和 source 的步骤差不多,平台目前支持多种 sink 的同时,还基于 javacc 提供灵活的自定义写入模板,用户可以自己决定数据是怎样组织写入 sink 的,可以覆盖绝大部分需求,如果遇到不能满足的情况,也可以通过继承我们对外发布的 SDK 的接口完成自定义逻辑的编写。

transformation 相对于另外两个阶段,复杂在业务逻辑上,下面举例说明利用 SQL 快速解决问题。
- **需求**:计算单一物料每天的可见曝光和点击的 pv 和 uv。
- **开发**:定义好 sink,直接编写 SQL 开发即可。

### 2.总结
利用实时平台,我们很好地将推荐的实时指标计算的系列任务,分层化、模块化、规范化,开发速度与准确性大幅提升,最快一个新的指标计算只需要小时级就可以搞定,同时学习成本大幅降低,用户只需要使用我们提供的页面+ SQL 就可以完成实时任务的开发,从而赋能业务方,使之可以独立开发实时计算任务。
同时也解决了我们之前提到过的两个痛点:
- 不需要把离线的 SQL 翻译成代码,基于清洗过的宽表,直接用 SQL 就可以实现实时指标的开发。
- 不再重度依赖第三方存储存放状态,Flink 自身维护了状态,Redis 只是单纯的存储最终结果。
## 三.后续规划
1.与仓库,业务方合作生产更多的业务宽表,汇总表,将数据资产化。
2.不断丰富平台功能,支持更多 Sink 与 Source,提供更多的工具供业务方使用,进一步降低开发运维成本。
3.将平台任务部署继续向 K8s 模式倾斜。
4.持续不断提升 Flink 在公司的影响,吸纳更多人使用 Flink 解决生产问题,丰富使用场景。
5.调研 Flink 1.9 以后的版本,并逐渐引入到公司生产中。
**▼ Apache Flink 社区推荐 ▼
**
Apache Flink 及大数据领域盛会 Flink Forward Asia 2019 将于 11月28-30日在北京举办,阿里、腾讯、美团、字节跳动、百度、英特尔、DellEMC、Lyft、Netflix 及 Flink 创始团队等近 30 家知名企业资深技术专家齐聚国际会议中心,与全球开发者共同探讨大数据时代核心技术与开源生态。了解更多精彩议程请点击:
https://developer.aliyun.com/special/ffa2019-conference?spm=a2c6h.13239638.0.0.21f27955RBnbkV