1. 友盟+ 简介
友盟+ 以“数据智能,驱动业务增长”为使命,为移动应用开发者和企业提供包括统计分析、性能监测、消息推送、智能认证等一站式解决方案。截止2023年6月,已累计为270万移动应用和980万家网站,提供十余年的专业数据服务。
作为国内最大的移动应用统计服务商,其统计分析产品 U-App & U-Mini & U-Web 为开发者提供基础报表及自定义用户行为分析服务,能够帮助开发者更好地理解用户需求,优化产品功能,提升用户体验,助力业务增长。

为了满足产品、运营等多业务角色对数据不同视角的分析需求,统计分析 U-App 提供了包括用户分析、页面路径、卸载分析在内的多种「开箱即用」的预置报表,集成 SDK 上报数据后即可查看这些指标。除此以外,为了满足个性化的分析诉求,业务也可以自定义报表的计算规则,提供了事件细分、漏斗分析、留存分析等用户行为分析模型,用户可以根据自己的分析需求灵活地选择时间范围、设置事件名称、where筛选和Groupby分组等。

如上所述,U-App 服务了众多应用场景,每天处理接近千亿条日志,需要考虑平衡好数据新鲜度、查询延迟和成本的关系,同时保障系统的稳定性,这对数据架构和技术选型提出了极高的要求。
针对报表类型不同的看数场景和业务需求,我们底层技术架构通过多种产品来支撑。在数据新鲜度方面,分别使用 Flink 和 MaxCompute 提供了T+0 的实时计算 和 T+1的离线批量计算,主要支持预置报表的计算场景,并将计算好的结果导出到类HBase 存储,能够支持高并发的报表查询。在分析时效性方面,使用阿里云的Hologres 实现自定义报表支持秒级的 OLAP分析,当处理的数据周期跨度大时,可能会出超过内存算子处理范围,因此我们转化为离线计算引擎来执行,同时也让交互体验从同步降级为异步。
在本文中,我们会分享友盟U-App 背后的技术实现,以及友盟在行为分析和画像分析场景上的最佳实践。
2. 友盟+技术架构
如下图所示,在大数据领域这是一个比较通用的数据处理 pipeline,贯穿数据的加工&使用过程包括,数据采集&接入、数据清洗&传输、数据建模&存储、数据计算&分析 以及 查询&可视化,其中友盟U-App 数据处理的核心架构是红框部分。

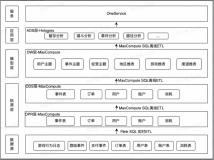
U-App 整体架构如下图所示,从上往下大体可以分为四层:数据服务、数据计算、数据存储以及核心组件:
- 数据服务:将查询DSL 解析为底层引擎执行的DAG,同时智能采样、查询排队等来尽可能减少系统过载情况,保证查询顺滑
- 数据计算:根据不同分析场景抽象沉淀了分析模型,包括行为分析和画像分析两大类
- 数据存储:使用了以 User-Event 为核心的数据模型,提供基于明细数据的行为分析
- 核心组件:离线批量计算使用MaxCompute,流式计算使用Flink,OLAP计算使用Hologres

在设计系统架构时,支持多引擎是优先要考虑的,主要有以下原因:
- 鉴于成本、稳定性、高可用以及容错性考虑,引擎需要根据查询场景分级路由,将查询性能好的OLAP计算与健壮可靠但延迟较大的离线计算相结合。用户可以使用 OLAP 分析进行灵活的数据探查,当数据量超过一定阈值时自动转为离线计算。另外,对于添加到看板需要例行查看的报表也会通过离线的方式批量计算。
- 鉴于存储成本考虑,将数据进行冷热分离,实时数仓只储最近1个月热数据,超过查询范围的Query会自动路由到离线计算。
- 从系统的可扩展性考虑,OLAP领域发展很快,众多引擎百花齐放,需要为之后对接其它引擎预留出灵活的升级空间。

同时,我们也设计了一套通用的计算规则来支持多引擎架构,屏蔽底层细节。借鉴了Presto系统设计,选择Antlr来定义通用的查询规则,查询DSL使用JSON来描述。Task Builder 在生成任务DAG时,遍历AST抽样语法树,并结合物理表存储等元数据信息,生成指定引擎可执行的语句。
通过自定义描述语言,上层业务只需要对接DSL不用关注底层细节,既降低了业务对接成本,也增强了平台扩展性。

基于这套技术架构,我们服务了友盟+U-App 产品中的众多应用场景。其中,基于明细数据的用户行为分析和基于全域标签的画像分析是非常重要的两个功能,其实现主要使用了阿里云Hologres,下面我们会详细介绍这两个场景上的最佳实践。
3. Hologres多维分析使用实践
在多维分析场景,尤其是用户行为分析和画像分析场景上,市面上可选择的OLAP产品还是较多的。我们对集团多个引擎进行深入调研和测试后,最终选择了阿里云计算平台的Hologres,主要基于以下考虑:
- 存算分离架构:计算资源弹性伸缩,满足灵活扩展性的同时又兼顾了成本。
- 生态丰富:语法与PostgreSQL函数兼容,我们使用起来的时候比较方便。同时我们也与Hologres团队共建,支持了一些UDF函数,方便我们业务深度开展。
- 与MaxCompute深度集成:可以和MC互相直读,加速查询,实现实时离线联邦查询。同时也支持冷热数据混合查询,有利于成本性能平衡。
- 性能强悍:引擎C/C++编写,支持量化全异步执行,PB级数据查询秒级响应且支持数据实时写入。
3.1 用户行为分析实践
U-App行为洞察提供了事件、漏斗、留存 、行为路径等模型,可以帮助业务从多视角洞察用户细粒度的使用行为,从而进一步辅助业务精细化运营。

U-App 行为洞察提供的是普惠的交互式分析服务,这对技术的挑战主要包括以下几个方面:
- 数据量大,每天新增日志条数接近千亿级别(注:为了保证查询灵活性,分析使用的是没有信息损失的事件原始数据,即没有使用中间聚合表)
- 应用众多,不同应用数据量差距较大
- 自定义埋点数据 schema-free ,不同应用埋点属性差异巨大
- 计算分析速度要快并发要高
为了应对以上诸多挑战,我们从存储层、引擎执行层以及查询层制定了系统性化的解决方案,下面依次进行介绍。
数据存储层设置合理的索引
根据业务查询特点,在Hologres中合理的建立索引,尽可能减少Scan的数据量:
- 根据查询特点(每个查询只涉及一个应用的有限几个事件),按照appkey,event_name建立聚簇索引(Clustering Key)
- 根据用户行为分析的特点,按设备id分片(Distribution Key),数据在woker节点正交分布,减少跨节点数据 shuffle
- 设置合理shard数量,平衡数据写入和查询性能
- 对常用筛选列建立Bitmap索引,提升数据过滤效率

在埋点场景上,开发者可设置自定义事件和属性,自定义属性使用 JSON 字符串表示。JSON 优点是天然支持 Schema Evoluation,开发者根据业务需求,灵活进行埋点。缺点是较列式存储,由于无法利用列存对数据进行压缩,占用存储空间大,而且查询 JSON 时要将整个字符串完整解析一遍,中间涉及大量IO和CPU操作,对性能影响极大。
为解决这个问题,业界较通用的方案是在预处理阶段,动态地将JSON展开成独立列,通过外部的元数据表来维护 schema。另外,为了减少 schema 变动,也可以提前创建预留列,然后将新抽取的列映射到预设列上。但友盟+服务了众多开发者 ,不可能将所有的属性都展开成独立列---即使可以做到,使用和维护成本也相当高。
借助 Hologres v1.3版本的JSONB列式存储特效,支持在导入JSON 数据时,引擎自动抽取JSON数据结构,包括字段个数,字段类型等,然后在存储层将JSON数据转化成强 Schema格式的列式存储格式的文件,以此来达到加速查询的效果。通过测试,使用 JSONB 后,数据存储会节省 25~50%,查询效率提升 5~10 倍。

引擎执行层使用行为分析函数
为了提升查询性能,我们与Hologres合作共建了自定义的分析函数函数,它主要解决两个问题:
- 漏斗、留存这类分析模型,使用普通JOIN计算性能较差,尤其是漏斗分析,随着计算事件数的增加,时间复杂度会指数级放大。
- 原生SQL表达能力差,无法描述计算逻辑复杂的模型。为了解决以上问题,需要开发自定义的分析函数 。
具体实现是基于Hologres的引擎,兼容PostgreSQL语法,使用C语言定制开发了漏斗和留存算子,集成在Hologres的版本中(最开始的发布的版本是0.8版本)。目前在Hologres高版本中默认已经集成了计算漏斗和留存的流量函数(windowFunnel,retention等),以及成为系统的标配,使用起来更加方便,性能也更好。
例如下面是一个漏斗分析的示例,计算在 20231220 这一天,在 1 小时内 依次发生从启动(session_start)-> 加购物车(add_cart)-> 支付订单(order_pay)3 个事件的转化漏斗,我们对比了传统JOIN方案和漏斗函数的方案的性能性能。
--不使用 windowFunnel WITH log(user_id, event_time, event_name) as ( SELECT user_id,event_time,event_name FROM event_log WHERE ds >= '20231220' and ds<='20231220' ) SELECT ARRAY[COUNT(DISTINCT step1.user_id) FILTER (WHERE step1.event_time is not null), COUNT(DISTINCT step2.user_id) FILTER (WHERE step2.event_time is not null), COUNT(DISTINCT step3.user_id) FILTER (WHERE step3.event_time is not null)] FROM (SELECT user_id,event_time FROM log WHERE event_name = 'session_start') step1 LEFT JOIN (SELECT user_id,event_time FROM log WHERE event_name = 'add_cart') step2 ON (step1.user_id = step2.user_id AND step1.event_time < step2.event_time AND step2.event_time-step1.event_time <= 3600) LEFT JOIN (SELECT user_id,event_time FROM log WHERE event_name = 'order_pay') step3 ON (step1.user_id = step3.user_id AND step2.event_time < step3.event_time AND step3.event_time-step1.event_time <= 3600); --使用 windowFunnel WITH step_detail AS ( SELECT step, COUNT(1) AS count_user FROM( SELECT user_id, windowFunnel (3600, 'default', event_time, event_name = 'session_start', event_name = 'add_cart', event_name = 'order_pay') AS step FROM event_log WHERE ds >= '20231220' AND ds <= '20231220' GROUP BY user_id ) AS inner GROUP BY step ORDER BY step ASC ) SELECT CASE step WHEN 0 THEN 'total' WHEN 1 THEN 'session_start' WHEN 2 THEN 'add_cart' WHEN 3 THEN 'order_pay' END, SUM(count_user) OVER (ORDER BY step DESC) FROM step_detail GROUP BY step,count_user ORDER BY step ASC;
第一个是纯SQL的方式,第二个是用 Hologres windowFunne 聚合函数。使用第一个JOIN SQL会有性能问题,因为存在多步JOIN操作,随着计算事件量的增加,时间复杂度会指数级放大。而第二个使用漏斗函数的SQL则变得简单许多。
下面是使用普通JOIN与漏斗函数的性能测试对比情况:在事件量较小的情况下,二者性能差距不大,但随着事件量的增加,普通JOIN查询性能迅速衰减,而使用漏斗函数的耗时较平缓。与普通的JOIN 查询相比,使用漏斗函数的查询速度提升了 5~10 倍,内存使用量下降 10%~25%。

数据查询层使用智能采样、查询排队
智能采样:由于OLAP是完全基于内存的计算,为了避免较大查询引发系统OOM,保障查询吞吐和系统稳定性,对于数据量较大的 Query 会主动采样。通过分析查询条件,结合预先统计的信息可以预估出Scan的数据量,然后再结合提前设置好的阈值确定采样率。平台上线初期,智能采样发挥了很大的作用。
查询排队:为了解决瞬时高并发查询引发的系统过载的问题,基于Redis实现了查询排队功能。如下图所示,它包含Waiting Queue和Active Queue两部分,所有请求先进入等待队列排队,并控制进入执行队列的数量,从而避免系统过载,大幅提升了查询的顺滑性。

3.2 标签人群计算实践
友盟+基于采集的设备信息产出了丰富维度的标签数据。依托这些数据,U-App提供的全景画像功能可以对数据进行详细刻画。
为了实现画像的高性能多维分析,我们使用了Hologres的Roaring Bitmap功能。在具体数据存储上,为了充分发挥 Hologres 多 shard 的并发优势,数据的分布键(Distribution Key)按桶号和 bitmap 高16位打散到Hologres各个计算节点。在进行交并差集计算过程中,由于各个节点之间数据完全独立,每个节点可以单独计算,然后在Master节点进行汇总。
计算过程如下图所示,整个过程可以分为两个阶段:在Worker节点会进行第一次聚合,由于Worker间数据完全正交,数据没有shuffle过程,不需要跨几点转移数据,效率会非常高;在Master节点进行最终聚合通过简单汇总得到最终结果。

基于以上 Hologres 的Roaring Bitmap设计,一个完整的标签场景从数据导入和查询示例如下:
--Hologres 标签表 begin; CREATE TABLE IF NOT EXISTS rb_tag_table ( name text NOT NULL, value text NOT NULL DEFAULT '', bucket bigint NOT NULL, bitmap roaringbitmap ); call set_table_property('rb_tag_table', 'orientation', 'column'); call set_table_property('rb_tag_table', 'distribution_key', 'bucket'); call set_table_property('rb_tag_table', 'clustering_key', 'name,value'); commit; --Hologres 人群表 begin; CREATE TABLE IF NOT EXISTS rb_crowd_table ( crowd_id text NOT NULL, bucket bigint NOT NULL, bitmap roaringbitmap ); call set_table_property('rb_crowd_table', 'orientation', 'column'); call set_table_property('rb_crowd_table', 'distribution_key', 'bucket'); call set_table_property('rb_crowd_table', 'clustering_key', 'crowd_id'); commit; --标签表:从Maxcompute外表读取数据构建 bitmap INSERT INTO rb_tag_table SELECT 'age' AS name,age_v1 AS value,bucket,rb_build_agg(oneid) AS bitmap FROM ( SELECT age_v1, id % 64 AS bucket, cast((id / 64) AS int) as oneid FROM tag_foreign_table WHERE age_v1 != '' )t1 GROUP BY age_v1, bucket; --使用RB标签圈人 SELECT sum(rb_cardinality(bitmap)) AS total From rb_tag_table WHERE name = 'city' AND value='0'; --使用RB人圈洞察 SELECT t1.value AS value,SUM(t1.size) AS total FROM ( SELECT tag.bucket,tag.value AS value,rb_cardinality(rb_and(tag.bitmap,crowd.bitmap)) AS size FROM( select bucket,value,bitmap from rb_tag_table where name='brand' and value in ('xiaomi','oppo') ) tag JOIN ( select bucket,bitmap from rb_crowd_table where crowd_id='crowd_01' ) crowd ON tag.bucket = crowd.bucket )t1 GROUP BY t1.value;
通过使用 Hologres 提供的 Roaring Bitmap 功能,使用的存储大大减少,相较之前大概有 5~10 倍的节省。查询性能方面,与普通的 JOIN 相比,两个亿级别ID的标签复合运算的可以有数量级的性能提升,90%的 Query 能够在1秒内稳定完成,满足了业务上对高吞吐和即时分析的需求。
4. 总结与展望
目前,Hologres 在友盟+统计分析、营销等多个产品线使用,很好地满足了用户行为分析、人群圈选与洞察场景的多维度分析、灵活下钻、快速人群预估和圈选等分析需求,提供客户更流畅的数据查询和分析体验。
未来,随着互联网流量红利消失,拉新和留存成本升高,精细化数据运营越来越被重视,对于数据分析的时效性和灵活性的要求变得越来越高,实时OLAP数据分析会成为一种基本需求,这对技术的挑战也越来越大。技术上,后续会结合Hologres物化视图、冷热数据分离等新特性,同时探索基于Apache Paimon 的 Streaming LakeHouse 存储技术,不断优化精简架构,在平衡好性能、成本和稳定性基础上,提升计算平台实时计算能力,为开发者提供更好用的普惠的数据分析服务。
作者:张哲(花名 渝知) 友盟+高级技术专家