1.7 正态分布

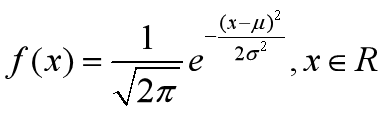
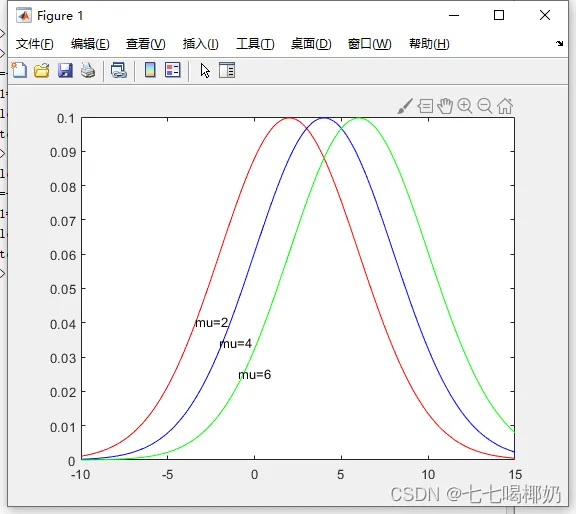
1. clear 2. x=-10:0.1:15; 3. p1=normpdf(x,2,4);p2=normpdf(x,4,4);p3=normpdf(x,6,4); 4. plot(x,p1,'r-',x,p2,'b-',x,p3,'g-'), 5. gtext('mu=2'),gtext('mu=4'),gtext('mu=6')
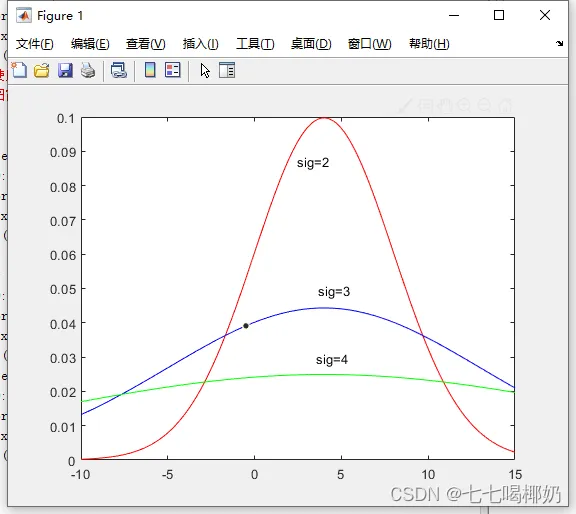
1. clear 2. x=-10:0.1:15; 3. p1=normpdf(x,4,4);p2=normpdf(x,4,9);p3=normpdf(x,4,16); 4. plot(x,p1,'r-',x,p2,'b-',x,p3,'g-'), 5. gtext('sig=2'),gtext('sig=3'),gtext('sig=4')
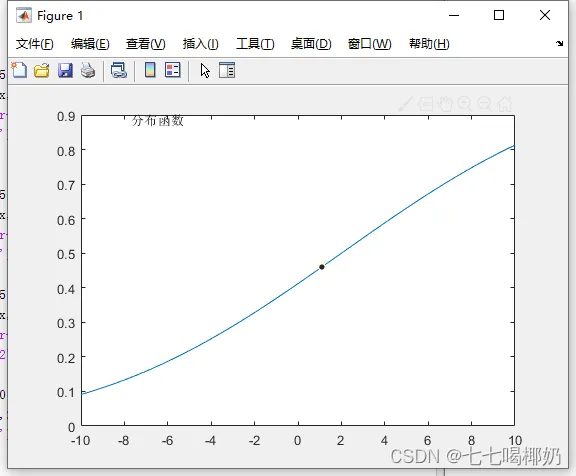
1. >> clear 2. >> x=-10:0.1:10; 3. >> p=normcdf(x,2,9); 4. >> plot(x,p,'-'),gtext('分布函数')
1. >> p=[0.01,0.05,0.1,0.9,0.05,0.975,0.9972]; 2. >> x=icdf('norm',p,0,1) 3. x = 4. -2.3263 -1.6449 -1.2816 5. 1.2816 -1.6449 1.96 2.7703
x=icdf('norm',p,0,1)
计算标准正态分布的分布函数的反函数值,即知道概率情况下,返回相应的分位数。
产生正态分布的随机数
1. >> R=normrnd(0,1,3,4) 2. R = 3. 1.5877 0.8351 -1.1658 0.7223 4. -0.8045 -0.2437 -1.1480 2.5855 5. 0.6966 0.2157 0.1049 -0.6669 6. >> R1=normrnd(0,1,3) 7. R1 = 8. 0.1873 -0.4390 -0.8880 9. -0.0825 -1.7947 0.1001 10. -1.9330 0.8404 -0.5445
1.8 三大抽样分布
卡方分布、t 分布和 F 分布也是统计学中常用的重要概率分布,它们分别用于解决以下问题:
- 卡方分布在统计推断中经常用于分析类别型数据的关联性和拟合度。它可以帮助我们比较观察到的频数与期望频数之间的差异,并进行卡方检验来判断观察到的数据是否符合某种理论分布或假设。
- t 分布在小样本情况下用于估计总体均值或进行假设检验。它通常用于推断均值、对比两个样本均值是否显著不同,或者构建置信区间等。t 分布具有允许样本量较小的特点,适用于样本标准差未知或总体不服从正态分布的情况。
- F 分布常用于比较两个或多个总体方差的差异。它常用于方差分析(ANOVA)中,用于检验不同组或处理之间的方差是否显著不同。F 分布还被广泛应用于回归分析中的模型比较和变量选择。
1.8.1 χ2分布
X1,X2,…,Xn是一个来自服从标准正态分布总体的样本,则统计量(Helmert(1875),KarlPeason(1900))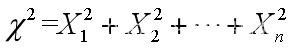
服从自由度为n的卡方分布,记作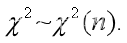
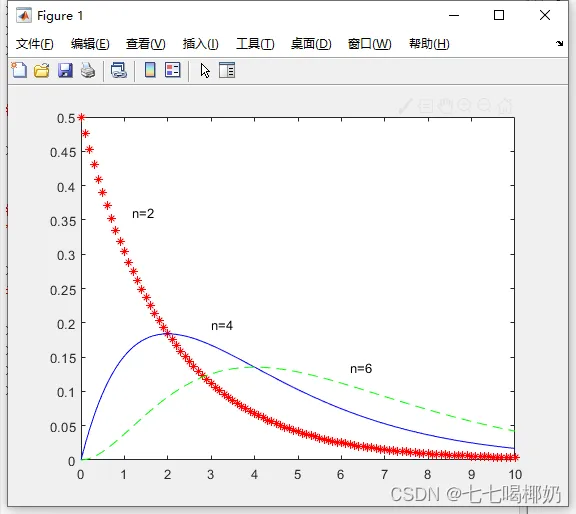
1. >> clear 2. >> x=0:0.1:10; 3. p1=chi2pdf(x,2);p2=chi2pdf(x,4);p3=chi2pdf(x,6); 4. >>plot(x,p1,'r*',x,p2,'b-',x,p3,'g--'),gtext('n=2'),gtext('n=4'),gtext('n=6')
1.8.2 t分布(Gosset 1908)
 X,Y相互独立,则
X,Y相互独立,则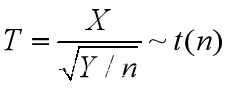
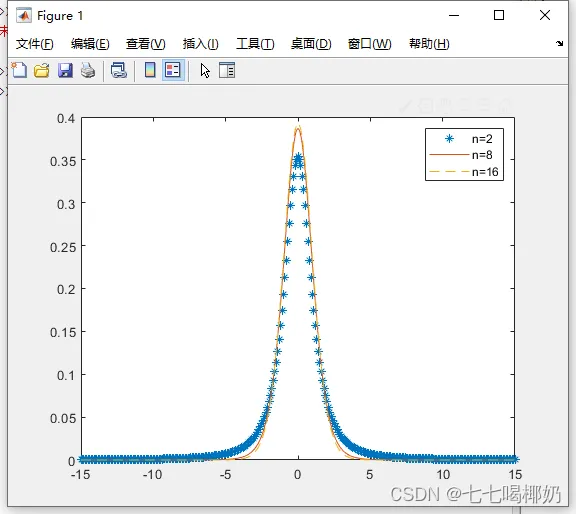
1. >> x=-15:0.1:15; 2. p1=tpdf(x,2);p2=tpdf(x,8);p3=tpdf(x,16); 3. plot(x,p1,'*',x,p2,'-',x,p3,'--'),legend('n=2','n=8','n=16')
1.8.3 F 分布(Fisher,1924)
 X,Y相互独立,则统计量
X,Y相互独立,则统计量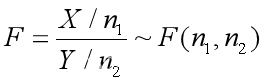
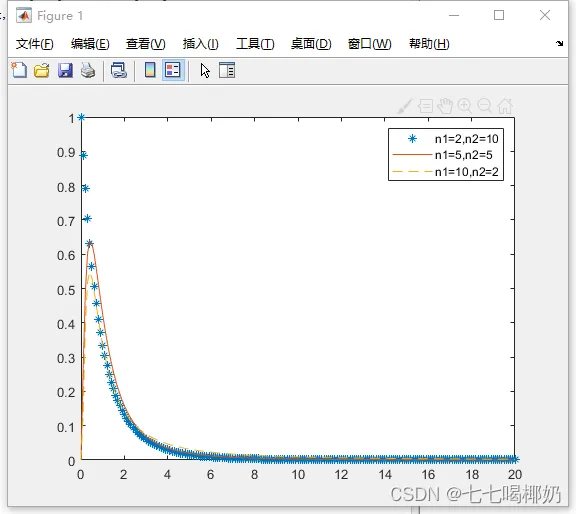
1. >> clear 2. >> x=0:0.1:20; 3. >> p1=fpdf(x,2,10);p2=fpdf(x,5,5);p3=fpdf(x,10,2); 4. >> plot(x,p1,'*',x,p2,'-',x,p3,'--'),legend('n1=2,n2=10','n1=5,n2=5','n1=10,n2=2')