

如今,计算机视觉社区已经广泛展开了对物体姿态的 6D 追踪和 3D 重建。本文中英伟达提出了同时对未知物体进行 6D 追踪和 3D 重建的方法。该方法假设物体是刚体,并且需要视频的第一帧中的 2D 物体掩码。
除了这两个要求之外,物体可以在整个视频中自由移动,甚至经历严重的遮挡。英伟达的方法在目标上与物体级 SLAM 的先前工作类似,但放松了许多常见的假设,从而能够处理遮挡、反射、缺乏视觉纹理和几何线索以及突然的物体运动。
英伟达方法的关键在于在线姿态图优化过程,同时进行神经重建过程和一个内存池以促进两个过程之间的通信。相关论文已被 CVPR 2023 会议接收。

- 论文地址:https://arxiv.org/abs/2303.14158
- 项目主页:https://bundlesdf.github.io/
- 项目代码:https://github.com/NVlabs/BundleSDF
本文的贡献可以总结如下:
- 一种用于新颖未知动态物体的因果 6 自由度姿态跟踪和 3D 重建的新方法。该方法利用了并发跟踪和神经重建过程的新颖共同设计,能够在几乎实时的在线环境中运行,同时大大减少了跟踪漂移。
- 引入了混合 SDF 表示来处理动态物体为中心的环境中由于噪声分割和交互引起的不确定自由空间的挑战。
- 在三个公共基准测试中进行的实验显示了本文方法与主流方法的最先进性能。
英伟达方法的鲁棒性在下图 1 中得到了突出显示。
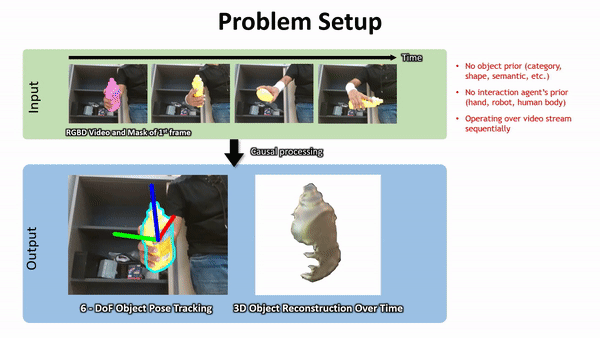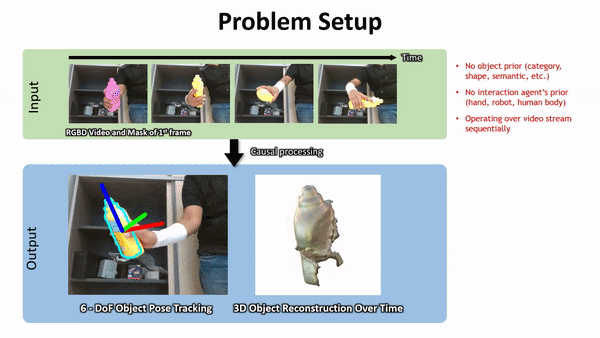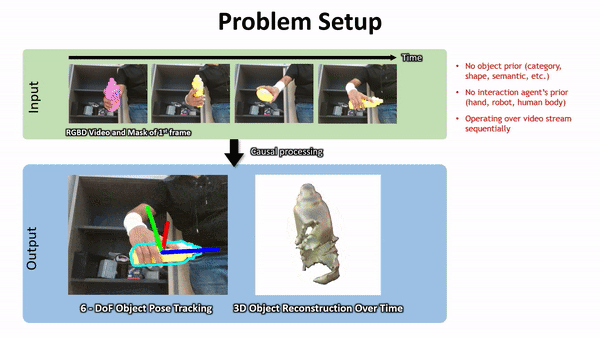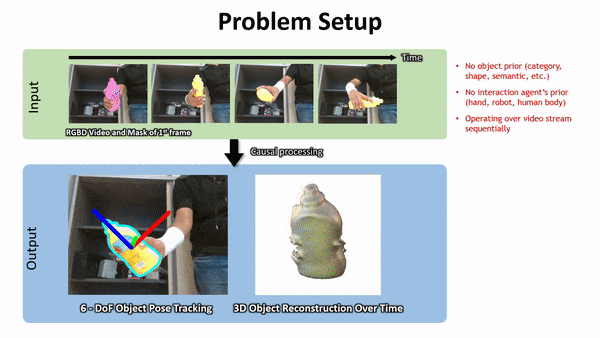
下面是一些 Demo 展示:


与相关工作的对比
此前的 6D 物体姿态估计旨在推断出目标物体在相机帧中的三维平移和三维旋转。最先进的方法通常需要实例或类别级别的物体 CAD 模型进行离线训练或在线模板匹配,这限制了它们在新颖未知物体上的应用。尽管最近有几项研究工作放宽了假设并旨在快速推广到新颖未见的物体,但它们仍然需要预先捕获测试物体的姿态参考视图,而英伟达的设定中并不假设这一点。
除了单帧姿态估计之外,6D 物体姿态跟踪利用时间信息在整个视频中估计每帧物体姿态。与单帧姿态估计方法类似,这些方法在不同的假设条件上进行,例如训练和测试使用相同的物体,或者在相同类别的物体上进行预训练。
然而,与所有以往工作不同的是,英伟达的追踪和重建协同设计采用了一种新颖的神经表示,不仅在实验证实中实现了更强大的跟踪能力,还能够输出额外的形状信息。
此外,虽然 SLAM(同时定位与地图构建)方法解决的是与本研究类似的问题,但其专注于跟踪相机相对于大型静态环境的姿态。动态 SLAM 方法通常通过帧 - 模型迭代最近点(ICP)与颜色相结合、概率数据关联或三维水平集似然最大化来跟踪动态物体。模型通过将观察到的 RGBD 数据与新跟踪的姿态聚合实时重建。
相比之下,英伟达的方法利用一种新颖的神经对象场表示,允许自动融合,同时动态矫正历史跟踪的姿态以保持多视角一致性。英伟达专注于物体为中心的场景,包括动态情景,其中常常缺乏纹理或几何线索,并且交互主体经常引入严重遮挡,这些是在传统 SLAM 中很少发生的困难。与物体级 SLAM 研究中研究的静态场景相比,动态交互还允许观察物体的不同面以进行更完整的三维重建。
方法概览
英伟达方法的概述如下图所示。给定单目 RGBD 输入视频以及仅在第一帧中感兴趣物体的分割掩码,该方法通过后续帧跟踪物体的 6D 姿态并重建物体的纹理 3D 模型。所有处理都是因果的(无法访问未来帧的信息)。英伟达假设物体是刚体,但适用于无纹理的物体。
此外不需要物体的实例级 CAD 模型,也不需要物体的类别级先验知识(例如事先在相同的物体类别上训练)。

整个框架的流程可以概括为:首先在连续的分割图像之间匹配特征,以获得粗略的姿态估计(第 3.1 节)。其中一些具有姿态的帧被存储在内存池中,以便稍后使用和优化(第 3.2 节)。从内存池的子集动态创建姿态图(第 3.3 节);在线优化与当前姿态一起优化图中的所有姿态。
然后,这些更新的姿态被存储回内存池中。最后,内存池中的所有具有姿态的帧用于学习基于 SDF 表示的神经物体场(在单独并行的线程中),该对象场建模物体的几何和视觉纹理(第 3.4 节),同时调整它们先前估计的姿态,以鲁棒化 6D 物体姿态跟踪。
在这项工作中,一个独特的挑战在于交互者引入的严重遮挡,导致了多视几何不再一致。并且完美的物体分割掩码通常无法得到。为此,英伟达进行了独特的建模以增加鲁棒性。
下面左图:使用视频分割网络(第 3.1 节)预测的二值掩码进行高效的射线追踪的 Octree 体素表示,该物体分割掩码由于来自神经网络的预测难免存在错误。射线可以落在掩码内部(显示为红色)或外部(黄色)。右图:神经体积的 2D 俯视示意图,以及沿着射线进行的混合 SDF 建模的点采样。蓝色样本接近表面。

实验和结果
数据集:英伟达考虑了三个具有截然不同的交互形式和动态场景的真实世界数据集。有关野外应用和静态场景的结果,请参阅项目页面。
- HO3D:该数据集包含了人手与 YCB 物体交互的 RGBD 视频,由近距离捕捉的 Intel RealSense 相机进行拍摄。
- YCBInEOAT:该数据集包含了双臂机器人操作 YCB 物体的第一视角的 RGBD 视频,由中距离捕捉的 Azure Kinect 相机进行拍摄。操作类型包括:(1)单臂拾取和放置,(2)手内操作,以及(3)双臂之间的拾取和交接。
- BEHAVE:该数据集包含人体与物体交互的 RGBD 视频,由 Azure Kinect 相机的预校准多视图系统远距离捕捉。然而,我们将评估限制在单视图设置下,该设置经常发生严重遮挡。
评估指标:英伟达分别评估姿态估计和形状重建。对于 6D 物体姿态,他们使用物体几何来计算 ADD 和 ADD-S 指标的曲线下面积(AUC)百分比。对于 3D 形状重建,英伟达计算最终重建网格与地面真实网格之间在每个视频的第一帧定义的规范坐标系中的 Chamfer 距离。
对比方法:英伟达使用官方的开源实现和最佳调整参数与 DROID-SLAM (RGBD) [61]、NICE-SLAM [85]、KinectFusion [43]、BundleTrack [69] 和 SDF-2-SDF [53] 进行比较。此外还包括它们在排行榜上的基准结果。





团队介绍
该论文来自于英伟达研究院。其中论文一作是华人温伯文,博士毕业于罗格斯大学计算机系。曾在谷歌 X,Facebook Reality Labs, 亚马逊和商汤实习。研究方向为机器人感知和 3D 视觉。





