
请列举常见的机器学习模型正则化的方式,简述自己对不同方法的理解。
答:
第一类:引入参数范数惩罚项
通过在损失函数中添加一个参数范数惩罚,限制模型的学习能力。其中,常见的有:L1正则化与L2正则化。
这种正则化方式可以从解空间形状、函数叠加和引入贝叶斯先验(L1正则化引入拉普拉斯先验、L2正则化引入高斯先验)等多个角度来解读。其中,我认为最直观的是花书中从解空间形状角度的分析:
如图3-1所示(图源《深度学习》花书),为在二维时的体现。其中,黄色的部分是L2 和L1正则顶约束后的解空间,绿色的等高线是凸优化问题中目标函数的等高线。
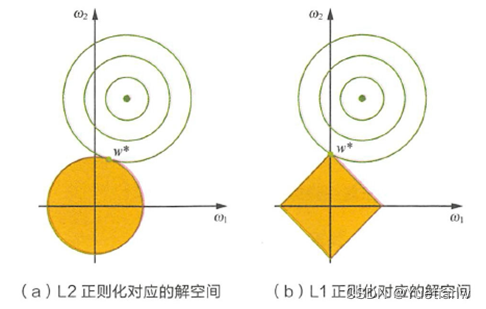
图3-1 二维情况下的解空间与L1、L2正则化
由图可见,LI 正则项约束的解空间是多边形,更容易在尖角处与等高线碰撞出稀疏解;而L2 正则项约束后的解空间是圆形,更容易在权值小的地方产生解。
第二类:数据增强
让机器学习模型泛化效果更好的最简单粗暴的方法是使用更多的数据集训练,但是我们往往无法获得更多的真实数据,这就需要我们“生成”更多的数据。在视觉任务中,常见操作有:对图片进行小幅旋转,平移,放大,缩小和给图片噪声等变换,甚至可以利用GAN来生成更多图像。
第三类:模型集成
通过训练多个不同的模型,并让所有模型一起表决测试集的输出,比如Bagging等方法。
同时,尽管人们对Dropout的作用有多种角度的解释,但我个人倾向于将Dropout也理解为一种模型集成的方法,我认为它提供了一种低端的Bagging方法的近似,尽管训练中各模型(即每次Dropout后留下的网络)间并不独立,而是共享参数的。
第四类:其它方法
一些其它方法或者trick还有很多,比如:
Earlystopping:当验证集上的误差在事先指定的循环次数内没有进一步改善时就停止算法。
标签平滑:通过在均匀分布和hard标签之间应用加权平均值来生成soft标签。
对抗训练(Adversarial Training):过程中,样本会被混合一些微小的扰动(改变很小,但是很可能造成误分类),然后使神经网络适应这种改变,从而增加模型的鲁棒性。


