一、Apriori算法简介
“Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域。 算法简介 Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。算法思想 ”。
二、因为WEKA能识别的文件类型是.arff文件,所以我们需要将已有数据转为.arff文件格式的数据(见下图紫色框中的内容)。
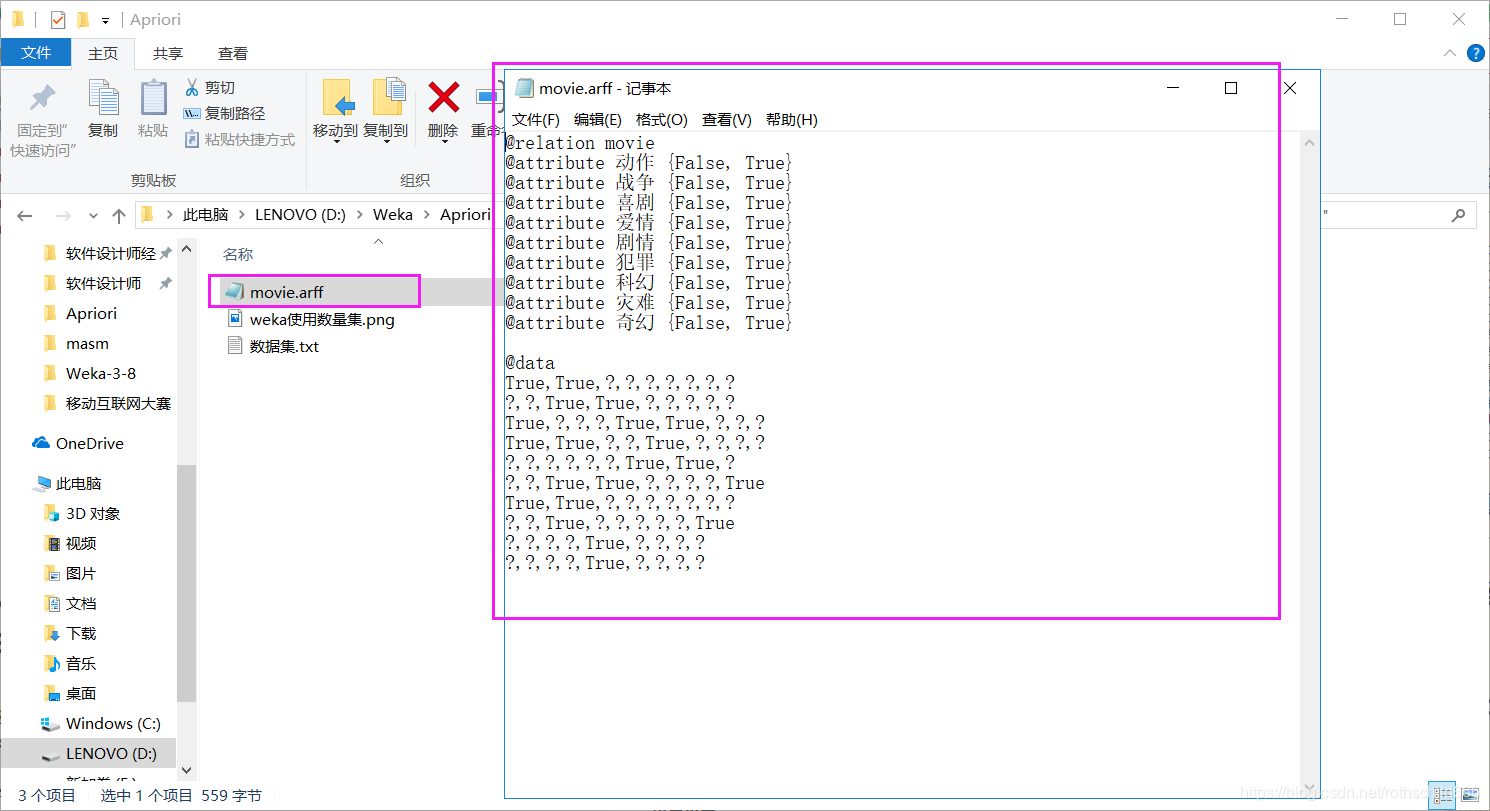
1、@relation:关系名(无硬性要求,但建议取和数据相关的名如下面的movie);
2、@attribute:属性名 ;
3、 { }:属性可取值的范围,可自定义;
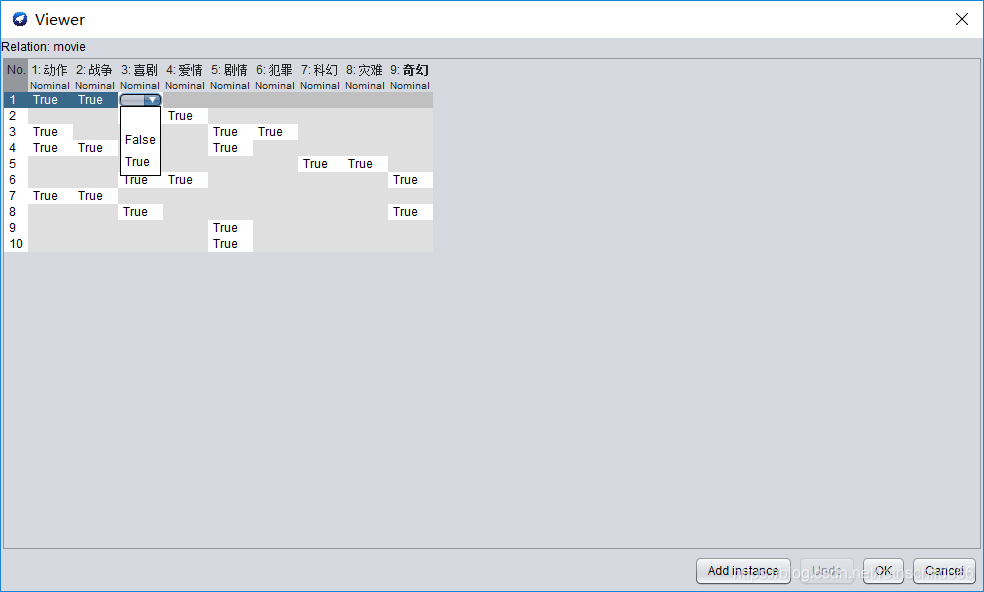
4、@data:之后每一行均为一个事务,未知属性值使用 “ ?”,也可以填写属性值范围{}的内容(下面的就是可以填“True”或者“False”),解释一下第一行:动作、战争,第二行:喜剧、爱情,第三行:剧情、动作、犯罪。规律就是“True”对应的属性值就是该行事务的取值内容,而“ ?”则不用显示。
5、.arff文件可以用.txt文本文件修改后缀名生成。
@relation movie @attribute 动作 {False, True} @attribute 战争 {False, True} @attribute 喜剧 {False, True} @attribute 爱情 {False, True} @attribute 剧情 {False, True} @attribute 犯罪 {False, True} @attribute 科幻 {False, True} @attribute 灾难 {False, True} @attribute 奇幻 {False, True} @data True,True,?,?,?,?,?,?,? ?,?,True,True,?,?,?,?,? True,?,?,?,True,True,?,?,? True,True,?,?,True,?,?,?,? ?,?,?,?,?,?,True,True,? ?,?,True,True,?,?,?,?,True True,True,?,?,?,?,?,?,? ?,?,True,?,?,?,?,?,True ?,?,?,?,True,?,?,?,? ?,?,?,?,True,?,?,?,?
三、用WEKA进行数据预处理(点击紫色箭头指向的紫色框中的内容“Explorer”)。
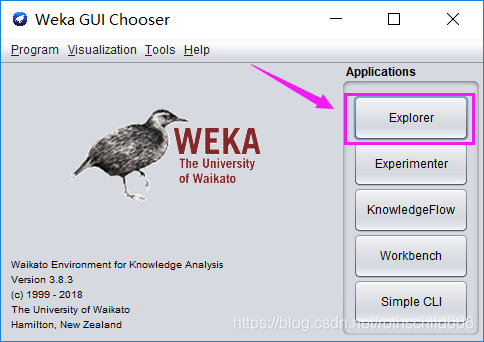
1、Explorer
用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。(An environment for exploring data with WEKA)
2、Experimentor
用来进行实验,对不同学习方案进行数据测试的环境。(An environment for performing experiments and conducting statistical tests between learning schemes.)
3、KnowledgeFlow
功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)
4、SimpleCLI
简单的命令行界面。(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)
四、进入新页面后,点击紫色箭头指向的紫色框中的内容“Open file”。
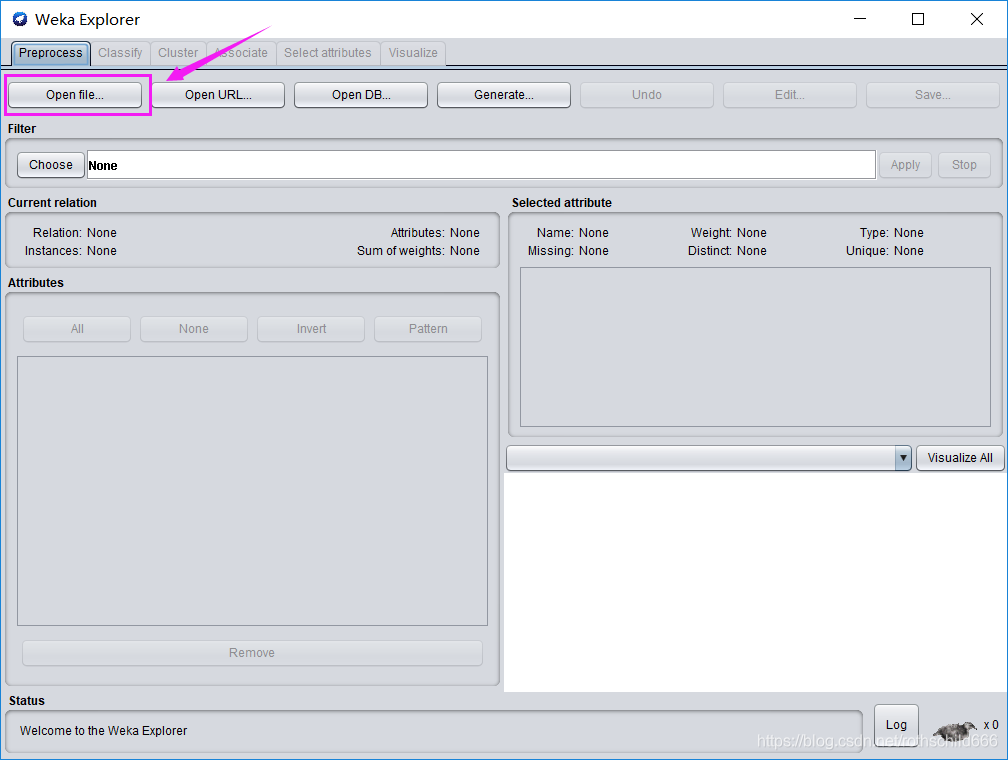
五、找到自己之前要进行数据预处理的.arff文件(博主进行示范的是movie.arff,见第二步红色箭头指向的红色框指向的内容)。
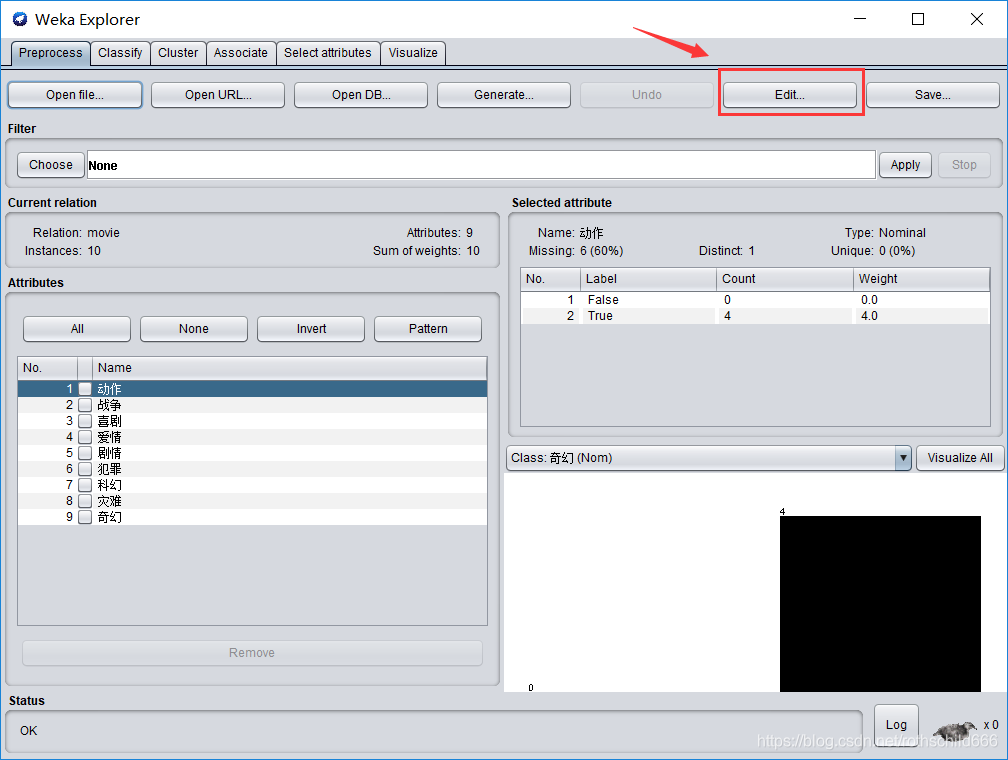
六、可点击红色箭头指向的红色框中的内容“Edit”对.arff数据内容进行重新编辑,也可以不编辑(博主就没有重新编辑了,同时请注意:编辑不会改变原.arff文件内容也就是例子中的movie.arff文件)。
七、点击红色箭头指向的红色框中的内容“Associate”(关联规则分析)。
温馨提示:Preprocess(预处理)、Classify(分类)、Cluster(聚类)、Associate(关联规则)、Select attribute(特征选择)和Visualize(可视化)。
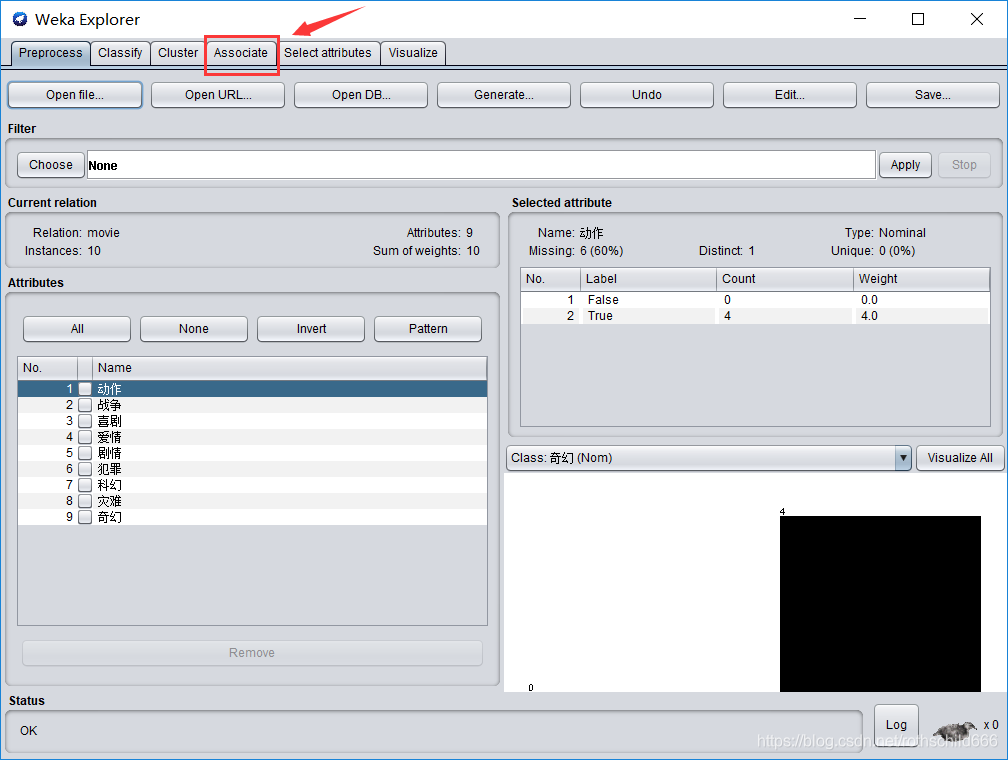
八、第一步点击红色箭头指向的红色框中的“choose”。
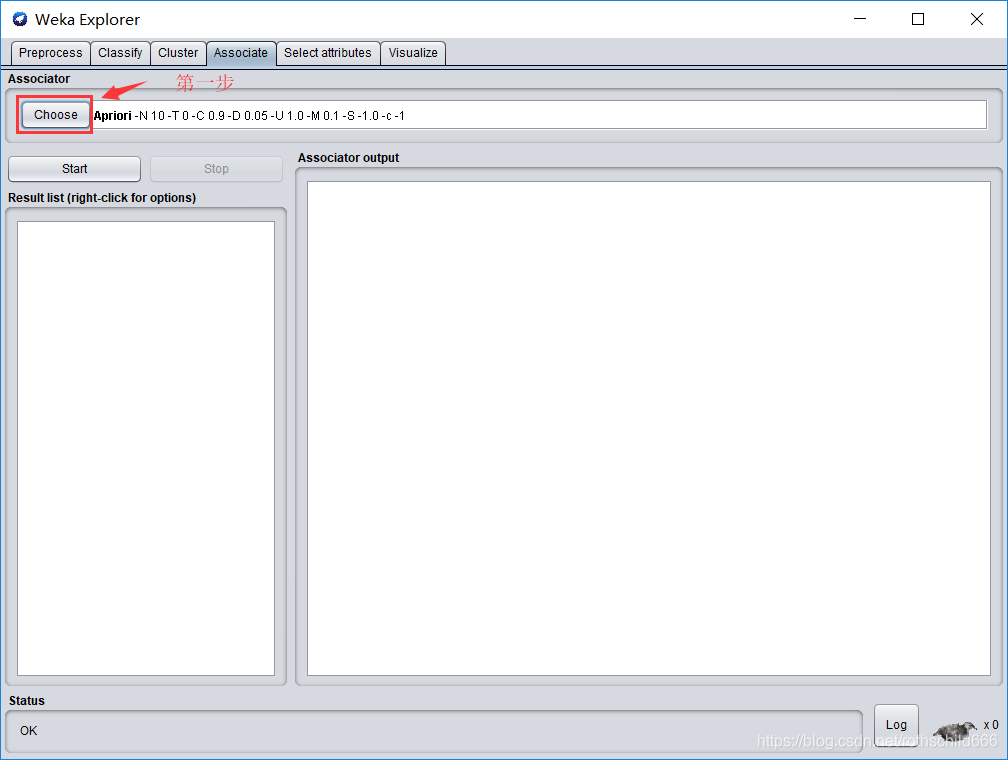
九、第二步选择红色箭头指向的红色框中的“Apriori”。进行算法选择为Apriori算法,为关联规则分析做准备。
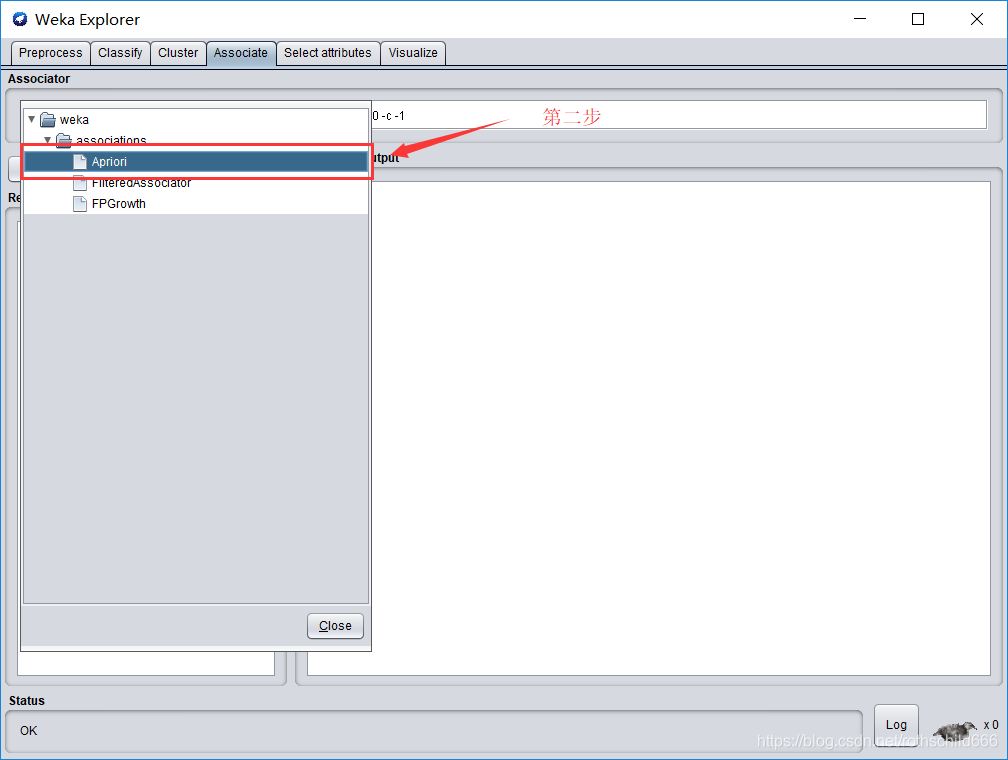
十、点击红色箭头指向的红色框中的内容。
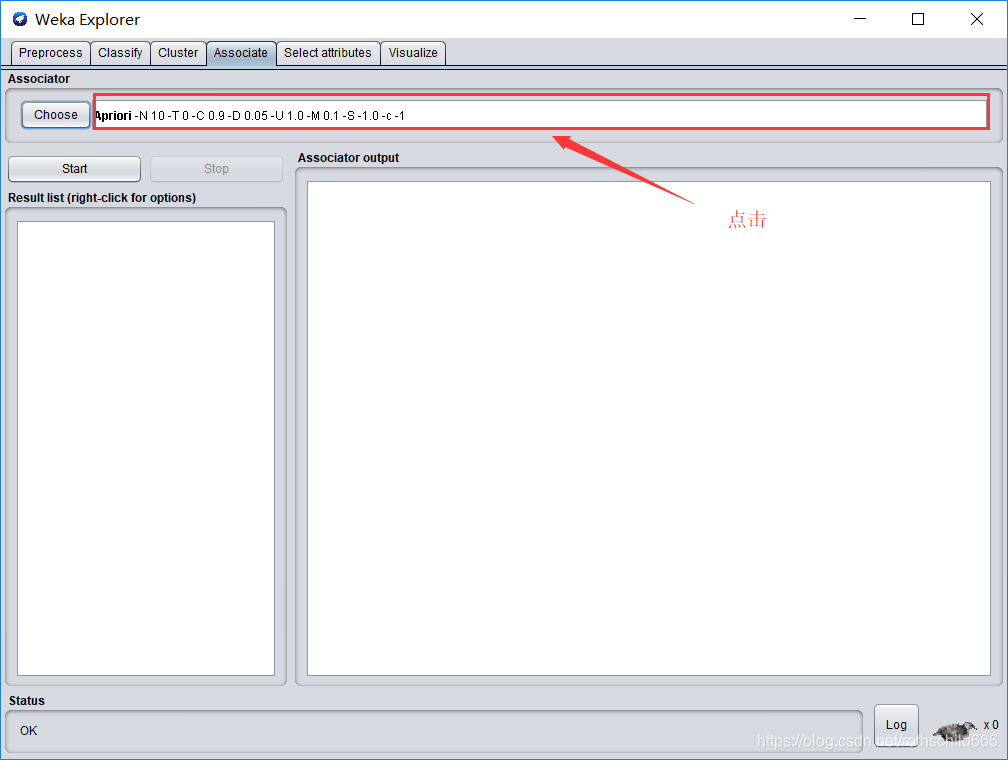
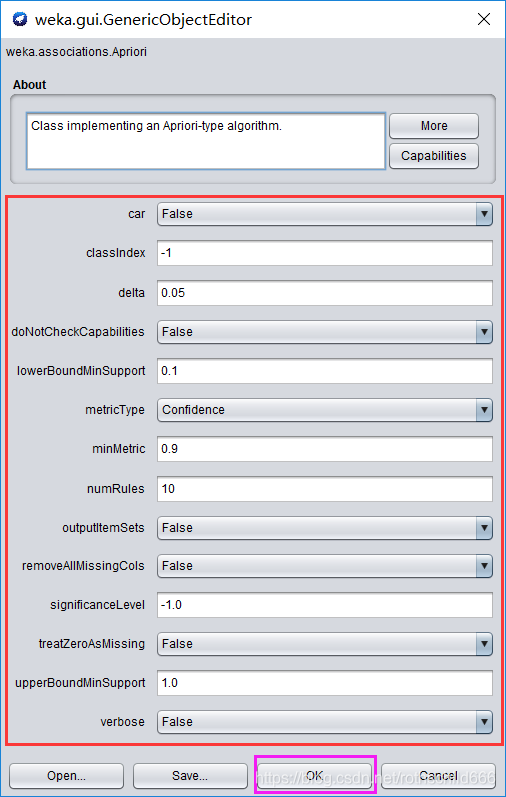
十一(重要)、页面中的参数值(见下图红色框的内容)都可以修改调动,但建议在修改调动之前现阅读下面各个参数所表达的含义和用法,若不需要修改调动,就直接可以采用系统默认的参数值;修改完之后点击紫色框内容(ok)确定修改。
1、car: 如果设为True,则会挖掘类关联规则而不是全局关联规则。
2、classindex :类属性索引。如果设置为-1,则倒数第一的属性也就是最后的属性被当做类属性。
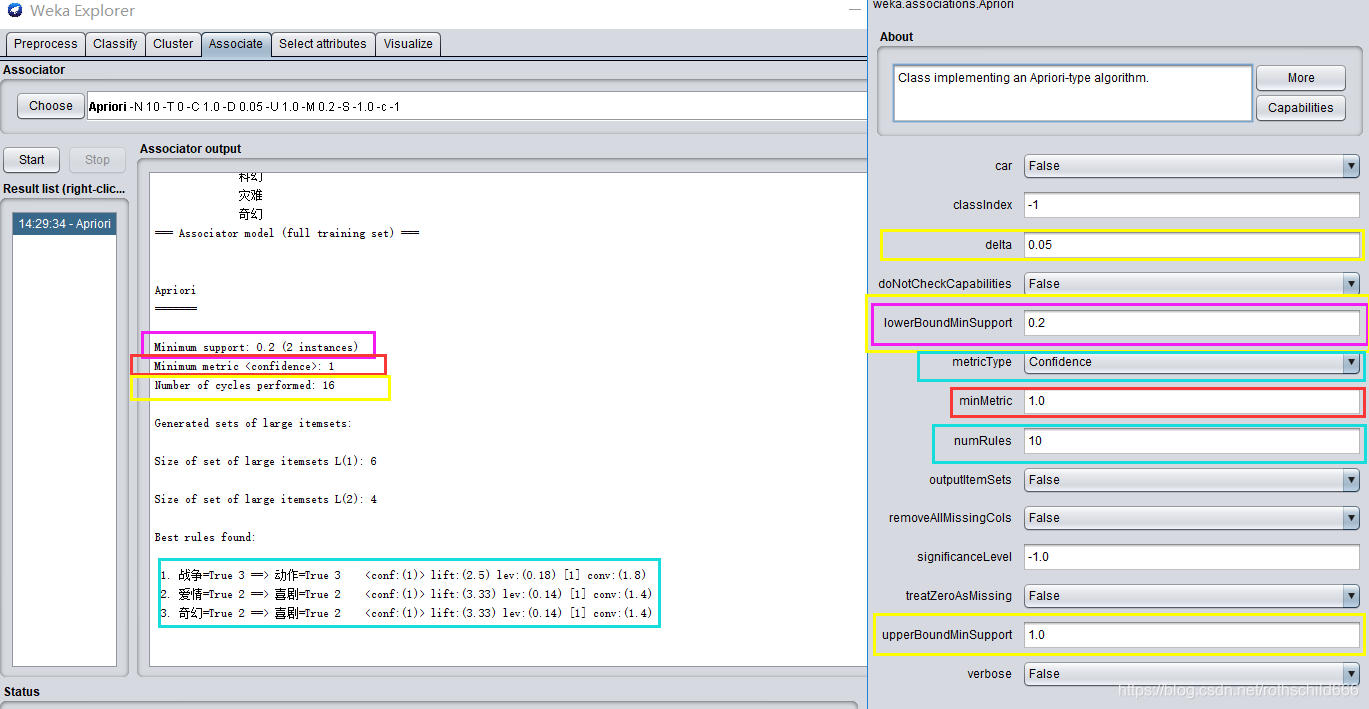
3、delta: 以该数值为迭代递减单位,然后不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。根据delta可以计算理解Number of cycles performed的公式是:
*(upperBoundMinSupport)-((Number of cycles performed)-1)delta >= (LowerBoundMinSupport)
4、lowerBoundMinSupport :最小支持度下界。
5、metricType :度量类型,设置对规则进行排序的度量依据。可以选择是:置信度(Confidence,
注意:类关联规则只能用置信度挖掘),提升度(Lift),杠杆率(Leverage),确信度(Conviction)。
(1)Confidence(conf):Confidence(A==>B)=Support(AUB)/Support(A)注意:AUB表
示同时包含A和B的支持项。比如:剧情=True 4 ==> 动作=True 2 计算出 Confidence=2/4=0.5。
(2)Lift (lift): P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度。注意:P(A)是指包含A属性数目在所有原始项目集数目的比例
(3)Leverage (lev):P(A,B)-P(A)P(B)Leverage=0时A和B独立,Leverage越大A和B的关系越密切。
(4)Conviction(conv):P(A)P(!B)/P(A,!B) (!B表示B没有发生) Conviction也是用来衡量A和B的独立性。从它和lift的关系(对B取反,代入Lift公式后求倒数)可以看出,这个值越大, A、B越关联。
6、minMtric :度量的最小值,指的是你上一步选择的度量类型的度量最小值比如默认选择了Confidence,那么Confidence的度量最小值就是minMtric设置的值,在后面生成的Best rules found中Confidence若比这个度量最小值还小就会被直接删掉不会出现,比如minMtric=0.9,Conf=0.8,则不会出现。
7、numRules :最多需要发现的规则数,会把发现的规则数进行排序,最多把前numRules个显示出来,比如numRules=10,那么就是最多显示十条规则数。
8、outputItemSets :如果设置为True,会在结果Size of set of large itemsets L(X)中输出具体项集而不仅仅是项集数目(Size of set of large itemsets)。
9、removeAllMissingCols: 移除全部为缺省值的列。
10、significanceLevel :重要程度,重要性测试(仅用于置信度)。
11、upperBoundMinSupport: 最小支持度上界,从这个值开始迭代减小到大于等于最小支持度。
12、verbose :如果设置为True,则算法会以冗余模式运行。
十二、点击紫色箭头指向的紫色框中的内容(Start)。
十三:成功生成相应关联规则(见下图)。
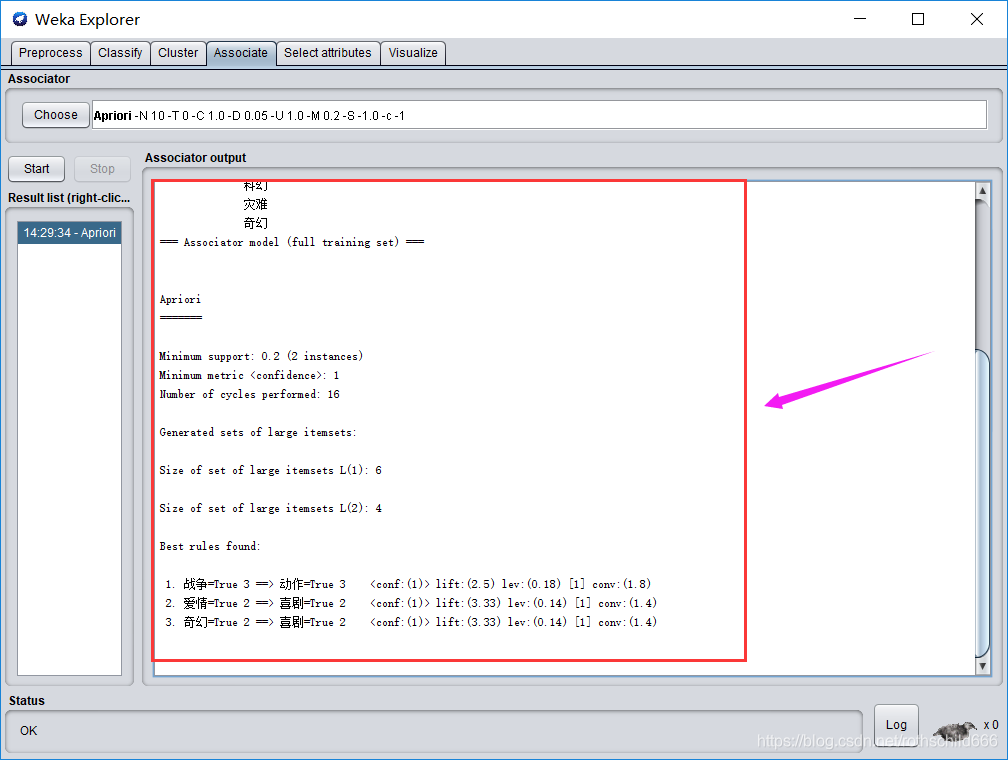
十四(重要)、相应颜色框对应相应属性值设置内容,左边颜色框的内容随右边相应颜色框的修改内容改变而改变。注意:Minimum support: 0.2 (2 instances)中instances的计算过程是:0.2X10=2。公式:四舍五入(最小支持度x项目总数)。instances的作用是为挑选minsup_count>=instances的值组成X-频繁项目集(X取1,2,3…)如下图中的L(1)是频繁项目集。Minimum metric 值的作用是:下面的Best rules found:中的conf必须大于等于Minimum metric 值才能进入频繁项目集。