
本节书摘来自华章社区《深入理解Spark:核心思想与源码分析》一书中的第1章,第1.4节Spark源码编译与调试,作者耿嘉安,更多章节内容可以访问云栖社区“华章社区”公众号查看
1.4 Spark源码编译与调试
1.下载Spark源码
首先,访问Spark官网http://spark.apache.org/,如图1-18所示。

2.构建Scala应用
使用cmd命令行进到Spark根目录,执行sbt命令。会下载和解析很多jar包,要等很长时间,笔者大概花了一个多小时才执行完。
3.使用sbt生成Eclipse工程文件
等sbt提示符(>)出现后,输入Eclipse命令,开始生成Eclipse工程文件,也需要花费很长时间,笔者本地大致花了40分钟。完成时的状况如图1-21所示。

4.编译Spark源码
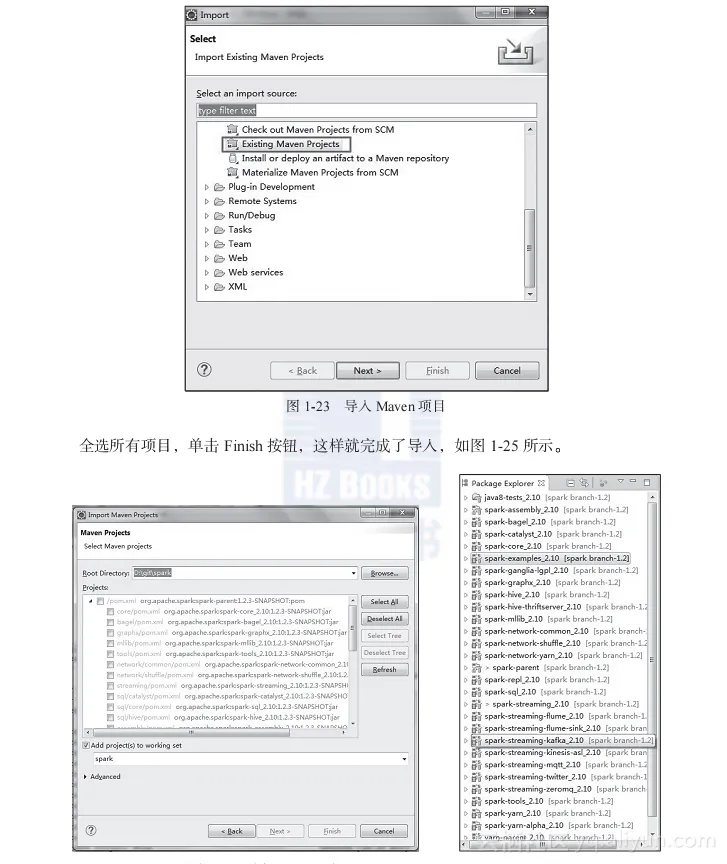
由于Spark使用Maven作为项目管理工具,所以需要将Spark项目作为Maven项目导入Eclipse中,如图1-23所示。
单击Next按钮进入下一个对话框,如图1-24所示。

单击Add External JARs按钮,将Spark项目下的lib_managed文件夹的子文件夹bundles和jars内的jar包添加进来。
lib_managed/jars文件夹下有很多打好的spark的包,比如:spark-catalyst_2.10-1.3.2-SNAPSHOT.jar。这些jar包有可能与你下载的Spark源码的版本不一致,导致你在调试源码时,发生jar包冲突。所以请将它们排除出去。
Eclipse在对项目编译时,笔者本地出现了很多错误,有关这些错误的解决建议参见附录H。所有错误解决后运行mvn clean install,如图1-27所示。
5.调试Spark源码
以Spark源码自带的JavaWordCount为例,介绍如何调试Spark源码。右击JavaWord-Count.java,选择“Debug As”→“Java Application”即可。如果想修改配置参数,右击JavaWordCount.java,选择“Debug As”→“Debug Configurations…”,从打开的对话框中选择JavaWordCount,在右侧标签可以修改Java执行参数、JRE、classpath、环境变量等配置,如图1-28所示。
读者也可以在Spark源码中设置断点,进行跟踪调试。




