

勋章









我关注的人








粉丝










技术能力
- Java
- C++
- C语言
- Python
- Shell
- Go
- Kotlin
- iOS开发
- Android开发
- 设计模式
暂时未有相关云产品技术能力~
北京阿里云ACE会长
-
发表了文章 2023-12-13
阿里云对象存储服务(OSS)
阿里云对象存储服务(OSS)是一个用于存储和访问任意类型和数量数据的云服务。在配置 OSS 访问时,需要提供 Bucket 的 Endpoint 信息,这个信息包括公网地址和私网地址。
-
发表了文章 2023-12-10
metrics-server
Metrics Server 是一个 Kubernetes 集群的附加组件,用于收集和暴露 Kubernetes 集群的运行时指标。Metrics Server 提供了 Kubernetes 集群的详细信息,包括节点、pod、service 等资源的资源使用情况、性能指标等。这些指标对于监控、诊断和优化 Kubernetes 集群的运行状况非常有用。
-
发表了文章 2023-12-09
Spyder
Spyder是一个用于数据科学和计算机视觉的Python集成开发环境(IDE)。它支持多个Python版本,并具有强大的交互式界面,可以帮助用户轻松地进行数据可视化、建模和分析。
-
发表了文章 2023-12-11
fs.oss.accessKeyId和fs.oss.accessKeySecret。
fs.oss.accessKeyId 和 fs.oss.accessKeySecret 是阿里云 OSS (Object Storage Service) 服务的两个访问密钥,用于访问和操作阿里云 OSS 存储空间中的数据。
-
发表了文章 2023-12-09
格雷码(Gray Code)
格雷码(Gray Code)是一种二进制编码方式,它使用两种不同状态的信号(通常为 0 和 1)来表示二进制位。与普通的二进制编码不同,格雷码相邻的两个二进制位之间只相差一个比特。例如,对于 4 位二进制数,格雷码可以是 0000、0001、0011、0100、0101、0110、1000、1001、1010、1011、1100、1101、1110 和 1111。
-
发表了文章 2023-12-17
DSW、DLC、EAS
DSW、DLC、EAS 是分别表示 "分布式共享内存"、"数据加载与缓存"、"增强型自动调度"的缩写,是 tuemo 工具中常用的三种技术。 1. DSW 分布式共享内存(Distributed Shared Memory)
-
发表了文章 2023-12-08
VLLM (Very Large Language Model)
VLLM (Very Large Language Model) 是一种大型语言模型,通常具有数十亿或数万亿个参数,用于处理自然语言文本。VLLM 可以通过预训练和微调来执行各种任务,如文本分类、机器翻译、情感分析、问答等。
-
发表了文章 2023-12-07
训练损失图(Training Loss Plot)
训练损失图(Training Loss Plot)是一种在机器学习和深度学习过程中用来监控模型训练进度的可视化工具。损失函数是衡量模型预测结果与实际结果之间差距的指标,训练损失图展示了模型在训练过程中,损失值随着训练迭代次数的变化情况。通过观察损失值的变化,我们可以评估模型的拟合效果,调整超参数,以及确定合适的训练停止条件。
-
发表了文章 2023-12-07
72B、1.8B、Audio模型
72B和1.8B是两个不同的模型,具体区别如下: - 72B是一个相对较大的模型,拥有72个亿个参数,而1.8B只有180亿个参数。
-
发表了文章 2023-12-09
AliOS Things、Ubuntu、Linux、MacOS、Window
AliOS Things、Ubuntu、Linux、MacOS 和 Windows 都是操作系统,用于控制计算机或其他设备的硬件和软件资源。它们有以下不同点和特点: -AliOS Thing
-
发表了文章 2023-12-02
图像降噪方法:
图像降噪方法: 图像降噪是图像处理中的一项重要任务,可以通过减少图像中的噪声来提高图像的质量。常见的降噪方法包括: - 均值滤波:对图像中的每个像素取平均值,降低噪声。 - 中值滤波:对图像中的每个像素取邻域内像素的中值,降低脉冲噪声和椒盐噪声。
-
发表了文章 2023-11-29
OpenGL(Open Graphics Library
OpenGL(Open Graphics Library,开放图形库)是一个跨平台的图形编程接口,用于渲染2D和3D图形。OpenGL是一个工业标准,广泛应用于计算机游戏、模拟、虚拟现实、科学可视化、计算机辅助设计等领域。 OpenGL的使用方法:
-
发表了文章 2023-11-27
Kaggle
Kaggle 是一个在线数据科学竞赛平台,旨在为数据科学家和机器学习工程师提供一个学习和实践的社区。在 Kaggle 上,用户可以参加各种数据科学竞赛,通过解决实际问题来提高自己的技能。Kaggle 提供了丰富的数据集和工具,支持多种编程语言,如 Python、R 和 Julia 等。
-
发表了文章 2023-11-26
Selenium
Selenium 是一个自动化测试工具,主要用于模拟用户操作浏览器。它可以控制浏览器的各种操作,如打开网页、填写表单、点击按钮等,以便进行自动化测试。Selenium 支持多种编程语言,如 Python、Java 和 C# 等。
-
发表了文章 2023-11-24
在Tkinter中显示摄像头画面
在Tkinter中显示摄像头画面,我们可以使用OpenCV库。首先,确保已经安装了OpenCV库。然后,可以按照以下步骤实现:
-
发表了文章 2023-11-24
2023-10 适用于基于 x64 的系统的 Windows Server 2012 R2 月度安全质量汇总(KB5031419)
2023-10 适用于基于 x64 的系统的 Windows Server 2012 R2 月度安全质量汇总(KB5031419)
-
发表了文章 2023-11-18
RCU(RDS Capacity Unit)
RCU(RDS Capacity Unit)是阿里云提供的云数据库RDS(Relational Database Service)的计算资源单位。RCU主要用于衡量RDS实例的计算能力,它可以帮助用户在实例的性能和成本之间实现平衡。实例的计算资源会根据实际负载自动在预设的 minimum 和 maximum 值之间进行扩缩容。
-
发表了文章 2023-11-16
数组倍增(Array Doubling
数组倍增(Array Doubling)是一种常见的算法技术,用于解决数组相关的查找、插入、删除等问题。该技术的核心思想是将数组的大小乘以 2,新数组的长度是原数组长度的两倍,然后将原数组中的元素复制到新数组中。在某些情况下,这种技术可以提高算法的效率,尤其是对于动态数据结构的问题。
-
发表了文章 2023-11-14
路径压缩 (Path Compression)
路径压缩 (Path Compression) 是一种用于求解最短路径问题的算法,通常用于 Dijkstra 算法中,可以加速求解最短路径问题。 路径压缩通过将已经确定的最短路径信息传递给未确定最短路径的节点,来加速最短路径的计算。具体来说,当一个节点的最短路径已经确定时,它会将这个信息传递给所有它的邻居节点,这样邻居节点就可以跳过一些不必要的计算,直接使用已经确定的最短路径信息,从而加速整个最短路径的计算过程。
-
发表了文章 2023-11-11
稳定排序
稳定排序是指在排序过程中,相同元素在排序后保持原有顺序不变。换句话说,对于相同的关键字,它们在排序后的序列中的相对位置不会发生改变。
-
发表了文章 2023-11-09
凸多边形(Convex Polygon
凸多边形(Convex Polygon)是一个几何概念,它指的是一个多边形,其内部的所有点都位于多边形的外部。简单来说,凸多边形是一个内部没有凹陷的多边形。
-
发表了文章 2023-11-06
离线网络搜索
离线网络搜索是指在本地计算机或移动设备上进行网络搜索,而不是通过互联网连接到远程服务器进行搜索。这种技术可以用于在没有网络连接或网络连接不稳定的情况下进行搜索,或者出于隐私或安全考虑而需要保护搜索历史记录和搜索活动。
-
发表了文章 2023-11-05
在线网络搜索
在线网络搜索是指通过互联网连接到远程服务器,使用搜索引擎对网络上的信息进行检索和查找。这种搜索方式是我们日常生活中最常用的搜索方式。在线网络搜索可以帮助用户在短时间内找到大量相关的信息,提高信息获取的效率。以下是在线网络搜索的使用方法、适用场景和示例:
-
发表了文章 2023-11-04
双端优先级队列(Double-Ended Priority Queue
双端优先级队列(Double-Ended Priority Queue)是一种支持在两端进行插入和删除操作的优先级队列。它可以在 O(log n) 的时间复杂度内完成插入、删除、查询操作。双端优先级队列可以使用二叉堆或线段树等数据结构实现。
-
发表了文章 2023-11-04
下三角矩阵(Lower Triangular Matrix)
下三角矩阵(Lower Triangular Matrix)是一种特殊形式的矩阵,其非零元素仅位于主对角线以下。在数学和工程领域中,下三角矩阵通常用于线性代数和微积分等问题。以下是一些关于下三角矩阵的特点和应用:
-
发表了文章 2023-11-03
对角矩阵(Diagonal Matrix)
对角矩阵(Diagonal Matrix)是一种特殊的矩阵,其元素仅位于主对角线上。对角矩阵通常用于线性代数和微积分等数学领域,它有以下几个特点:
-
发表了文章 2023-11-03
三对角矩阵(Triangular Matrix)
三对角矩阵(Triangular Matrix)是一种特殊形式的矩阵,其非零元素仅位于主对角线以及主对角线两侧的相邻对角线上。三对角矩阵在数学、工程和计算机科学等领域中都有广泛应用,特别是在线性代数中。以下是一些关于三对角矩阵的特点和应用:
-
发表了文章 2023-11-02
对角矩阵(Diagonal Matrix)
对角矩阵(Diagonal Matrix)是一种特殊的矩阵,其元素仅位于主对角线上。对角矩阵通常用于线性代数和微积分等数学领域,它有以下几个特点:
-
发表了文章 2023-11-02
上三角矩阵(Upper Triangular Matrix
上三角矩阵(Upper Triangular Matrix)是一种特殊形式的矩阵,其非零元素仅位于主对角线以上。在数学和工程领域中,上三角矩阵通常用于线性代数和微积分等问题。以下是一些关于上三角矩阵的特点和应用:
-
发表了文章 2023-10-31
稠密矩阵
稠密矩阵是一种特殊形式的矩阵,其中所有元素都是非零的。与稀疏矩阵相比,稠密矩阵在存储和计算时需要更多的空间和计算资源,因为它的所有元素都需要被存储和计算。
-
发表了文章 2023-10-30
递归工作栈(Recursive Workstation Stack)
递归工作栈(Recursive Workstation Stack)是一种在计算机程序中实现递归计算的机制,通过使用栈来跟踪递归调用的过程,从而实现对复杂问题的求解。递归工作栈在解决具有自相似结构的问题时非常有用,例如计算斐波那契数列、解决迷宫问题等。
-
发表了文章 2023-10-28
负载因子(Load Factor)
负载因子(Load Factor)是一个用于衡量散列表(如哈希表)填充程度的参数。它表示在散列表中,当插入一个新的键值对时,可以允许的最大填充程度。负载因子越大,
-
发表了文章 2023-10-27
均匀散列函数(Uniform Hash Function)
均匀散列函数(Uniform Hash Function)是一种将不同长度的输入数据映射到相同大小的输出数据的散列函数。均匀散列函数的主要特点是,对于相同的输入数据,无论其长度如何,都会得到相同的输出散列值。这种散列函数常用于数据结构的存储和查找,例如哈希表、散列表等。
-
发表了文章 2023-10-26
负载因子(Load Factor)
负载因子(Load Factor)是一个用于衡量散列表(如哈希表)填充程度的参数。它表示在散列表中,当插入一个新的键值对时,可以允许的最大填充程度。负载因子越大,
-
发表了文章 2023-10-21
语句覆盖
语句覆盖是一种白盒测试方法,用于确保程序中的每一条语句至少执行一次。它是测试用例设计的一种策略,可以帮助开发人员和测试人员确定代码中的所有路径,并确保每个语句都经过测试。
-
发表了文章 2023-10-21
霍纳法则
霍纳法则(Horner's Rule)是一种求解线性方程组的迭代算法,是由英国数学家威廉·霍纳(William Horner)在 1839 年发现的。该算法是一种高斯消元法的简化版本,适用于具有特定条件的三元一次方程组。
-
发表了文章 2023-10-19
数据空间
数据空间(Data Space)是计算机系统中用于存储和管理数据的区域。数据空间包括处理器内部的寄存器、数据缓存(Data Cache)以及内存中的数据段(Data Segment)等。数据空间的作用是接收、存储和处理来自外部设备或程序的数据,从而实现计算机系统的功能。
-
发表了文章 2023-10-15
分支覆盖 (Branch Coverage)
分支覆盖 (Branch Coverage) 是一种软件测试覆盖率评估方法,能够测量代码中每个分支的执行情况,即代码中每个条件语句 (if-else 语句) 的所有可能分支是否都被执行过。
-
发表了文章 2023-10-14
海明距离(Hamming Distance)
海明距离(Hamming Distance)是用来衡量两个二进制数之间差异程度的指标,它表示两个二进制数之间最多有多少个比特的差异。海明距离可以用于衡量数据传输或存储中的错误率,以及检测噪声干扰。 海明距离的计算方法是:对于两个 n 位二进制数,将它们进行逐位比较,如果对应位上的数字不同,则计算距离时增加 1。然后将所有位上的距离加在一起,得到海明距离。
-
发表了文章 2023-10-13
Induction hypothesis(归纳假设
Induction hypothesis(归纳假设)是一种基于归纳推理的假设或推测,通常用于科学、工程和数学等领域中。它是一种从特殊情况或实例中推断出一般性结论或规律的方法。归纳假设是基于观察到的数据或现象,通过对这些数据或现象进行总结和归纳,从而得出一个更普遍的结论或规律。 使用归纳假设的方法可以分为以下几个步骤:
-
发表了文章 2023-10-12
V 语言
V 是一门通用的编程语言,也可以作为系统语言,其网站说它非常简单,你可以在一个周末学会,它还说 Go 程序员会对该语言非常熟悉,因为 V 语言在很多方面借鉴了 Go。
-
发表了文章 2023-10-11
Zig
Zig 是一门系统编程语言,旨在提供一种简单、安全且高效的方式来构建软件。它的设计受到了 Rust、C 和 C++ 的影响,但与这些语言相比,Zig 更加简单易用。Zig 的语法和抽象级别使得它易于学习和使用,同时它还提供了许多现代编程语言的功能,如高级类型、模块化编程和内存安全等。
-
发表了文章 2023-10-10
Flutter
Flutter 是 Google 开发的一款开源 UI 工具包,它可以帮助开发者使用一套代码库快速构建美观且高性能的 Android 和 iOS 应用程序。Flutter 具有热重载(Hot Reload)和快速应用程序开发(Rapid Application Development)的特点,使得开发过程更加高效。
-
发表了文章 2023-10-10
Gleam
Gleam 是面向 Erlang 虚拟机的类型化语言,Gleam 的语法对于类型化语言来说非常优雅和简单。如果能看到 Gleam 像 Elixir 一样成功,那就太酷了。
-
发表了文章 2023-10-08
Best Matching Unit,简称 BMU
最佳匹配单元(Best Matching Unit,简称 BMU)是自组织映射(Self-Organizing Maps,简称 SOM)算法中的一个重要概念。在 SOM 网络中,每个神经元都对应一个权重向量,表示该神经元对输入特征的响应。BMU 是指在 SOM 网络中与输入数据最相似的神经元,即具有与输入数据最接近的权重向量。在训练过程中
-
发表了文章 2023-10-06
FactorVM
FactorVM 是 Factor 语言的一个虚拟机,它可以在多个平台上运行 Factor 代码,包括 Windows、Linux、MacOS、Java 和 JavaScript。如果你想学习 FactorVM,以下是一些推荐的学习资料: 1. FactorVM 官方文档:FactorVM 的官方文档是学习 FactorVM 的最佳资料。官方文档提供了 FactorVM 的详细介绍,包括其架构、运行机制、API 等。你可以访问 FactorVM 的官方文档 (https://github.com/factorio/factorvm) 来学习更多信息。 2. Factor 语言教程:Factor
-
发表了文章 2023-10-05
LPO(Link Protection On)
LPO(Link Protection On)是思科交换机上的一种链路保护机制,用于防止网络中的链路层攻击,如欺骗攻击、地址欺骗攻击等。LPO 通过在网络设备之间建立信任关系,并使
-
发表了文章 2023-10-04
APIv3
APIv3 是指第三代 API(应用程序编程接口),通常用于帮助开发者更轻松地访问和集成第三方服务和功能。APIv3 通常提供更高的性能、更好的安全性和更简单的使用方法。APIv3 可以是特定平台或服务(如支付宝、微信支付等)的 API。
-
发表了文章 2023-10-04
SmartPLS 4.0
SmartPLS 4.0
-
发表了文章 2023-10-03
Bartlett 球 形检验
Bartlett 球 形检验
-
 发表了文章
2024-05-28
发表了文章
2024-05-28
WebSocket 协议
-
发表了文章
2024-05-28
Project Object Model
-
发表了文章
2024-05-28
Model-View-Controller
-
发表了文章
2024-05-27
MongoDB
-
发表了文章
2024-05-27
模型评估
-
发表了文章
2024-05-27
JDK序列
-
发表了文章
2024-05-26
网络安全
-
发表了文章
2024-05-26
模型评估
-
发表了文章
2024-05-26
神经网络
-
发表了文章
2024-05-25
FinOps
-
发表了文章
2024-05-25
Copilot+ PC
-
发表了文章
2024-05-25
pid巡线
-
发表了文章
2024-05-24
RocketMQ
-
发表了文章
2024-05-24
MSE Sentinel vs OpenSergo
-
发表了文章
2024-05-24
Volcano 火山模型到 Pipeline
-
发表了文章
2024-05-23
位运算
-
发表了文章
2024-05-23
傅里叶
-
发表了文章
2024-05-23
YOLO
-
发表了文章
2024-05-23
YOLO
-
发表了文章
2024-05-22
RGB颜色模型和HSV颜色模型

-
 回答了问题
2024-05-29
回答了问题
2024-05-29
Hologres这个update 语句执行了20s,要换行存?
数据量大小:更新了大量的行。
索引设计:没有有效的索引来加速更新操作。
网络延迟:数据分布在网络上,更新操作需要跨节点通信。赞0 踩0 评论0 -
回答了问题
2024-05-29
Hologres这个用什么格式?默认吗?
属性不匹配的问题。在 Hologres 中,table orientation 指的是表的数据组织方式,可以是行或列。而 storage format 指的是数据存储的格式,比如 ORC(Optimized Row Columnar)是一种用于列存储的文件格式,它支持高压缩比和高性能的列式访问。
赞0 踩0 评论0 -
回答了问题
2024-05-29
Hologres更新的时候会根据主键读取行存数据,针对更新列去更新列存数据?
行存数据:
行存格式适合于高并发的点查和更新操作。
当执行更新操作时,Hologres 会根据主键定位到具体的行数据。
列存数据:列存格式适合于分析型查询,尤其是当查询涉及到的数据列较少时。
列存数据通常在后台进行维护,例如,通过异步的方式进行数据的整理,以优化查询性能。赞0 踩0 评论0 -
回答了问题
2024-05-29
最近大模型降价潮,哪家才是真的“价美”也“物美”?
回复模版,A更简介明了,xiag
相对较差。
卡死
我们需要求解快车从起点到终点共用的时间。我们可以先计算慢车的总时间,再利用快车和慢车的速度关系来求解快车的时间。
慢车的行程时间计算:
慢车停留时间计算:慢车停15个车站,每站停留2分钟,总停留时间为 (2 \times 15 = 30) 分钟。
慢车的行驶时间(不包括停留时间):假设慢车的速度为 (v),慢车行驶的时间为 (t) 分钟。
因为慢车从起点到终点共用 (t + 30) 分钟。
快车的行程时间计算:
快车的速度是慢车的1.5倍,即快车的速度为 (1.5v)。
快车只停一次,这段停留时间为2分钟。
假设快车的行驶时间(不包括停留时间)为 (T) 分钟。
因为快车从起点到终点共用 (T + 2) 分钟。
根据题意,快车是在慢车发出60分钟后出发,且两车同时到达终点:
[ t + 30 = T + 60 + 2 ]简化方程:
[ t + 30 = T + 62 ]
[ t = T + 32 ]速度关系:
慢车行驶的总距离与快车行驶的总距离相同。
慢车的行驶时间为 (t),快车的行驶时间为 (T)。
因为 (快车速度 = 1.5 \times 慢车速度),所以我们有:
[ \frac{\text{总距离}}{T} = 1.5 \times \frac{\text{总距离}}{t} ]
[ \frac{1}{T} = 1.5 \times \frac{1}{t} ]
[ t = 1.5T ]
根据 (t = T + 32),代入 (t = 1.5T):
[ 1.5T = T + 32 ]
[ 1.5T - T = 32 ]
[ 0.5T = 32 ]
[ T = 64 ]所以,快车从起点到终点的行驶时间为 (T = 64) 分钟,加上停留的2分钟,总时间为:
[ 64 + 2 = 66 ] 分钟。因此,快车从起点到终点共用66分钟。
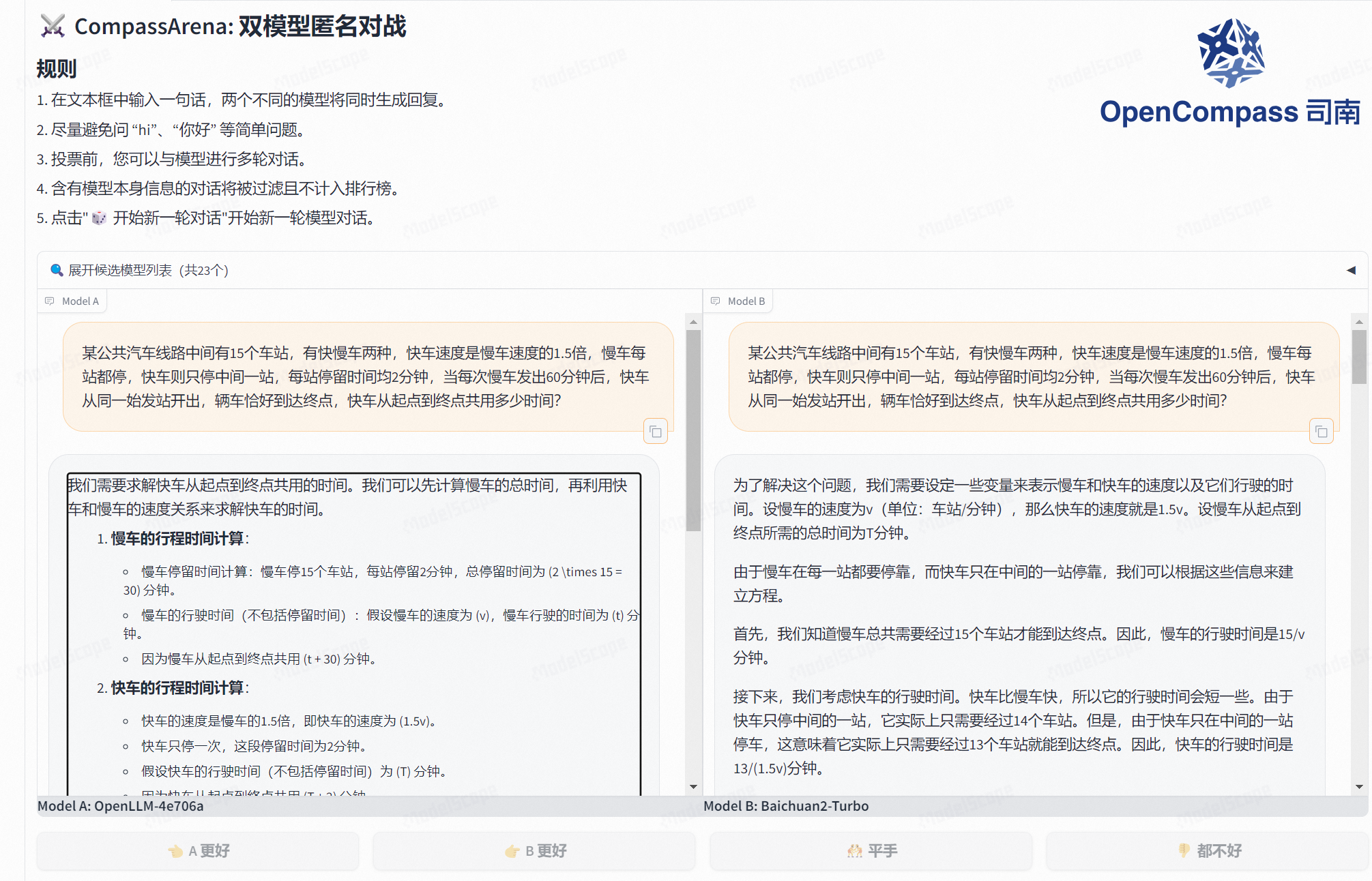
答案精准第一位
速度 高效 第二位
表达高效 第三位
使用遍历 成本 较低。
赞3 踩0 评论0 -
回答了问题
2024-05-28
请问Android性能高的具体参数或者指标是什么?
处理器(CPU):
核心数:多核处理器可以同时处理更多任务。
主频:处理器的时钟频率,通常以 GHz 计量,频率越高,处理速度越快。
架构:更先进的架构可以提供更高的性能和能效比。
图形处理器(GPU):GPU 的性能直接影响图形密集型应用和游戏的流畅度。
支持的图形 API 级别,如 OpenGL ES、Vulkan 等。赞0 踩0 评论0 -
回答了问题
2024-05-28
性能分析的SDK接入后,gradle编译报错,再编译就不报,然后一直循环,这是什么问题?
插件应用冲突:
如果项目中使用了多个插件,可能存在冲突。检查 build.gradle 文件中是否正确应用了所有插件。
Gradle Daemon 问题:有时 Gradle Daemon 可能遇到问题导致编译失败。尝试停止 Gradle Daemon 进程并重新编译:
./gradlew --stop赞0 踩0 评论0 -
回答了问题
2024-05-28
使用websocket请求asr 返回40000002错误码
检查消息格式:
确保发送的消息格式符合服务器的要求。检查 JSON 对象是否完整且格式正确。
检查编码问题:如果消息中包含特殊字符,确保它们被正确编码。
赞0 踩0 评论0 -
回答了问题
2024-05-28
快速部署MC服务器
配置服务器:
编辑 server.properties 文件,根据需要配置服务器设置,比如游戏模式、难度、玩家数量等。
启动服务器:运行服务器软件中的启动脚本(可能是一个可执行文件或一个批处理脚本)。
赞1 踩0 评论0 -
回答了问题
2024-05-28
请问android上怎么保持服务不被杀死?类似微信通知服务,一直都能收到消息。
进程守护
使用前台服务
将服务设置为前台服务,这样可以提高其优先级,减少被系统杀死的可能性。前台服务需要显示一个持续性的通知给用户,告知服务正在进行的活动。Notification notification = ...; // 创建通知
startForeground(NOTIFICATION_ID, notification); // 将服务提升为前台服务
请求高优先级
在 Android 8.0(API 级别 26)及以上版本中,可以使用 setProcessImportance 方法请求高优先级。Process.setProcessImportance(Process.IMPORTANCE_HIGH);
使用工作服务
使用 startForegroundService() 或 JobScheduler、WorkManager API 来启动服务,这些方法允许系统更灵活地管理服务,同时保持服务的稳定性。进程守护技术
创建一个守护服务,当主服务被杀死时,守护服务会重新启动它。这种方法需要两个服务相互监听对方的状态,并在对方被杀死时重启对方。// 主服务中
Intent intent = new Intent(this, GuardianService.class);
startService(intent);// 守护服务中
Intent intent = new Intent(this, MainService.class);
PendingIntent pendingIntent = PendingIntent.getService(this, 0, intent, 0);
AlarmManager alarmManager = (AlarmManager) getSystemService(Context.ALARM_SERVICE);
alarmManager.setInexactRepeating(AlarmManager.ELAPSED_REALTIME,
0, AlarmManager.INTERVAL_HALF_HOUR, pendingIntent);// 监听主服务是否被停止,并在需要时重启
监听系统广播
监听系统广播,如 ACTION_PACKAGE_RESTARTED 或 ACTION_SHUTDOWN,来重启服务。IntentFilter filter = new IntentFilter();
filter.addAction(Intent.ACTION_SHUTDOWN);
filter.addAction(Intent.ACTION_PACKAGE_RESTARTED);
filter.addDataScheme("package");
registerReceiver(serviceReceiver, filter);赞0 踩0 评论0 -
回答了问题
2024-05-28
当AI“复活”成为产业,如何确保数字生命技术始终用于正途?
AI“复活”或数字生命技术的兴起确实带来了许多潜在的好处,比如在教育、娱乐、心理健康支持等领域的应用。然而,这项技术也引发了伦理、法律和社会方面的挑战。
可以考虑几个方面
制定明确的法律法规
制定相关的法律法规来规范数字生命技术的用途,保护个人隐私,防止滥用。法律应该明确界定什么可以做,什么不可以做,并对违规行为设定严格的惩罚措施。
强化伦理审查
建立伦理审查委员会,对数字生命技术的应用进行伦理评估。确保技术的应用不会侵犯个人权利,不会对社会造成负面影响。
增强透明度和可解释性
技术开发者应该提高算法的透明度和可解释性,让用户了解他们的数据如何被使用,以及数字生命是如何被创建和运作的。
公众教育和意识提升
通过教育和公共宣传提高公众对数字生命技术的认识,包括它的好处和潜在风险,使公众能够做出明智的决策。
赞4 踩0 评论0 -
回答了问题
2024-05-28
一条SQL语句的执行究竟经历了哪些过程?
一条 SQL 语句的执行过程确实包含了许多步骤,
- 客户端提交 SQL 语句
用户通过客户端工具(如命令行、图形界面工具或应用程序)编写并提交 SQL 语句。 - 语法解析
数据库服务器接收到 SQL 语句后,首先进行语法解析。解析器检查 SQL 语句的语法是否正确,如关键字是否准确、语法结构是否符合规则等。 - 语义分析
接下来进行语义分析,这一步解析器检查 SQL 语句中的数据库对象(表、列等)是否存在,以及用户是否对这些对象有相应的操作权限。 - 优化器选择执行计划
解析和优化器将 SQL 语句转换成一个或多个执行计划。优化器负责选择最佳的查询计划,这涉及到选择不同的索引、确定表的连接顺序、决定使用哪种类型的连接算法等。 - 权限检查
在执行前,系统还会进行权限检查,确保执行该语句的用户具有足够的权限。 - 执行 SQL 语句
执行计划被送到执行引擎,开始实际的查询或更新操作。对于查询语句,这可能涉及到:
索引查找:如果语句中包含 WHERE 子句,数据库可能会使用索引来快速定位到相关的数据行。
表扫描:如果没有可用的索引或索引不适用,则进行全表扫描。
连接操作:对于涉及多个表的查询,执行诸如嵌套循环连接、哈希连接等操作。
排序操作:如果语句中包含 ORDER BY 子句,执行排序操作。 - 结果集处理
查询结果被返回并可能经过进一步的处理,如聚合计算(GROUP BY 和聚合函数)。 - 返回结果
处理完成的结果集被发送回客户端。 - 缓存和写入
对于更新操作(如 INSERT、UPDATE、DELETE),数据库会先将更改写入到事务日志中以保证事务的持久性和恢复能力,然后将更改应用到数据页上。
数据库可能还会利用缓存来提高性能,将频繁访问的数据保留在内存中。 - 事务管理
如果 SQL 语句是事务的一部分,数据库会确保它要么完全应用,要么在出现错误时完全回滚,以保持数据的一致性。 - 日志记录
数据库会记录操作日志,用于监控、调试和性能分析。
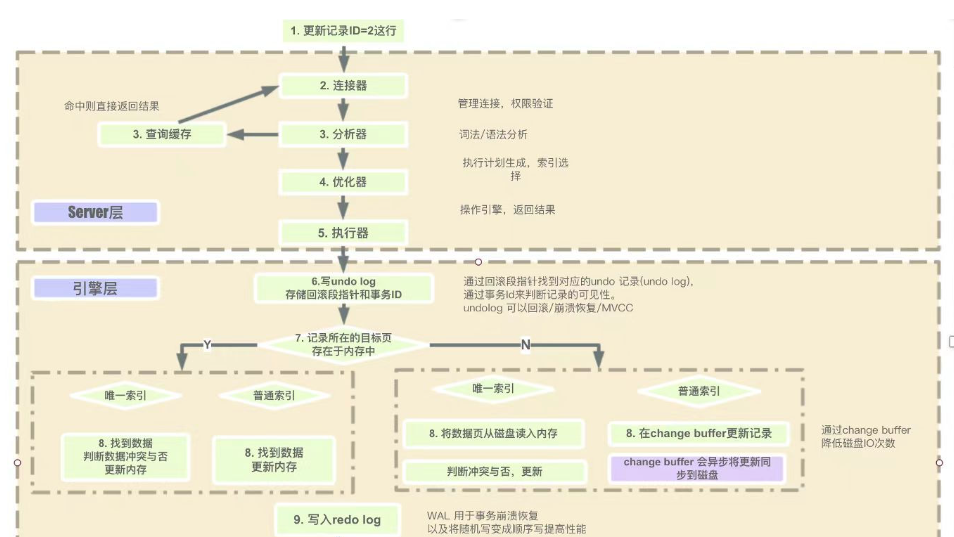 赞6 踩0 评论0
赞6 踩0 评论0 - 客户端提交 SQL 语句
-
回答了问题
2024-05-27
为什么 PAI DSW中一直无法使用GPU加速tensorflow,如何使用GPU加速.
cuDNN注册问题:错误信息Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered表明cuDNN工厂已经被注册,可能存在版本冲突或初始化问题。
cuFFT和cuBLAS注册问题:类似的注册问题也出现在cuFFT和cuBLAS上,这可能与TensorFlow试图加载的GPU操作库有关。
赞1 踩0 评论0 -
回答了问题
2024-05-27
web terminal 下面没有Chrome浏览器按钮
Web Terminal设置问题:
检查Web Terminal的设置,看是否有选项可以启用或显示Chrome浏览器按钮。
权限问题:确认你的账户权限是否允许使用Web Terminal的所有功能。
赞0 踩0 评论1 -
回答了问题
2024-05-27
在云效中工作任务导入显示失败,如何解决?
检查文件大小和行数:如果文件过大或行数过多,可能会导致导入失败。尝试将数据拆分成更小的文件进行导入。
检查网络连接:不稳定的网络连接可能会导致导入过程中断,确保网络环境稳定。
赞1 踩0 评论0 -
回答了问题
2024-05-27
在云效中按导出格式,导入怎么显示失败,如何解决?
使用最新版本的Excel:如果你使用的是较旧版本的Excel创建或编辑文件,可能会遇到兼容性问题。尝试使用最新版本的Excel打开和保存文件。
检查文件完整性:如果文件损坏,它可能无法被正确解析。尝试重新创建文件或从备份中恢复。
赞0 踩0 评论0 -
回答了问题
2024-05-26
报错的都是oom,显存爆了,不用加哪些modelscope参数?
减小批量大小(Batch Size):
如果命令中可以指定批量大小,尝试减小它。较小的批量大小会减少每次迭代的显存需求。
调整--quant_n_samples和--quant_seqlen:对于AWQ量化,减小--quant_n_samples(默认值通常是256)和--quant_seqlen(默认值通常是2048)可以减少量化过程中的显存占用。
赞2 踩0 评论0 -
回答了问题
2024-05-26
请问modelscope中做量化swift和tensorRT llm有区别吗?
Swift支持使用AWQ、GPTQ、BnB、HQQ、EETQ等技术对模型进行量化。
Swift的量化可以用于推理加速,并且量化后的模型支持QLoRA微调。
Swift提供了命令行工具来执行量化操作,例如使用AWQ进行INT4量化,并支持自定义量化数据集。赞5 踩0 评论0 -
回答了问题
2024-05-26
7b chat做modelscope awq的int4量化,特别容易爆显存,怎么解决?
分批处理:
如果模型太大,无法一次性加载到GPU中,可以考虑将数据分批处理,每次只处理模型的一部分。
梯度累积:使用梯度累积技术,通过在多个小批量上累积梯度,然后一次性更新权重,这样可以减少每次迭代所需的显存。
赞6 踩0 评论0 -
回答了问题
2024-05-25
将用户上传的文件信息及上传记录保存到 MaxCompute 表中上传记录?
的业务需求来设计。例如:
file_upload 表可能包含以下列:file_id, user_id, file_name, file_size, file_type, upload_time 等。
upload_record 表可能包含以下列:record_id, file_id, upload_status, start_time, end_time 等。赞3 踩0 评论0 -
回答了问题
2024-05-25
阿里云c++sdk实时语音识别嵌入mrcp
确保Lua脚本传递的参数正确无误,并且C++ SDK能够正确解析和应用这些参数。检查是否有任何缓存或旧配置影响当前设置。
检查C++ SDK中关于超时逻辑的实现。可能是识别超时和无输入超时的逻辑叠加了,需要调整逻辑以确保它们不会相互累积。
赞4 踩0 评论0