







围绕 transformers 构建现代 NLP 开发环境
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。
阿里云开源离线同步工具DataX3.0介绍
阿里云开源离线同步工具DataX3.0介绍 一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

odps是什么?
ODPS(Open Data Processing Service),原是阿里云从 09年开始自研的大规模批量计算引擎,2016 年更名为MaxCompute。2022云栖大会上,阿里云ODPS全新升级为一体化大数据平台,存储、调度、元数据一体化融合 ,从 Processing 升级为 Platform,即 Open Data Platform and Service。提供了离线计算、实时交互式分析、机器学习等可扩展的智能计算引擎,满足用户多元化数据计算需求。
拍立淘-以图搜图中的图像搜索算法
移动端的以图搜图是一代又一代的图像人,搜索人的梦想。从90年代开始,学术界,工业界做了很多的努力和尝 试。拍立淘-以图搜图,从14年正式立项开始,通过算法/工程/产品的不断打磨,以及兄弟部门的紧密合作,在业务指标的增长的同时,沉淀下来了业界领先的图搜算法。
数据仓库介绍与实时数仓案例
1.数据仓库简介 数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
美柚:最懂女性App背后的混合云架构与大数据服务
本次美柚带来的分享包括如何充分利用现有机房服务器资源与阿里云产品组建混合云架构,实现快速部署与大数据的处理与计算服务。同时也详细介绍了美柚在多维度用户数据分析处理和大数据智能挖掘技术的实践经验。
MaxCompute执行作业慢的原因排查
大家在平时开发过程中经常遇到作业(SQL、MR等)执行慢的原因,今天带大家一起学习自排查方法。 1、wait wait ,job querying 遇到这个提示,就是资源出现了排队,如果你是后付费用户,那就是整个后付费的共享池已经没有富余的资源了,要等前一个作业处理完。
优酷背后的大数据秘密
大家好,我是门德亮,现在在优酷数据中台做数据相关的事情。很荣幸,我正好见证了优酷从没有MaxCompute到有的这样一个历程,因为刚刚好我就是入职优酷差不多5年的时间,我们正好是在快到5年的时候,去做了从Hadoop到MaxCompute的这样一个升级。
权威详解 | 阿里新一代实时计算引擎 Blink,每秒支持数十亿次计算
阿里巴巴需要研发世界级一流的流式计算引擎,实时处理海量数据,提供在线统计、学习和预测能力,不仅支持阿里巴巴自己的核心电商场景,同时也能通过阿里云向外部中小企业提供流式计算服务,输出实时计算能力,这就是我今天要分享的最新一代阿里巴巴实时计算引擎Blink。
Kibana:数据分析的可视化利器
阿里云Elastisearch集成了可视化工具Kibana,用户可以使用Kibana的开发工具便捷的查询和分析存储在Elastisearch中的数据。除了柱状图、线状图、饼图、环形图等经典可视化功能外,还拥有地理位置分析、数据图谱分析、时序数据分析等高级功能。
使用 odps-jdbc 接入 ODPS,不再从零开始
还在为传统 DBMS 的性能问题而烦恼?想借助 ODPS 的分布计算能力?但是你又不想学习官方的 SDK ?如果你恰好在老项目中用了 JDBC 访问 Oracle 或 MySQL?那么你可能对这篇文章感兴趣。本文将结合几种常见的使用场景(数据查询、数据导入、第三方客户端工具)来介绍odps-jdbc
阿里云MaxCompute 2019-5月刊
5月MaxCompute新功能发布,精彩技术好文推荐,技术干货下载,6月重要活动抢先知道,尽在5月刊。
[ETL实践指南]基于Kettle的MaxCompute插件实现数据上云
本文用到的 阿里云数加-大数据计算服务MaxCompute产品地址:https://www.aliyun.com/product/odps 简介 Kettle是一款开源的ETL工具,纯java实现,可以运行于Windows, Unix, Linux上运行,提供图形化的操作界面,可以通过拖拽控件的方式,方便地定义数据传输的拓扑。
阿里数据仓库实践分享
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
Flume+Kafka+Flink+Redis构建大数据实时处理系统:实时统计网站PV、UV展示
1.大数据处理的常用方法 大数据处理目前比较流行的是两种方法,一种是离线处理,一种是在线处理,基本处理架构如下: 在互联网应用中,不管是哪一种处理方式,其基本的数据来源都是日志数据,例如对于web应用来说,则可能是用户的访问日志、用户的点击日志等。
流计算精品翻译: The Dataflow Model
我们提出了Dataflow模型,并详细地阐述了它的语义,设计的核心原则,以及在实践开发过程中对模型的检验。

回顾 | Kafka x Flink Meetup 与世界人工智能大会大数据 AI 专场精彩回顾(附PPT下载)
8 月最后一天,由 Apache Kafka 与 Apache Flink 联合举办的 Meetup 深圳站圆满落幕,现场站无虚席,来自 Confluent 、中国农业银行 、虎牙直播、数见科技以及阿里巴巴的五位技术专家带来了丰富精彩的分享,全场干货满满!
MaxCompute上如何处理非结构化数据
0. 前言 MaxCompute作为阿里云大数据平台的核心计算组件,拥有强大的计算能力,能够调度大量的节点做并行计算,同时对分布式计算中的failover,重试等均有一套行之有效的处理管理机制。 而MaxCompute SQL能在简明的语义上实现各种数据处理逻辑,在集团内外更是广为应用,在其上实现
倒计时1天!相约杭州云栖,相遇数据智能
2016杭州云栖大会盛大开启,与阿里云大数据一起相约杭州云栖,相遇数据智能!我们精心准备了四大智能看点,等你用一颗大数据的心,鞠一捧智能的“水”。
PyOdps DataFrame来临,数据分析从未如此简单!
PyOdps正式发布DataFrame框架(此处应掌声经久不息),DTer的福音!有了它,就像卷福有了花生,比翼双飞,哦不,如虎添翼。 快过年了,大家一定没心情看长篇大论的分析文章。作为介绍PyOdps DataFrame的开篇文章,我只说说其用起来爽的地方。其余的部分,从使用、问题到实现原理,我
SQL优化器原理 - Join重排
这是MaxCompute有关SQL优化器原理的系列文章之一。我们会陆续推出SQL优化器有关优化规则和框架的其他文章。添加钉钉群“关系代数优化技术”(群号11719083)可以获取最新文章发布动态。 本文的目标是解释Join重排这个特性的基础概念和算法,如果想快速了解并在MaxCompute上使用这个特性,请直接跳到“总结”。
在PyODPS DataFrame自定义函数中使用pandas、scipy和scikit-learn
背景 [PyODPS DataFrame]http://pyodps.readthedocs.io/zh_CN/latest/) 提供了类似 pandas 的接口,来操作 ODPS 数据,同时也支持在本地使用 pandas,和使用数据库来执行。
阿里云大数据计算平台的自动化、精细化运维之路
作者简介: 范伦挺 阿里巴巴 基础架构事业群-技术专家 花名萧一,2010年加入阿里巴巴,现任阿里巴巴集团大数据计算平台运维负责人。团队主要负责阿里巴巴各类离在线大数据计算平台(如MaxCompute、AnalyticDB、StreamComput
阿里封神-大数据处理技术漫谈
以前一篇博客,从宏观描述了云梯1当时整体生态,年底了,笔者再梳理下软件栈,主要以开源软件为主,闭源不谈。大数据发展至今,开源软件层出不穷,也去解决了不同的问题,笔者试图去弄清楚这些,分门别类,后面也可以参照下。由于笔者知识面有限,难免会出现一些偏颇,不全,不正确,还请指正。后面也会有很多新的软件出现
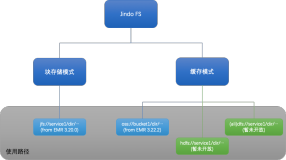
JindoFS概述:云原生的大数据计算存储分离方案
JindoFS 是一套新的云原生的数据湖解决方案。在 JindoFS 之前,云上客户主要使用 HDFS 和 OSS/S3 作为大数据存储。HDFS 是 Hadoop 原生的存储系统,10 年来,HDFS 已经成为大数据生态的存储标准,但是我们也可以看到 HDFS 虽然不断优化,但是 JVM 的瓶颈也始终无法突破。
玩转阿里云EMR三部曲-中级篇 集成自有服务
利用EMR引导操作可以使用自定义脚本安装任意自有服务和环境,隔离计算和生产资源,并在极致成本控制下最大化并发和可扩展性。完整的自定义设计可以满足任意自有服务构建的集成需要。
3天撸完一个团队半年的项目,单客户数据动辄几百万的行业也玩云?
自97年成立至今已接近20年,在前十六七年 明源云主要跑在传统ERP软件轨道上,4年前世界变了,云计算&移动互联网来了,两个最大的行业变量,如果不做出改变就可能被颠覆。因此,明源云决定开辟新战场,用互联网的方式来做地产行业。
10月18日,德国法兰克福,阿里云MaxCompute2.0,全面布局AI人工智能
在2017年杭州云栖大会上,阿里云宣布大数据计算服务MaxCompute将于10月18日在德国法兰克福正式开服。通过MaxCompute2.0全新一代的人工智能系统,阿里云将携手更多欧洲本地合作伙伴建立科技生态,驱动当地云计算和大数据的发展,将中国先进的云计算推广至海外,在人工智能、深度学习等领域实现突破创新。
标签分类理论
最近在做DMP,负责设计一套标签管理系统。在对现有标签进行整理的过程中,整理出了这套东西。 0. 标签的定义:标签分类学(Taxonomy) 对于标签(tag),很难列出一个公认的定义,指明这个概念的种差与属概念。所以为了把握这个概念,就需要采取定义另一种办法:分类与枚举。 我们要解决的第一个
Logstash + DataHub + MaxCompute/StreamCompute 进行实时数据分析
Logstash是一款开源日志收集处理框架,logstash-output-datahub插件,实现将数据导入DataHub的功能。通过简单的配置即可完成数据采集和向DataHub的传输,结合MaxCompute/StreamCompute可以轻松构建流式数据从采集到分析的一站式解决方案。
数据库工程师快速上手MaxCompute进行ETL
案例说明 本案例主要是介绍如何通过数加MaxCompute+大数据开发套件两个产品实现简单的网站数据统计分析。 适用人群 MaxCompute初学者,特别是无大数据开发基础但有数据库使用基础。 案例侧重 数据库工程师快速上手MaxCompute进行大数据开发,简单了解在MaxCompute做大数据ETL过程,同时了解一些MaxCompute SQL和常用数据库SQL的基本区别。
日交易笔百万级,Ping++的大数据平台架构
当前日交易笔数为百万级,目前已经积累了海量交易数据。如何在经过客户授权的情况下利用数据为客户赋能,并带来额外附加价值,从而提高客户黏性,Ping++亟需搭建可靠、稳定的大数据平台。
Apache Flink 的迁移之路,2 年处理效果提升 5 倍
在 2017 年上半年以前,TalkingData 的 App Analytics 和 Game Analytics 两个产品,流式框架使用的是自研的 td-etl-framework。该框架降低了开发流式任务的复杂度,对于不同的任务只需要实现一个 changer 链即可,并且支持水平扩展,性能尚可,曾经可以满足业务需求。
阿里大航杯AI电力大赛比赛分享及数加平台,机器学习pai使用经验
本文主要以阿里云大航杯“智造扬中”电力AI大赛 数据为背景,讲述博主自己的比赛经历以及数加平台和机器学习pai的使用经验
从声学模型算法角度总结 2016 年语音识别的重大进步
免费开通大数据服务:https://www.aliyun.com/product/odps 在过去的一年中,语音识别再次取得非常大的突破。IBM、微软等多家机构相继推出了自己的 Deep CNN 模型,提升了语音识别的准确率;Residual/Highway 网络的提出使我们可以把神经网络训练的更加深。
你的大数据安全么?“Hadoop集群遭遇勒索软件攻击 ”
近期,各大安全组织检测到勒索软件正在攻击Hadoop集群,再次表明黑客正在尝试从“大数据”中获利,你的数据资产有没有被黑客get了? ◇◆◇◆◇ 勒索软件攻击Hadoop事件综述 最近,部分黑客组织针对几款特定产品展开了勒索攻击。
如何使用Tunnel SDK上传/下载MaxCompute复杂类型数据
基于Tunnel SDK如何上传复杂类型数据到MaxCompute?首先介绍一下MaxCompute复杂数据类型: 复杂数据类型 MaxCompute采用基于ODPS2.0的SQL引擎,丰富了对复杂数据类型类型的支持。
【教程】5分钟在PAI算法市场发布自定义算法
概述 在人工智能领域存在这样的现象,很多用户有人工智能的需求,但是没有相关的技术能力。另外有一些人工智能专家空有一身武艺,但是找不到需求方。这意味着在需求和技术之间需要一种连接作为纽带。 今天PAI正式对外发布了“AI市场”以及“PAI自定义算法”两大功能,可以帮助用户5分钟将线下的spark算法或是pyspark算法发布成算法组件,并且支持组件发布到AI市场供更多用户使用。
SQL优化器原理 - 查询优化器综述
本文主要是对数据库查询优化器的一个综述,包括查询优化器分类、查询优化器执行过程和CBO框架Calcite。
Python实现MaxCompute UDF/UDAF/UDTF
参数与返回值类型 参数与返回值通过如下方式指定: @odps.udf.annotate(signature) Python UDF目前支持ODPS SQL数据类型有:bigint, string, double, boolean和datetime。
小硅片与大数据的结合 ——协鑫光伏的新制造之路
协鑫光伏坐落在环境优美的苏州工业园区,是全球领先的光伏材料制造商,硅片产品占国内流通硅片的70%,处于国内同行业龙头地位。本文将向读者介绍大数据是如何助力晶片制造,以减少成本,提高效率。
MaxCompute计算长尾问题
长尾问题是分布式计算里最常见的问题之一,也是典型的疑难杂症。究其原因,是因为数据分布不均,导致各个节点的工作量不同,整个任务就需要等最慢的节点完成才能完成。本文希望就平时工作中遇到的一些典型的长尾问题的场景及其解法做一些分享。
基于MaxCompute构建企业用户画像(用户标签的制作)
在数据化营销时代,数据的价值越发显得更为珍贵。那如何让自己的数据发挥价值,也就是说如何让公司沉睡的数据能够驱动业务发展给公司带来商业价值?在营销里面我们都谈精准营销,谈用户画像,那用户画像到底如何构建,用户的标签如何开发?本示例给与最简单的demo,那个大家清楚认识基于MaxCompute如何构建企业用户标签。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
