 阿里云E-MapReduce团队
阿里云E-MapReduce团队
阿里云E-MapReduce团队_个人页
阿里云E-MapReduce团队



文章
217
问答
14
视频
0
个人介绍
暂无个人介绍
擅长的技术
- Java
- Python
- 前端开发
- Linux
- 数据库

暂无更多信息
2021年12月
-
12.22 19:19:57
 发表了文章
2021-12-22 19:19:57
发表了文章
2021-12-22 19:19:57
Lakehouse 架构解析与云上实践
本文整理自 DataFunCon 2021大会上,阿里云数据湖构建云产品研发陈鑫伟的分享,主要介绍了 Lakehouse 的架构解析与云上实践。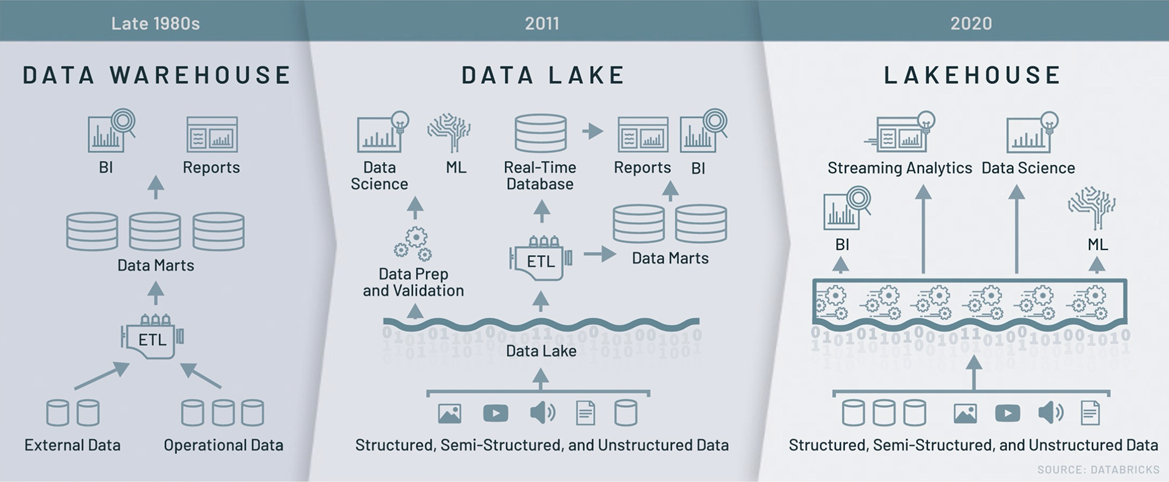
-
12.17 17:23:45发表了文章
2021-12-17 17:23:45
ClickHouse Keeper 源码解析
ClickHouse 社区在21.8版本中引入了 ClickHouse Keeper。ClickHouse Keeper 是完全兼容 Zookeeper 协议的分布式协调服务。本文对开源版本 ClickHouse v21.8.10.19-lts 源码进行了解析。
-
12.17 14:53:00发表了文章
2021-12-17 14:53:00
【月刊】E-MapReduce 2021-11 产品月刊
11月 E-MapReduce 产品月刊为您带来 1.重要功能 2.版本发布 3.产品文档更新 4.十一月精选文章推荐。欢迎持续关注更多精彩内容!
-
12.16 17:35:34发表了文章
2021-12-16 17:35:34
【月刊】E-MapReduce 2021-11 产品月刊
11月 E-MapReduce 产品月刊为您带来 1.重要功能 2.版本发布 3.产品文档更新 4.十一月精选文章推荐 。欢迎持续关注更多精彩内容!
-
12.14 11:49:00发表了文章
2021-12-14 11:49:00
【ClickHouse 技术系列】- ClickHouse 中的嵌套数据结构
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB级的数据规模,简单的架构,被国内外公司广泛采用。本系列技术文章,将详细展开介绍 ClickHouse。
-
12.14 11:01:00发表了文章
2021-12-14 11:01:00
【ClickHouse 技术系列】- ClickHouse 聚合函数和聚合状态
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB级的数据规模,简单的架构,被国内外公司广泛采用。本系列技术文章,将详细展开介绍 ClickHouse。
-
12.09 19:13:04发表了文章
2021-12-09 19:13:04
【ClickHouse 技术系列】- 在 ClickHouse 物化视图中使用 Join
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB级的数据规模,简单的架构,被国内外公司广泛采用。本系列技术文章,将详细展开介绍 ClickHouse。
-
12.08 11:49:58发表了文章
2021-12-08 11:49:58
【ClickHouse 技术系列】- 使用新的 TTL move,将数据存储在合适的地方
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB级的数据规模,简单的架构,被国内外公司广泛采用。本系列技术文章,将详细展开介绍 ClickHouse。
-
12.06 19:19:30发表了文章
2021-12-06 19:19:30
【ClickHouse 技术系列】- 在 ClickHouse 中处理实时更新
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB级的数据规模,简单的架构,被国内外公司广泛采用。本系列技术文章,将详细展开介绍 ClickHouse。
2021年11月
-
11.24 20:05:24发表了文章
2021-11-24 20:05:24
基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现
阿里云 EMR OLAP 与 Flink 团队深度合作,支持了 Flink 到 ClickHouse 的 Exactly-Once写入来保证整个实时数仓数据的准确性。本文介绍了基于 EMR OLAP 的开源实时数仓解决方案。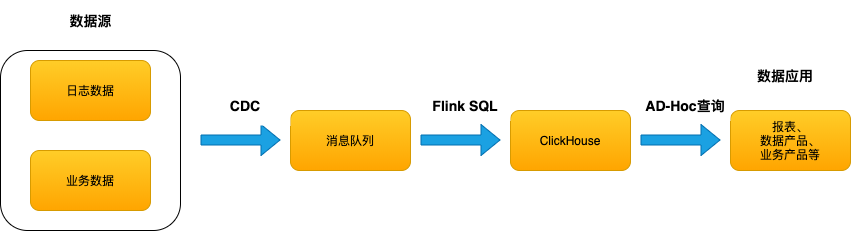
-
11.18 15:09:11发表了文章
2021-11-18 15:09:11
如何构建云原生的开源大数据平台 | 产品新功能速递
云原生开源大数据的新产品和新功能「速递」:企业数据云 Cloudera CDP 正式商业化,0元免费测试火热申请中;Elasticsearch、实时计算Flink版、EMR、DLF重磅功能升级。更多优惠等您领取。
-
11.18 11:57:38发表了文章
2021-11-18 11:57:38
企业级数据湖最佳实践
2021云栖大会云原生企业级数据湖专场,阿里云智能高级解决方案架构师周皓为我们带来《企业级数据湖最佳实践》的分享。
-
11.11 19:51:28发表了文章
2021-11-11 19:51:28
【月刊】E-MapReduce 2021-10 产品月刊
10月 E-MapReduce 产品月刊为您带来 1.相关活动:云栖大会、开源主题直播回顾 2.版本发布 3.产品文档更新 4.十月精选文章推荐 。欢迎持续关注更多精彩内容!
-
11.10 19:45:41发表了文章
2021-11-10 19:45:41
如何构建云原生的开源大数据平台 | 微淼基于阿里云大数据生态的应用实践
随着开源技术与云原生的高度融合,阿里云开源大数据平台在功能性、易用性、安全性上积累了丰富的实践经验,已成功服务数千家企业,助力其聚焦自身核心业务优势,缩短开发周期、简化运维难度,拓展更多业务创新。10月29日,阿里云发布“如何构建云原生的开源大数据平台”解决方案,邀请到了来自阿里云、微淼、Inmobi的技术专家为大家现身说法,呈现上云实践。
-
11.09 18:08:18发表了文章
2021-11-09 18:08:18
如何构建云原生的开源大数据平台 | InMobi 基于阿里云开源大数据服务的最佳实践
随着开源技术与云原生的高度融合,阿里云开源大数据平台在功能性、易用性、安全性上积累了丰富的实践经验,已成功服务数千家企业,助力其聚焦自身核心业务优势,缩短开发周期、简化运维难度,拓展更多业务创新。10月29日,阿里云发布“如何构建云原生的开源大数据平台”解决方案,邀请到了来自阿里云、微淼、Inmobi的技术专家为大家现身说法,呈现上云实践。
-
11.05 19:27:50发表了文章
2021-11-05 19:27:50
如何构建云原生的开源大数据平台 | 云原生开源大数据应用实战
随着开源技术与云原生的高度融合,阿里云开源大数据平台在功能性、易用性、安全性上积累了丰富的实践经验,已成功服务数千家企业,助力其聚焦自身核心业务优势,缩短开发周期、简化运维难度,拓展更多业务创新。10月29日,阿里云发布“如何构建云原生的开源大数据平台”解决方案,邀请到了来自阿里云、微淼、Inmobi的技术专家为大家现身说法,呈现上云实践。
-
11.05 17:59:44发表了文章
2021-11-05 17:59:44
百草味基于“ EMR+Databricks+DLF ”构建云上数据湖的最佳实践
本文介绍了百草味大数据平台从 IDC 自建 Hadoop 到阿里云数据湖架构的迁移方案和落地过程。重点从 IDC 自建集群的痛点分析,云上大数据方案的选型以及核心模块的建设过程几个方面做了详细的介绍,希望给想了解和实践数据湖架构的企业和朋友一个参考。
-
11.02 18:56:53发表了文章
2021-11-02 18:56:53
数据湖构建与计算
2021云栖大会云原生企业级数据湖专场,阿里云智能高级产品专家李冰为我们带来《数据湖构建与计算》的分享。本文主要从数据的入湖和管理、引擎的选择展开介绍了数据湖方案降本增效的特性。
2021年10月
-
10.28 18:11:01发表了文章
2021-10-28 18:11:01
云湖共生-释放企业数据价值
摘要:2021云栖大会云原生企业级数据湖专场,阿里云智能资深技术专家、对象存储 OSS 负责人罗庆超为我们带来《云湖共生-释放企业数据价值》的分享。本文主要从数据湖存储演进之路、数据湖存储3.0 进化亮点等方面分享了云湖共生带来的企业价值。
-
10.27 19:12:41发表了文章
2021-10-27 19:12:41
贾扬清:云原生让数据湖加速迈入3.0时代
摘要:2021云栖大会云原生企业级数据湖专场,阿里云智能高级研究员贾扬清为我们带来《云原生让数据湖加速迈入3.0时代》的分享。
-
10.13 19:09:16发表了文章
2021-10-13 19:09:16
2021云栖大会 — 大数据&AI 线上参会指南
一年一度的数字科技盛会—— 2021云栖大会将于10月19日-22日在杭州云栖小镇举办。阿里云大数据&AI邀您线上参会,领略数字新篇章。
-
10.12 19:25:50发表了文章
2021-10-12 19:25:50
“数据智能实战营-北京站”成功举办 | 一场高质量的“大数据&AI体验课”(附PPT下载)
2021年3月24日下午,“数据智能实战营-北京站”活动在北京阿里中心成功举办,到场客户人数120+。本文收录了现场集锦,11位专家演讲合辑,精彩内容一次发送!
-
10.11 18:13:56发表了文章
2021-10-11 18:13:56
【月刊】E-MapReduce 2021-09 产品月刊
9月 E-MapReduce 产品月刊为您带来 1.相关活动:E-MapReduce 海量日志分析 实操体验 ;2.产品功能更新:G-SCD的具体解决方案及如何通过G-SCD处理维度的数据介绍;3.最佳实践:SparkSQL自适应执行 4.新增视频专区 。欢迎持续关注更多精彩内容!
-
10.09 18:43:50发表了文章
2021-10-09 18:43:50
阿里云大数据&AI实战宝典2021
集合了阿里云大数据和AI的实战资料,包含数据仓库、数据湖、湖仓一体、全链路数据治理,以及机器学习PAI内容风控、端侧超分解决方案、在线零售增长解决方案等,助力企业数智基建,加速企业释放数据价值。
2021年09月
-
09.10 12:20:38发表了文章
2021-09-10 12:20:38
【月刊】E-MapReduce 2021-08 产品月刊
8月 E-MapReduce 产品月刊为您带来 1.相关活动:大数据开发平台用户调研问卷 ;2.产品功能更新:EMR ClickHouse 独立集群公测发布 ;3.最佳实践 E-MapReduce 本地盘实例大规模数据集测试 。欢迎持续关注更多精彩内容!
-
09.08 18:26:22发表了文章
2021-09-08 18:26:22
阿里云 E-MapReduce ClickHouse 操作指南 05 期 — 常见问题
阿里云 E-MapReduce(简称 EMR )是运行在阿里云平台上的一种大数据处理的系统解决方案。ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
-
09.07 18:48:02发表了文章
2021-09-07 18:48:02
阿里云 E-MapReduce ClickHouse 操作指南 04 期 — 数据导入
阿里云 E-MapReduce(简称 EMR )是运行在阿里云平台上的一种大数据处理的系统解决方案。ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
-
09.06 17:43:47发表了文章
2021-09-06 17:43:47
阿里云 E-MapReduce ClickHouse 操作指南 03 期 — ClickHouse 运维
阿里云 E-MapReduce(简称 EMR )是运行在阿里云平台上的一种大数据处理的系统解决方案。ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
-
09.03 17:52:30发表了文章
2021-09-03 17:52:30
阿里云 E-MapReduce ClickHouse 操作指南 02期 — 快速入门
阿里云 E-MapReduce(简称EMR)是运行在阿里云平台上的一种大数据处理的系统解决方案。ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
-
09.02 16:42:41发表了文章
2021-09-02 16:42:41
阿里云 E-MapReduce ClickHouse 操作指南 01期 — ClickHouse 概述
阿里云 E-MapReduce(简称EMR)是运行在阿里云平台上的一种大数据处理的系统解决方案。ClickHouse 作为开源的列式存储数据库,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。而阿里云 EMR ClickHouse 则提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。
-
09.01 17:03:14发表了文章
2021-09-01 17:03:14
2021大数据开发平台用户调研问卷,填写问卷有机会领取EMR定制礼品!
为了给您提供更加优质的大数据开发平台服务,同时帮助我们更好地优化和提升大数据开发平台,现进行阿里云 EMR 大数据开发平台有奖调研。参与调研,就有机会领取阿里云 EMR 定制礼品,EMR 定制背包、太阳伞、定制T恤~~我们期待您最真实的反馈!感谢您对阿里云 EMR 产品的大力支持!!
2021年08月
-
08.25 18:51:09发表了文章
2021-08-25 18:51:09
EMR on ACK 全新发布,助力企业高效构建大数据平台
阿里云 EMR on ACK 为用户提供了全新的构建大数据平台的方式,用户可以将开源大数据服务部署在阿里云容器服务(ACK)上。利用 ACK 在服务部署和对高性能可伸缩的容器应用管理的能力优势,用户只需要专注在大数据作业本身。用户可以便捷地将 Spark、Presto、Flink 作业执行在 ACK 集群上,100%兼容开源,性能优于开源。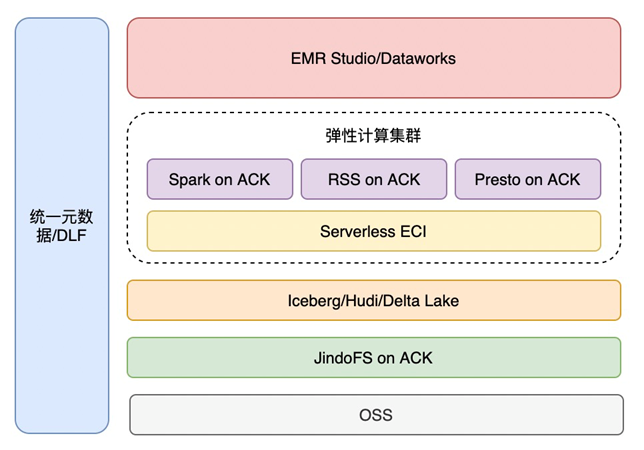
-
08.23 18:49:21发表了文章
2021-08-23 18:49:21
如何快速搭建云原生企业级数据湖架构及实践分享
众所周知,数据湖技术在大数据领域炙手可热,随着在云上的广泛部署和应用,其业务价值逐渐获得业界共识。如何快搭建数据湖架构被越来越多的企业探讨。本文主要分享快速搭建云原生企业级数据湖架构及实践分享。
-
08.18 20:41:24发表了文章
2021-08-18 20:41:24
基于英特尔® 优化分析包(OAP)的 Spark 性能优化方案
Spark SQL 作为 Spark 用来处理结构化数据的一个基本模块,已经成为多数企业构建大数据应用的重要选择。但是,在大规模连接(Join)、聚合(Aggregate)等工作负载下,Spark 性能会面临稳定性和性能方面的挑战。
-
08.18 15:51:34发表了文章
2021-08-18 15:51:34
26万奖金 | 第一届 E-MapReduce 极客挑战赛 诚邀英才前来挑战!
日前,“ 第一届 E-MapReduce 极客挑战赛 ”在阿里云天池官网正式开赛。据悉,本次大赛由阿里云、英特尔联合举办,聚焦 SparkSQL 执行效率,探索 TPC-DS 测试集最优性能,助力海量数据轻松上云,全程将有资深技术专家提供技术指导。
-
08.12 11:37:03发表了文章
2021-08-12 11:37:03
【月刊】E-MapReduce 2021-06/07 产品月刊
6-7月 E-MapReduce 上线EMR-3.36.x版本、EMR-5.2.x版本,同步对SmartData 3.6.x版本进行更新;最佳实践案例发表《云原生数据湖构建、分析与开发治理最佳实践及案例分享》、《StarLake:汇量科技云原生数据湖的探索和实践》、《DLF +DDI 一站式数据湖构建与分析最佳实践》;首届 E-MapReduce 极客挑战赛正式启动。欢迎持续关注更多精彩内容!
-
08.10 16:29:14发表了文章
2021-08-10 16:29:14
赛题解析 | E-MapReduce 极客挑战赛
首届 E-MapReduce 极客挑战赛已开启,奖金高达26万,欢迎大家踊跃报名!本文主要讲解自测工具的使用以及代码的提交和评测,帮助选手更高效的解题。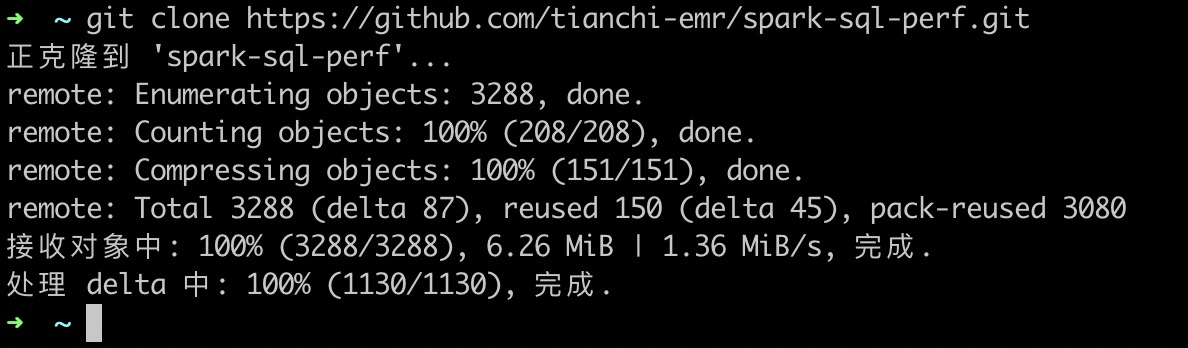
-
08.05 17:47:15发表了文章
2021-08-05 17:47:15
《 Delta Lake 数据湖专题系列5讲》文章回顾
《Delta Lake 数据湖专题系列5讲》由阿里云 DDI 团队翻译整理自大数据技术公司 Databricks 针对数据湖 Delta Lake 系列技术文章。阅读完此系列文章可以帮助您达到入门级,对数据湖 Lakehouse 有整体上的认识和应用,掌握理论知识体系。
-
08.04 12:15:42发表了文章
2021-08-04 12:15:42
E-MapReduce 数据湖 Meetup 8.7上海站延期
由于疫情防控的原因,原定 8 月 7 日的 E-MapReduce 数据湖 Meetup 延期。
-
08.02 16:59:53发表了文章
2021-08-02 16:59:53
DLF +DDI 一站式数据湖构建与分析最佳实践
本文由阿里云数据湖构建 DLF 团队和 Databricks 数据洞察团队联合撰写,旨在帮助您更深入地了解阿里云数据湖构建(DLF)+Databricks 数据洞察(DDI)构建一站式云上数据入湖。
2021年07月
-
07.29 17:14:37发表了文章
2021-07-29 17:14:37
数据湖实操讲解【 JindoTable 计算加速】第二十二讲:对 Hive 数仓表进行高效小文件合并
数据湖 JindoFS+OSS 实操干货 36讲 每周二16点准时直播! 扫文章底部二维码入钉群,线上准时观看~ Github链接: https://github.com/aliyun/alibabacloud-jindofs
-
07.28 19:35:53发表了文章
2021-07-28 19:35:53
数据湖实操讲解【 JindoTable 计算加速】第二十一讲:分层更高效,对 Hive 数仓进行热度/冷度统计
数据湖 JindoFS+OSS 实操干货 36讲 每周二16点准时直播! 扫文章底部二维码入钉群,线上准时观看~ Github链接: https://github.com/aliyun/alibabacloud-jindofs
-
07.27 19:31:26发表了文章
2021-07-27 19:31:26
高能预警! E-MapReduce 数据湖 Meetup · 上海站重磅来袭
8月7日,阿里云 E-MapReduce 数据湖首场 Meetup 重磅上线。来自 Intel、Cloudera、阿里巴巴的七位技术专家齐聚上海,为你带来超多数据湖干货和行业新动态~
-
07.26 19:35:30发表了文章
2021-07-26 19:35:30
首届!E-MapReduce 极客挑战赛强势来袭,重磅奖项等你拿,快来组队报名啦
首届 E-MapReduce 极客挑战赛发布,聚焦.SparkSQL执行效率。结合阿里云 EMR和英特尔® 傲腾™ 数据中心级持久内存(以及Intel OAP软件包),优化软件系统和利用硬件的特征,追求TPC-DS测试集的最优性能。帮助参赛队伍实现Spark 代码优化和参数调优,完成性能的优化挑战。
-
07.23 15:34:08发表了文章
2021-07-23 15:34:08
Flink on Zeppelin 流计算处理最佳实践
欢迎钉钉扫描文章底部二维码进入 EMR Studio 用户交流群 直接和讲师交流讨论~ 点击以下链接直接观看直播回放:https://developer.aliyun.com/live/247106
-
07.22 18:48:48发表了文章
2021-07-22 18:48:48
数据湖实操讲解【 JindoTable 计算加速】第二十讲:Spark 对 OSS 上的 ORC 数据进行查询加速
数据湖 JindoFS+OSS 实操干货 36讲 每周二16点准时直播! 扫文章底部二维码入钉群,线上准时观看~ Github链接: https://github.com/aliyun/alibabacloud-jindofs
-
07.21 18:46:43发表了文章
2021-07-21 18:46:43
数据湖实操讲解【 JindoTable 计算加速】第十九讲:Spark 对 OSS 上的 Parquet 数据进行查询加速
数据湖 JindoFS+OSS 实操干货 36讲 每周二16点准时直播! 扫文章底部二维码入钉群,线上准时观看~ Github链接: https://github.com/aliyun/alibabacloud-jindofs
-
发表了文章
2021-12-22
Lakehouse 架构解析与云上实践
-
发表了文章
2021-12-17
ClickHouse Keeper 源码解析
-
发表了文章
2021-12-17
【月刊】E-MapReduce 2021-11 产品月刊
-
发表了文章
2021-12-16
【月刊】E-MapReduce 2021-11 产品月刊
-
发表了文章
2021-12-14
【ClickHouse 技术系列】- ClickHouse 中的嵌套数据结构
-
发表了文章
2021-12-14
【ClickHouse 技术系列】- ClickHouse 聚合函数和聚合状态
-
发表了文章
2021-12-09
【ClickHouse 技术系列】- 在 ClickHouse 物化视图中使用 Join
-
发表了文章
2021-12-08
【ClickHouse 技术系列】- 使用新的 TTL move,将数据存储在合适的地方
-
发表了文章
2021-12-06
【ClickHouse 技术系列】- 在 ClickHouse 中处理实时更新
-
发表了文章
2021-11-24
基于 EMR OLAP 的开源实时数仓解决方案之 ClickHouse 事务实现
-
发表了文章
2021-11-18
如何构建云原生的开源大数据平台 | 产品新功能速递
-
发表了文章
2021-11-18
企业级数据湖最佳实践
-
发表了文章
2021-11-11
【月刊】E-MapReduce 2021-10 产品月刊
-
发表了文章
2021-11-10
如何构建云原生的开源大数据平台 | 微淼基于阿里云大数据生态的应用实践
-
发表了文章
2021-11-09
如何构建云原生的开源大数据平台 | InMobi 基于阿里云开源大数据服务的最佳实践
-
发表了文章
2021-11-05
如何构建云原生的开源大数据平台 | 云原生开源大数据应用实战
-
发表了文章
2021-11-05
百草味基于“ EMR+Databricks+DLF ”构建云上数据湖的最佳实践
-
发表了文章
2021-11-02
数据湖构建与计算
-
发表了文章
2021-10-28
云湖共生-释放企业数据价值
-
发表了文章
2021-10-27
贾扬清:云原生让数据湖加速迈入3.0时代
滑动查看更多
-
 回答了问题
2019-07-31
回答了问题
2019-07-31
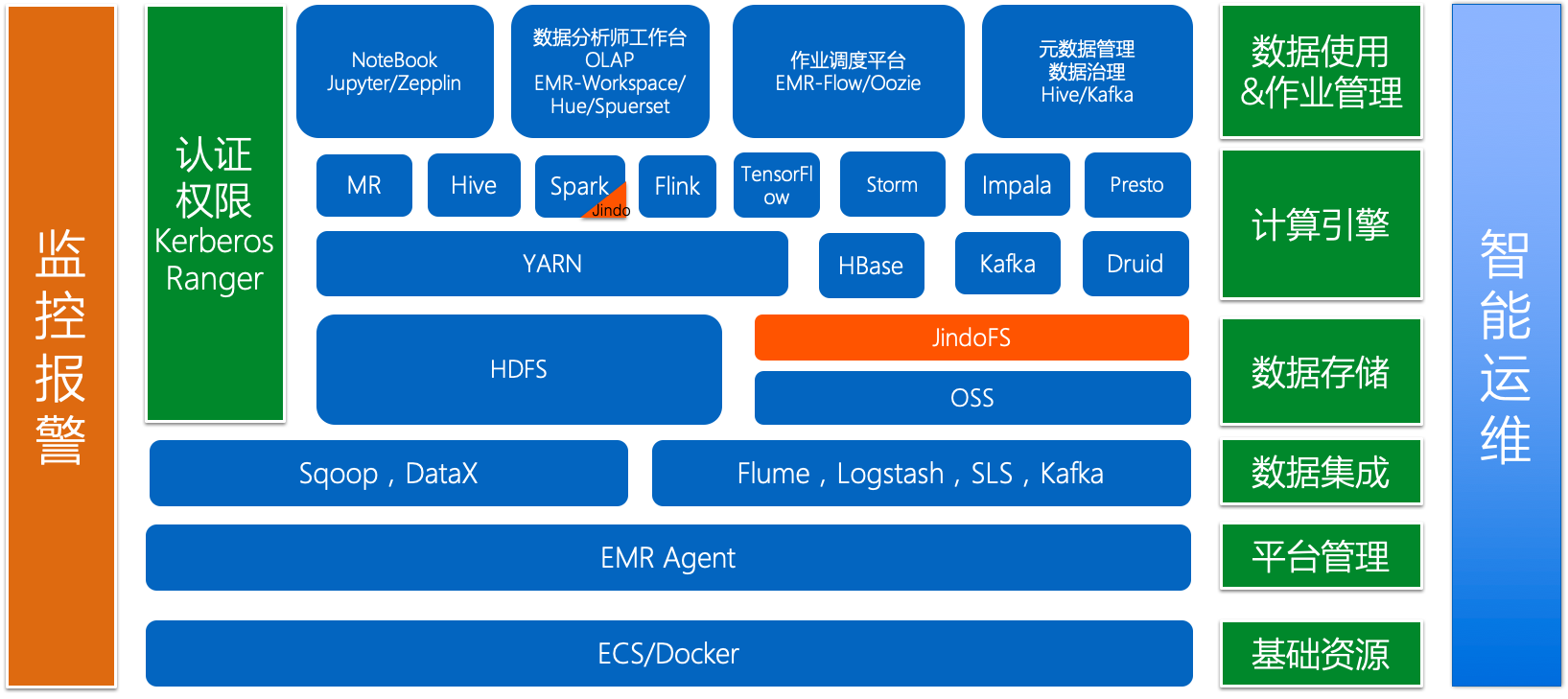
阿里的EMR里推出了JindoFS, 也简称 jfs, 有用过的吗
Jindo 是阿里云 EMR 的技术代号,寓意在云上会玩的弹性计算,JindoFS 是这个技术体系下的存储解决方案。
阿里云 HDFS 是一款云存储产品,跟 OSS 是同一级别的。JindoFS 是 EMR 产品内部的一个统一存储解决方案,对接各种存储系统。
JindoFS 是个多模系统,缓存这种模式是支持的。
JindoFS和smartFS是同类功能。
JindoFS 跟 Alluxio可能有些类似。不过我们希望更轻量,对计算和业务更透明。毕竟 Alluxio 要满足业界的各种存储系统,但是阿里云 EMR 不需要考虑那么多。
 赞0 踩0 评论0
赞0 踩0 评论0 -
 提交了问题
2019-07-31
提交了问题
2019-07-31
阿里的EMR里推出了JindoFS, 也简称 jfs, 有用过的吗
-
回答了问题
2019-07-17
读取emr高安全集群的hbase数据
- 公网环境 怎么理解
- 走公网验证?
为何不走vpn/nat方式
1、本地环境和EMR交互 不在一个vpc下
EMR在线上环境 vpn没有打通线上环境结果集有多大?,运算倒是可以这样搞,如果是频繁的业务交互 不建议这样,还不如 本地集群 想办法 利用 oss
赞0 踩0 评论0 -
提交了问题
2019-05-29
读取emr高安全集群的hbase数据
-
提交了问题
2019-04-26
Spark Streaming 作业运行一段时间后无故结束
-
提交了问题
2019-04-26
多个 ConsumerID 消费同一个 Topic 时出现 TPS 不一致问题
-
提交了问题
2019-04-26
第一次使用执行计划时没有安全组可选
-
提交了问题
2019-04-26
如何查看作业日志
-
提交了问题
2019-04-26
作业和执行计划的区别
-
回答了问题
2019-07-17
E-MapReduce与ODPS的区别
E-MapReduce 是构建于阿里云 ECS 弹性虚拟机之上,利用开源大数据生态系统,包括 Hadoop、Spark、HBase,为用户提供集群、作业、数据等管理的一站式大数据处理分析服务。
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
赞0 踩2 评论0 -
回答了问题
2019-07-17
使用emapreduce集群,怎么访问公网呢?包括计费等能详细解析下吗?
1.E-MapReduce目前默认会给集群的master节点开通公网IP,classic网络下按照流量收费,vpc网络下使用的是EIP,eip会收取使用费和流量费用,使用费按照小时计费(每个region不一样,看了一下大概0.05元/小时),但是如果绑定了ecs,那么不会收取使用费,只收取流量费
2.用户自己购买的ECS(不是从E-MapReduce购买),如果想访问E-MapReduce集群:
a) classic网络的ECS -> classic网络的E-MapReduce集群,可以给E-MapReduce集群设置安全组,通过内网访问,不收取流量费用
b) classic网络的ECS -> vpc网络的E-MapReduce集群,只能通过公网访问E-MapReduce集群
c) vpc网络的ECS -> classic网络的E-MapReduce集群,只能通过公网访问E-MapReduce集群
d) vpc网络的ECS -> vpc网络的E-MapReduce集群,通过阿里云的高速通道产品进行连接访问3.线下机器访问E-MapReduce集群,只能通过高速通道,而且E-MapReduce集群必须是VPC的
4.E-MapReduce集群访问公网
master节点默认有公网IP,可以直接访问公网,slave节点可以自己挂一个EIP,或者通过自己搭建一个NAT网关(详见https://help.aliyun.com/document_detail/27738.html)赞0 踩0 评论0 -
回答了问题
2019-07-17
我刚才提了个问题,postgresql的,说有敏感词汇,能否审核通过。
应该很快就能通过
赞0 踩0 评论0 -
提交了问题
2016-05-26
如何导出HBase的表的数据
-
回答了问题
2019-07-17
使用E-MapReduce,spark中读取oss文件
看了你的日志,感觉是你的endpoint写错了把,你再确认一下。
赞0 踩0 评论0
滑动查看更多
暂无更多信息