









OpenCode入门使用教程
本教程介绍如何通过安装OpenCode并配置Canopy Wave API来使用开源模型。首先全局安装OpenCode,然后设置API密钥并创建配置文件,最后在控制台中连接模型并开始交互。
Microsoft Activation Scripts v3.6 (MAS)激活工具安装教程!中文汉化版(激活工具)
Microsoft Activation Scripts v3.6(MAS)是一款开源、轻量级的批量激活工具,支持HWID、KMS38、TSforge等多种方式,可离线永久激活Win7至Win11及Office全系列。兼容旧系统如Vista,操作简单,无误报风险。
Miniconda 安装与环境配置全流程图解(2025 最新版)
Miniconda 可以看作是 Anaconda 的“轻装版”,只自带 conda 包管理器与基础的 Python 运行时。它体积小、部署速度快,特别适合按需创建与管理虚拟环境的用户。与 Anaconda 相比,Miniconda 不会预先安装一大堆科学计算库,你可以根据项目需求再单独选择、安装需要的包,因此整体更轻巧、更灵活。 本文将手把手演示在 Windows 下安装 Miniconda 的全过程:从下载安装器、完成向导配置、设置环境变量,到最后的基础验证与简单示例,帮助你迅速把 Miniconda 用起来。

英伟达新一代GPU架构(50系列显卡)PyTorch兼容性解决方案
本文记录了在RTX 5070 Ti上运行PyTorch时遇到的CUDA兼容性问题,分析其根源为预编译二进制文件不支持sm_120架构,并提出解决方案:使用PyTorch Nightly版本、更新CUDA工具包至12.8。通过清理环境并安装支持新架构的组件,成功解决兼容性问题。文章总结了深度学习环境中硬件与框架兼容性的关键策略,强调Nightly构建版本和环境一致性的重要性,为开发者提供参考。
Multisim14.0中文下载安装步骤教程
Multisim14.0是由美国NI公司开发的EDA工具,适用于电路设计与仿真。本文提供详细中文安装步骤:下载安装包后解压,运行安装程序并设置路径,填写用户信息,选择安装位置,接受协议完成安装。随后安装NILicense激活器及中文语言包,最终实现软件汉化与正常运行。附带网盘下载链接,方便国内用户获取资源。

阿里云开发者分享VMware17 Pro保姆级安装秘籍,详细步骤助你轻松搞定安装!
这是一篇超详细的VMware 17 Pro虚拟机下载与安装教程。VMware 17 Pro支持多操作系统模拟运行,适合开发、测试及教育使用。文章涵盖从下载到安装的全流程,包括解压安装包、接受协议、配置安装路径等步骤,并提供虚拟机优化(如安装VMware Tools、配置快照和共享文件夹)及使用指南。同时,针对常见问题如虚拟化未启用或软件阻止启动,提供了具体解决方案,帮助用户顺利部署和使用虚拟机环境。

普通电脑也能跑AI:10个8GB内存的小型本地LLM模型推荐
随着模型量化技术的发展,大语言模型(LLM)如今可在低配置设备上高效运行。本文介绍本地部署LLM的核心技术、主流工具及十大轻量级模型,探讨如何在8GB内存环境下实现高性能AI推理,涵盖数据隐私、成本控制与部署灵活性等优势。

Egde卸载教程!edge浏览器卸载工具!EdgeRemover v18.38新版本,单文件便携版!
Edge浏览器虽功能强大,却常因无法彻底卸载让用户体验困扰。本文推荐一款专清工具——Edge Remover,支持一键移除Edge及WebView2运行时,两种模式灵活选择,操作简单,无需专业技能,彻底清理不留残留,释放C盘空间,提升系统纯净度,是Windows用户必备的卸载利器。
AI学习全景图:从大模型到RAG,从工具到变现,一条从0到1的路线
告别碎片化学习!本文系统梳理AI知识五层结构:从基础认知到商业变现,提供完整学习路径与优质资源链接。帮你构建AI知识网络,实现从工具使用到能力落地的跃迁。
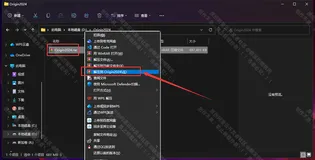
Origin2024 汉化安装专业解析|企业级部署教程+批量激活解决方案
Origin是一款由OriginLab开发的科学绘图与数据分析软件,支持Windows系统,提供丰富的2D/3D图形模板和强大的数据分析功能,如统计、信号处理、图像处理等。本文详细介绍Origin2024的下载与安装步骤,包括解压文件、运行安装程序、输入序列号、安装路径设置及破解方法,帮助用户快速完成软件安装与激活。

在AMD GPU上部署AI大模型:从ROCm环境搭建到Ollama本地推理实战指南
本文详细介绍了在AMD硬件上构建大型语言模型(LLM)推理环境的全流程。以RX 7900XT为例,通过配置ROCm平台、部署Ollama及Open WebUI,实现高效本地化AI推理。尽管面临技术挑战,但凭借高性价比(如700欧元的RX 7900XT性能接近2200欧元的RTX 5090),AMD方案成为经济实用的选择。测试显示,不同规模模型的推理速度从9到74 tokens/秒不等,满足交互需求。随着ROCm不断完善,AMD生态将推动AI硬件多元化发展,为个人与小型组织提供低成本、低依赖的AI实践路径。

开发者急盼!Cisco Packet Tracer超详细下载安装教程,附中文版插件使用步骤!
Cisco Packet Tracer是思科推出的专业路由器模拟器,适用于学习IOS配置、故障排查及网络拓扑构建。支持多种协议(STP、OSPF等),含无线功能与安全设备。本文提供下载链接、安装教程及高级功能介绍,如复杂网络仿真、可视化调试、自动化脚本和行业场景模拟等,助你高效学习网络技术并启用中文语言包。

DINOv3上手指南:改变视觉模型使用方式,一个模型搞定分割、检测、深度估计
DINOv3是Meta推出的自监督视觉模型,支持冻结主干、仅训练轻量任务头即可在分割、深度估计等任务上达到SOTA,极大降低训练成本。其密集特征质量优异,适用于遥感、工业检测等多领域,真正实现“一个模型走天下”。

3 个真实 GEO 成功案例 + 3 步关键词排名秘籍!开发者 / 企业快速落地 GEO,流量 & 转化双提升
本文聚焦 GEO 真实获客案例与实操技巧,通过教培机构、工业设备商、小众茶叶品牌三个实测案例,展现 GEO 落地成效:教培机构靠升学数据咨询量暴增 210%,工业设备商盯准技术痛点让单笔订单翻 5 倍,茶叶品牌借产地溯源实现客单价从 200 元飙至 500 元。核心分享三步零门槛关键词法:列客户痛点、加场景限定、数据筛词,还拆解了不同平台关键词偏好。提醒效果需 1-3 个月积累,内容需真实且持续优化。新手可直接对照案例思路,结合自身行业调整,快速抢占搜索流量,精准获客。

完整教程:从0到1在Windows下训练YOLOv8模型
本文详细介绍在Windows系统下使用YOLOv8训练目标检测模型的完整步骤,涵盖环境配置、数据集准备、模型训练与测试、常见问题解决及GPU加速技巧。提供详细命令与代码示例,并推荐现成数据集与工具,助您高效完成模型训练。
寻找 AI 全能王——阿里云 Data+AI 工程师全球大奖赛正式开启
在AI迈向专业决策的关键节点,阿里云联合NVIDIA发起“寻找AI全能王”全球大奖赛,聚焦高质量数据构建与智能体开发两大挑战。赛事设高校与企业双赛道,覆盖万亿语料去重与DeepSearch智能体构建,提供工业级实战平台、专家指导与丰厚奖励,推动Data+AI融合创新,助力开发者实现“所想即所得”的技术突破。
人工智能技术全流程入门:10 个关键步骤快速上手
本教程系统讲解人工智能入门10大核心步骤,涵盖基础认知、工具使用、数据理解、实操应用与伦理规范,结合场景导向与避坑指南,帮助新手快速掌握AI技术应用逻辑,轻松实现从零到一的跨越,助力职场增效与技能提升。
国内最大的MCP中文社区来了,4000多个服务等你体验
国内最大的MCP中文社区MCPServers来了!平台汇聚4000多个服务资源,涵盖娱乐、监控、云平台等多个领域,为开发者提供一站式技术支持。不仅有丰富的中文学习资料,还有详细的实战教程,如一键接入MCP天气服务等。MCPServers专注模块稳定性和实用性,经过99.99% SLA认证,是高效开发的理想选择。立即访问mcpservers.cn,开启你的开发之旅!
别再搞混了!一文看懂“显存”与“内存”:从办公桌到实验室的硬核分工
本文以生动比喻与硬核解析,深入浅出地讲清内存(RAM)与显存(VRAM)的本质区别:内存是CPU的通用工作台,显存是GPU的专用高速实验室。二者分工明确,数据需通过PCIe传输,无法互相替代。尤其在AI训练中,显存容量与带宽直接决定模型能否运行。文章结合代码实例、性能对比表及排错指南,帮助开发者理解“CUDA out of memory”等常见问题,并提供优化策略与云平台建议,是迈向高效AI开发的必读指南。
从零搭建RAG系统:原理剖析+代码实践,解锁大模型“记忆力”新姿势
RAG(检索增强生成)为大模型配备“外接大脑”,通过连接专属知识库,提升回答准确性。广泛应用于医疗、法律、客服等领域,兼具专业性与可解释性。本文详解其原理、实战步骤与优化技巧,助你快速构建个性化AI助手。

实用工具:VS Code 配置 Markdown 编译器全指南
本文介绍如何在VS Code中配置高效Markdown写作环境,通过启用内置预览、安装Markdown All in One与Markdown Preview Enhanced插件,并配置Princexml实现PDF等格式导出,全面提升编辑、预览与输出效率,适合程序员、学生及内容创作者使用。
从入门到选型:GEO生成式引擎优化科普与优质geo优化服务商推荐
GEO(生成式引擎优化)正取代SEO,助力企业在AI搜索中抢占流量先机。本文解析GEO核心逻辑,对比SEO差异,揭示其提升获客效率2.8倍的潜力,并结合国内外权威数据,分场景推荐适配的优质服务商,助企业从懂原理到会选型,规避布局风险。
从零开始:如何训练自己的AI模型
### 从零开始:如何训练自己的AI模型 训练AI模型如同培养新生儿,需耐心与技巧。首先明确目标(如图像识别、自然语言处理),选择框架(TensorFlow、PyTorch)。接着收集并预处理数据,确保多样性和准确性。然后设计模型结构,如卷积神经网络(CNN),并通过代码实现训练。训练后评估模型性能,调优以避免过拟合。最后部署模型至实际应用。通过猫狗分类器案例,掌握关键步骤和常见问题。训练AI模型是不断迭代优化的过程,实践才能真正掌握精髓。
阿里云服务器上部署ROS2+Isaac-Sim4.5实现LeRobot机械臂操控
本文介绍了如何在阿里云上申请和配置一台GPU云服务器,并通过ROS2与Isaac Sim搭建机械臂仿真平台。内容涵盖服务器申请、系统配置、远程连接、环境搭建、仿真平台使用及ROS2操控程序的编写,帮助开发者快速部署机器人开发环境。
2025 最新史上最全 Java 面试题独家整理带详细答案及解析
本文从Java基础、面向对象、多线程与并发等方面详细解析常见面试题及答案,并结合实际应用帮助理解。内容涵盖基本数据类型、自动装箱拆箱、String类区别,面向对象三大特性(封装、继承、多态),线程创建与安全问题解决方法,以及集合框架如ArrayList与LinkedList的对比和HashMap工作原理。适合准备面试或深入学习Java的开发者参考。附代码获取链接:[点此下载](https://pan.quark.cn/s/14fcf913bae6)。
告别数据丢失!跨平台同步工具FreeFileSync 14.2下载教程|手把手配置多设备备份
FreeFileSync 14.2 是一款开源跨平台文件同步工具,支持 Windows、macOS 和 Linux 系统。新增功能包括实时同步监控、云存储集成(Google Drive 和 Dropbox)、智能冲突解决及性能优化,适用于数据备份、服务器文件同步等场景。本文详细介绍其下载、安装、配置及高级使用技巧,并提供常见问题解答和延伸学习资源。
开源大模型微调对比:选对模型,让定制化更高效
本文对比Llama 3、Qwen2.5、Mistral三款开源大模型在中文场景下的微调表现,从算力门槛、数据效率、任务适配性等维度分析,结合实战案例与主观评估,为开发者提供选型建议,助力高效构建定制化AI模型。
一键解决 Office 卸载难题!微软官方卸载工具,点击下载开启轻松卸载之旅
微软官方Office卸载工具可彻底清除Office 2007至2021及365版本残留,解决重装报错问题。支持深度扫描与一键卸载,操作简单,卸载后需重启生效。
大模型微调技术入门:从核心概念到实战落地全攻略
大模型微调是通过特定数据优化预训练模型的技术,实现任务专属能力。全量微调精度高但成本大,LoRA/QLoRA等高效方法仅调部分参数,显存低、速度快,适合工业应用。广泛用于对话定制、领域知识注入、复杂推理与Agent升级。主流工具如LLaMA-Factory、Unsloth、Swift等简化流程,配合EvalScope评估,助力开发者低成本打造专属模型。
PAI-TurboX:面向自动驾驶的训练推理加速框架
PAI-TurboX 为自动驾驶场景中的复杂数据预处理、离线大规模模型训练和实时智能驾驶推理,提供了全方位的加速解决方案。PAI-Notebook Gallery 提供PAI-TurboX 一键启动的 Notebook 最佳实践
网站搭建黑科技:AI 写前端页面 + CMS 管理系统搭建实操指南
本文聚焦 AI 编程前端开发与 PageAdmin CMS 集成的可落地技术方案。先详解 AI 编程前端的三类核心途径(设计稿直转、提示词驱动、脚手架生成)及标准化操作步骤,再阐述 PageAdmin CMS 的环境配置、部署流程,以及栏目模型配置、API 对接、数据渲染等集成实操,形成 “AI 提效 + CMS 赋能” 的网站搭建技术闭环,为开发者提供工程化指引。
vLLM 吞吐量优化实战:10个KV-Cache调优方法让tokens/sec翻倍
十个经过实战检验的 vLLM KV-cache 优化方法 —— 量化、分块预填充、前缀重用、滑动窗口、ROPE 缩放、后端选择等等 —— 提升 tokens/sec。

用PyTorch从零构建 DeepSeek R1:模型架构和分步训练详解
本文详细介绍了DeepSeek R1模型的构建过程,涵盖从基础模型选型到多阶段训练流程,再到关键技术如强化学习、拒绝采样和知识蒸馏的应用。
PDF 转 Markdown 神器:MinerU 2.5 (1.2B) 部署全攻略
MinerU是由OpenDataLab推出的开源PDF解析工具,支持精准布局分析、公式识别与表格提取。本文详解其2.5-2509-1.2B版本在Linux下的部署流程,涵盖环境搭建、模型下载、核心配置及实战应用,助你高效处理复杂PDF文档,提升AI数据清洗效率。
大模型产生幻觉的原因,如何解决?
大模型“幻觉”指AI生成看似合理但错误或虚构的信息,源于其概率预测机制、训练数据缺陷及缺乏事实核查能力。可通过RAG、微调、联网检索、自我核查等方法降低幻觉风险,提升输出准确性与可靠性。(238字)
GLM-4V-9B 视觉多模态模型本地部署教程【保姆级教程】
本教程详细介绍如何在Linux服务器上本地部署智谱AI的GLM-4V-9B视觉多模态模型,涵盖环境配置、模型下载、推理代码及4-bit量化、vLLM加速等优化方案,助力高效实现图文理解与私有化应用。
Python:ImportError:DLL loadfailed while importing onnxruntime_pybind11_state: 动态链接库(DLL)初始化例程失败 报错解决
在进行文件夹内人脸识别与对比聚类时,遇到onnxruntime库报错,通常因版本不兼容或环境冲突导致。本文整理了五种解决方案:降级onnxruntime至1.14.1、重装库、区分GPU/CPU版本、安装Visual C++运行库、创建Python虚拟环境。通过版本匹配与环境隔离,有效解决DLL初始化失败等问题,提升项目稳定性。
PyCharm 2025.1 完整教程:下载安装 + 中文设置 + 激活,一步到位,附安装包
PyCharm 2025.1 发布,重磅升级AI代码补全、类型推断与ruff集成,提升开发效率。支持渐进式补全、智能提交信息生成、冲突可视化解决,优化启动速度与内存占用,全面增强云原生及现代Python开发体验。

vLLM推理加速指南:7个技巧让QPS提升30-60%
GPU资源有限,提升推理效率需多管齐下。本文分享vLLM实战调优七招:请求塑形、KV缓存复用、推测解码、量化、并行策略、准入控制与预热监控。结合代码与数据,助你最大化吞吐、降低延迟,实现高QPS稳定服务。
如何将Kindle电子书下载到电脑:技术流程与操作解析
随着数字阅读兴起,Kindle成为主流电子书平台。然而,Amazon的封闭生态和DRM限制,使用户难以灵活管理书籍。本文从技术角度出发,讲解如何合法下载Kindle电子书至电脑,包括使用Kindle for PC、USB导出及进阶方案(如Android模拟器、WINE环境)。同时介绍文件格式处理、自动化备份与阅读体验优化方法,并强调版权合规的重要性,助您构建个人数字图书馆。

从零开始构建AI Agent评估体系:12种LangSmith评估方法详解
AI Agent的评估需覆盖其整个生命周期,从开发到部署,综合考量事实准确性、推理路径、工具选择、结构化输出、多轮对话及实时性能等维度。LangSmith作为主流评估平台,提供了一套全面的评估框架,支持12种评估技术,包括基于标准答案、程序性分析及观察性评估。这些技术可有效监控Agent各组件表现,确保其在真实场景中的稳定性和可靠性。
阿里云服务器多少钱一年?整理2026年云服务器新购、续费和升级配置费用清单
阿里云2026年服务器价格出炉!轻量服务器低至38元/年,ECS新购续费同价,2核2G仅99元/年起。本文详解轻量服务器与ECS区别、配置费用、升级规则及省钱技巧,助你选对方案,轻松上云,一年省下上千元。

大语言模型中的归一化技术:LayerNorm与RMSNorm的深入研究
本文分析了大规模Transformer架构(如LLama)中归一化技术的关键作用,重点探讨了LayerNorm被RMSNorm替代的原因。归一化通过调整数据量纲保持分布形态不变,提升计算稳定性和收敛速度。LayerNorm通过均值和方差归一化确保数值稳定,适用于序列模型;而RMSNorm仅使用均方根归一化,省略均值计算,降低计算成本并缓解梯度消失问题。RMSNorm在深层网络中表现出更高的训练稳定性和效率,为复杂模型性能提升做出重要贡献。
阿里云DLF 3.0:面向AI时代的智能全模态湖仓管理平台
在2025年云栖大会,阿里云发布DLF 3.0,升级为面向AI时代的智能全模态湖仓管理平台。支持结构化与非结构化数据统一管理,实现秒级实时处理、智能存储优化与细粒度安全控制,助力企业高效构建Data+AI基础设施。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
