
oceanbase数据库的T表和B表 都有索引 为啥left join 时间这么大
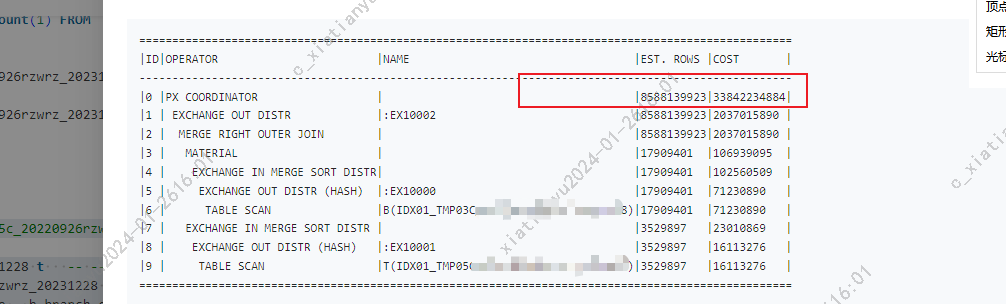
oceanbase数据库的T表和B表 都有索引 为啥left join 时间这么大?数据量分别在700w 1000w
展开
收起
2
条回答
 写回答
写回答
-

用sql audit 看看,发到社区问答上 把表结构也发一下吧。—此回答来自钉群“[社区]技术答疑群OceanBase”
2024-01-30 14:27:10赞同 展开评论 打赏 -
在OceanBase数据库中,T表和B表都有索引的情况下执行LEFT JOIN操作,查询耗时较大可能的原因有很多。以下是可能导致LEFT JOIN效率较低的一些常见因素:
索引选择与覆盖:
- 虽然两个表都有索引,但JOIN操作所依据的字段可能并未在现有索引中,或者索引未被优化器有效利用。JOIN条件中使用的字段如果没有合适的索引支持,尤其是当涉及到非主键或非唯一键的大范围扫描时,会导致全表扫描或索引扫描效率低下。
- 即使索引存在,但如果JOIN条件无法通过索引直接满足,即索引无法覆盖JOIN所需的所有列,那么即使进行了索引扫描,也还需要额外的随机I/O去获取其他列的数据。
数据分布与分区:
- 分布式数据库中,数据分布和分区策略对JOIN效率至关重要。如果JOIN操作跨越大量分区,或者分区键选择不合理,导致数据无法在分区内完成JOIN,将大大增加数据交换的成本,进而影响整体性能。
数据倾斜:
- 在分布式数据库中,如果JOIN的两边数据分布不均匀,某些分区的数据量远大于其他分区,那么整个JOIN过程就会受到最慢那个分区的影响,造成整体性能下降。
JOIN顺序与关联算法:
- 查询优化器选择的JOIN顺序可能并非最优,尤其是在大表JOIN时,选择先执行小表JOIN或利用索引连接算法(如Index Nested-Loop Join)的效果会更好。但如果选择了全表扫描配合Nested Loop Join等低效算法,即使有索引也可能导致性能瓶颈。
内存资源与缓存命中率:
- 执行JOIN操作时,需要用到大量的内存资源,包括排序、缓冲池等。如果内存不足,可能导致频繁的磁盘I/O操作,从而降低性能。此外,索引和数据块能否有效缓存在内存中,也是影响JOIN速度的重要因素。
针对以上分析,您可以采取以下措施来优化LEFT JOIN操作:
- 确保JOIN条件字段有适当的索引,并检查查询计划确认优化器是否有效地利用了这些索引。
- 调整数据分区策略,尽量让JOIN操作能在分区内部完成,减少跨分区的数据传输。
- 分析数据分布,避免或减轻数据倾斜带来的负面影响。
- 使用EXPLAIN命令查看执行计划,考虑调整JOIN顺序或使用hint强制指定某种JOIN算法。
- 根据实际业务需求和资源状况,适当调整数据库参数,优化内存使用和缓存策略。
最后,针对700万和1000万这样规模的数据量,如果JOIN查询依然较慢,应当详细审查查询计划并结合OceanBase数据库特有的分布式特性和调优手段来进行深度优化。同时,定期进行维护和监控,及时发现并解决潜在的性能瓶颈。
2024-01-30 13:16:53赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

问答排行榜
最热
最新


推荐问答


