问题一:Flink CDC 里flink application 模式提交能声明环境变量不?
Flink CDC 里flink application 模式提交能声明环境变量不?
参考答案:
当使用 ./bin/flink run-application 命令提交 Flink 应用程序时,可以在命令行中添加 -Dkey=value 格式的 JVM 系统属性参数,这些系统属性会被转化为环境变量传递给各个进程。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602864
问题二:Flink CDC 里server_id是保证每个并发唯一还是只用作业层面唯一就行?
Flink CDC 里server_id是保证每个并发唯一还是只用作业层面唯一就行?
参考答案:
每个source的task 唯一。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602863
问题三:Flink CDC 里怎么发现从ck恢复后的任务不再自动做ck了啊?
Flink CDC 里怎么发现从ck恢复后的任务不再自动做ck了啊? 
参考答案:
Checkpoint 间隔配置问题: 检查 Flink 配置中关于 checkpoint 的间隔时间是否正确设置,比如 execution.checkpoint.interval 参数,确保其不是设置得过大或设置为了 DISABLED。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602855
问题四:flink cdc在全量快照初始化阶段 如果任务异常自动从ck restore后 会这样吗?
flink cdc在全量快照初始化阶段 如果任务异常自动从ck restore后 会从上次binlog断点续传么? 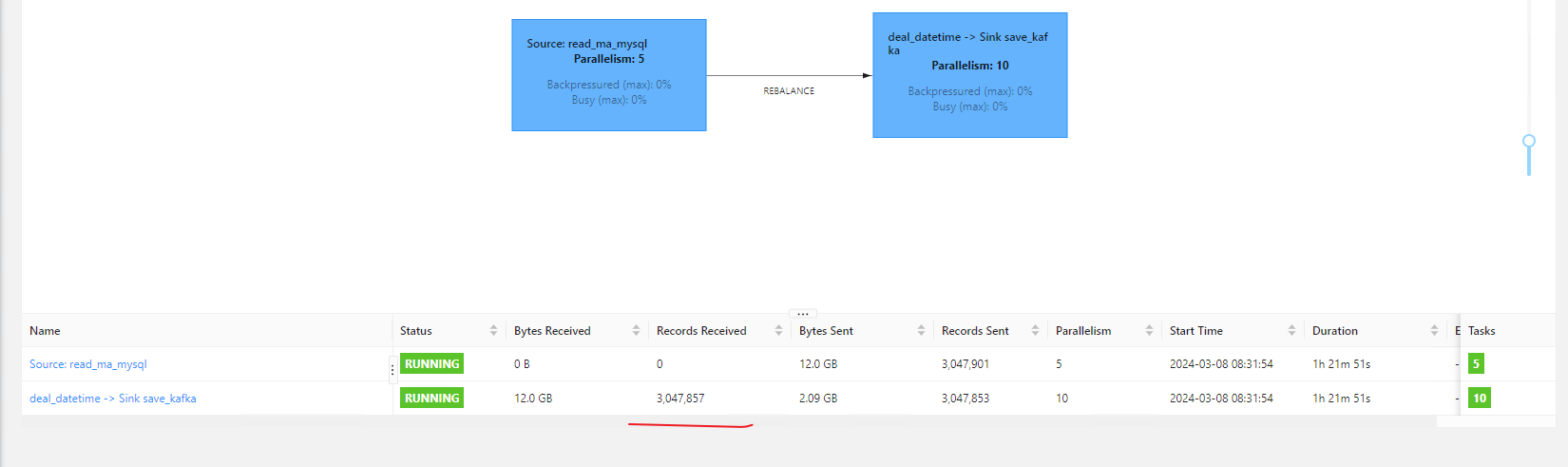
参考答案:
全量阶段是走的jdbc吧,只是会先保存一个读取位置,后面全量阶段完成之后,从那个binlog位置接着往下写。据我印象中,全量阶段会切分chunk,ck理论上会保留已经写过的chunk信息,后面就可以断点续传,binlog的位置也是从断点开始的吧。增量快照支持历史数据断点续传。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602851
问题五:Flink CDC 里哪找 k8s flink-cdc 的部署手册或者参考文档?
Flink CDC 里哪找 k8s flink-cdc 的部署手册或者参考文档?
参考答案:
Flink on k8s 环境搭建(一)https://blog.csdn.net/wangqiaowq/article/details/131800658
Flink on Yarn的环境搭建过程中,需要进行配置较多,且需要搭建zookeeper Hadoop Yarn 等相关组件,安装流程比较复杂,集群出现问题重新安装的流程也比较复杂,且Yarn的3个节点中 只能起了 3个resourceManager和1个NodeManager,Flink 作业申请资源时只能 向NodeManager的节点申请资源,整体有资源瓶颈的隐患(后继flink作业会越来越多),现在尝试进行Flink on k8s 的环境搭建。
Flink on Kubernetes(也称为Flink on K8s)是指在Kubernetes集群上运行Apache Flink分布式流处理框架。
Kubernetes是一个开源的容器编排平台,可以帮助管理容器化的应用程序,并提供弹性、可伸缩和可靠的部署环境。结合Flink和Kubernetes,可以实现高效的大规模数据流处理。
Flink on K8s 提供了以下优势:
- 弹性伸缩:Kubernetes可以根据负载自动扩展和收缩Flink作业所需的任务资源。
- 容器化管理:Flink作业可以作为容器运行,并且可以受益于Kubernetes的容器化管理功能,例如版本管理、生命周期管理和监控等。
- 故障恢复:Kubernetes可以自动检测和替代故障节点,提供高可用性和容错性,确保作业持续运行。
要在Kubernetes上运行Flink,您可以使用Apache Flink官方提供的Kubernetes部署工具或其他第三方工具,如Helm Chart。
通过Kubernetes部署Flink,您可以使用Kubernetes的API和资源管理功能,有效地管理和部署您的Flink作业。这样,您可以轻松地扩展Flink集群的规模,实现动态自动化的资源分配和作业调度。
K8s 环境搭建 
参考 https://blog.csdn.net/wangqiaowq/article/details/131800658
关于本问题的更多回答可点击进行查看:
