问题一:Flink CDC如何向flinksql的表连接配置设置参数?
Flink CDC如何向flinksql的表连接配置设置参数?
参考答案:
Flink CDC 向 Flink SQL 的表连接配置设置参数可以通过以下步骤进行:
- 首先,确保你已经在 Flink 中启用了 CDC。你可以通过在 Flink 配置文件(flink-conf.yaml)中添加以下配置来启用 CDC:
jobmanager.execution.failover-strategy: region streams.parallelism.default: 1 table.sql-dialect: org.apache.flink.table.postgres.PostgresDialect table.types.blacklist: hive,mapred,tez,yarn table.catalog: mycatalog table.schema-registry.url: http://localhost:8081 table.sink.partition-commit.trigger: periodic(5s)
- 然后,你需要创建一个 Flink SQL 表来接收 CDC 数据。你可以使用
CREATE TABLE语句来定义表的结构,并指定要使用的源表和数据格式。例如,假设你要从名为mysource的源表中读取 CDC 数据,并将其存储到名为mysink的目标表中,可以使用以下语句创建表:
CREATE TABLE mysink ( column1 INT, column2 STRING, ... ) WITH ( 'connector' = 'kafka', 'topic' = 'mytopic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json' );
- 现在,你可以使用 Flink SQL 的连接操作将多个表连接起来。在查询中使用
JOIN、LEFT JOIN、RIGHT JOIN、INNER JOIN等关键字来指定连接类型和条件。例如,假设你有两个表table1和table2,并且你想要根据某个列进行内连接,可以使用以下语句:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id;
- 如果需要设置连接的其他参数,可以在连接操作后使用括号指定。例如,你可以使用
ON子句来指定连接条件,使用USING子句来指定连接键的列名,以及使用WHERE子句来添加过滤条件。例如:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id AND table1.column3 > table2.column4 WHERE table1.column5 = 'some_value';
通过以上步骤,你可以在 Flink SQL 中配置表连接并设置相关参数。请注意,具体的语法和选项可能因所使用的连接器和数据格式而有所不同,你需要根据实际情况进行调整。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/577424
问题二:Flink CDC中flink run命令启动任务后,我vim XX.jar 里面能找到这个包呀?
Flink CDC中flink run命令启动任务后,log里提示少包,但是我vim XX.jar 里面能找到这个包呀? 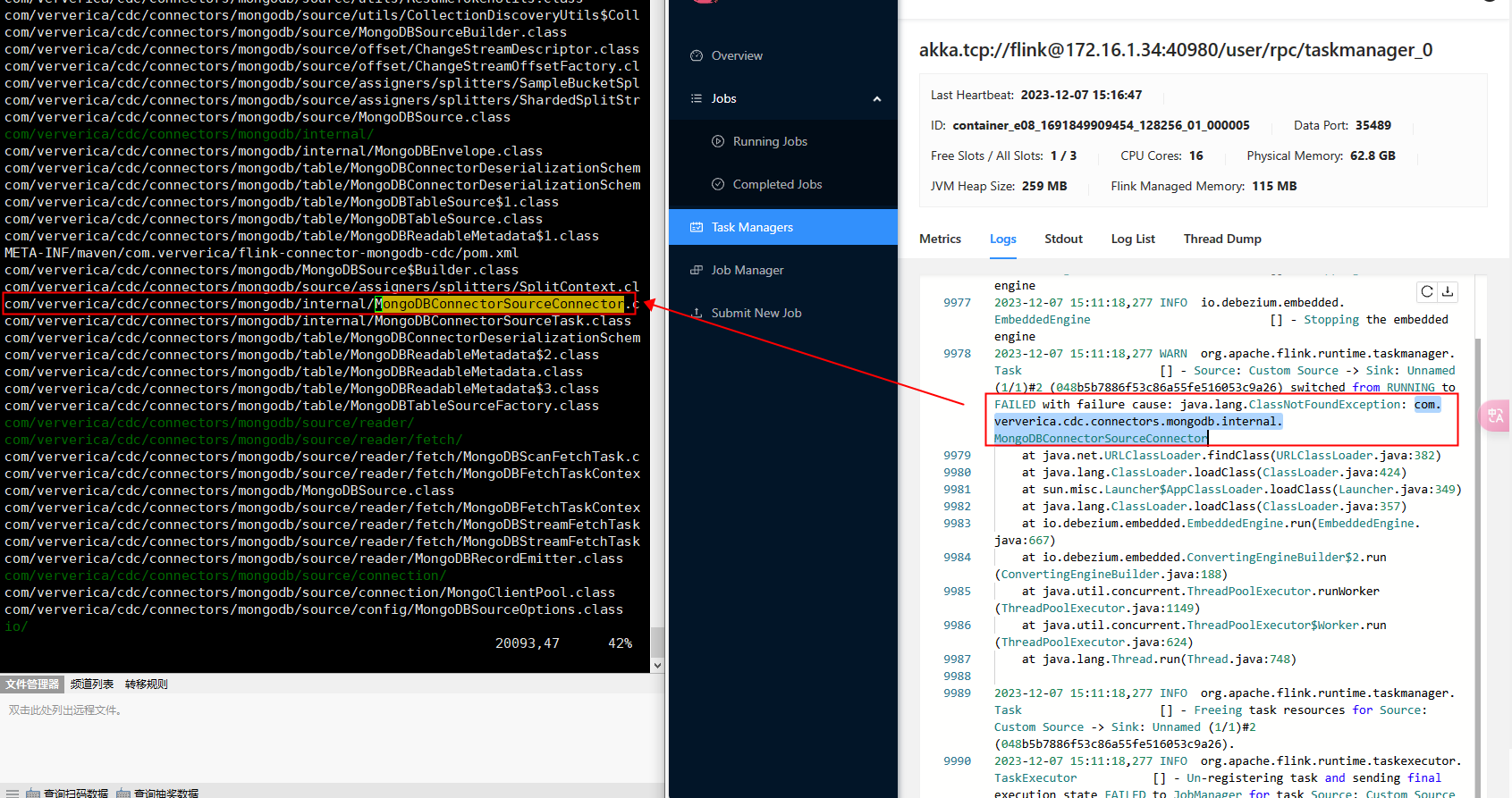
参考答案:
这个问题可能是由于Flink作业所使用的classpath与jar包所在的路径不一致导致的。当你使用flink run命令启动任务时,Flink会将其classpath设置为包含当前目录和所有依赖jar包的路径。但是,如果你在IDE(如IntelliJ IDEA)中运行Flink作业,那么IDEA可能会将classpath设置为只包含当前模块的依赖项。因此,即使jar包在你的本地文件系统中存在,但在运行时可能无法被正确加载。
解决这个问题的一种方法是确保你在所有环境中都使用相同的classpath设置。例如,你可以在运行Flink作业之前手动添加jar包到classpath中,或者将jar包安装到本地Maven仓库或远程仓库中,以便Flink可以从那里自动下载它们。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/577423
问题三:flinkcdc一直在循环打印结果,是什么情况?
flinkcdc一直在循环打印结果,是什么情况?
参考答案:
Flink CDC 一直在循环打印结果可能是由于以下几种情况:
- Flink CDC 的 source 配置不正确:请确保你正确配置了 Flink CDC 的 source,包括数据库连接信息、要读取的表和字段等。如果配置不正确,可能会导致 Flink CDC 无法正常读取数据并一直循环打印结果。
- Flink CDC 的窗口设置不正确:如果你使用了窗口函数(如 COUNT、SUM 等),并且窗口设置不正确,可能会导致 Flink CDC 一直循环打印结果。请确保你正确设置了窗口的大小、滑动步长和聚合函数等参数。
- Flink CDC 的并行度设置过高:如果你将 Flink CDC 的并行度设置得过高,可能会导致 Flink CDC 一直循环打印结果。请尝试降低并行度,看看是否能够解决问题。
- Flink CDC 的数据源有异常:如果 Flink CDC 的数据源出现异常,例如数据库连接中断或表结构发生变化等,可能会导致 Flink CDC 一直循环打印结果。请检查数据源是否正常工作,并确保没有发生异常。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/577422
问题四:Flink CDC这种依赖到底要怎么找是哪个包缺了呢?
Flink CDC这种依赖到底要怎么找是哪个包缺了呢? 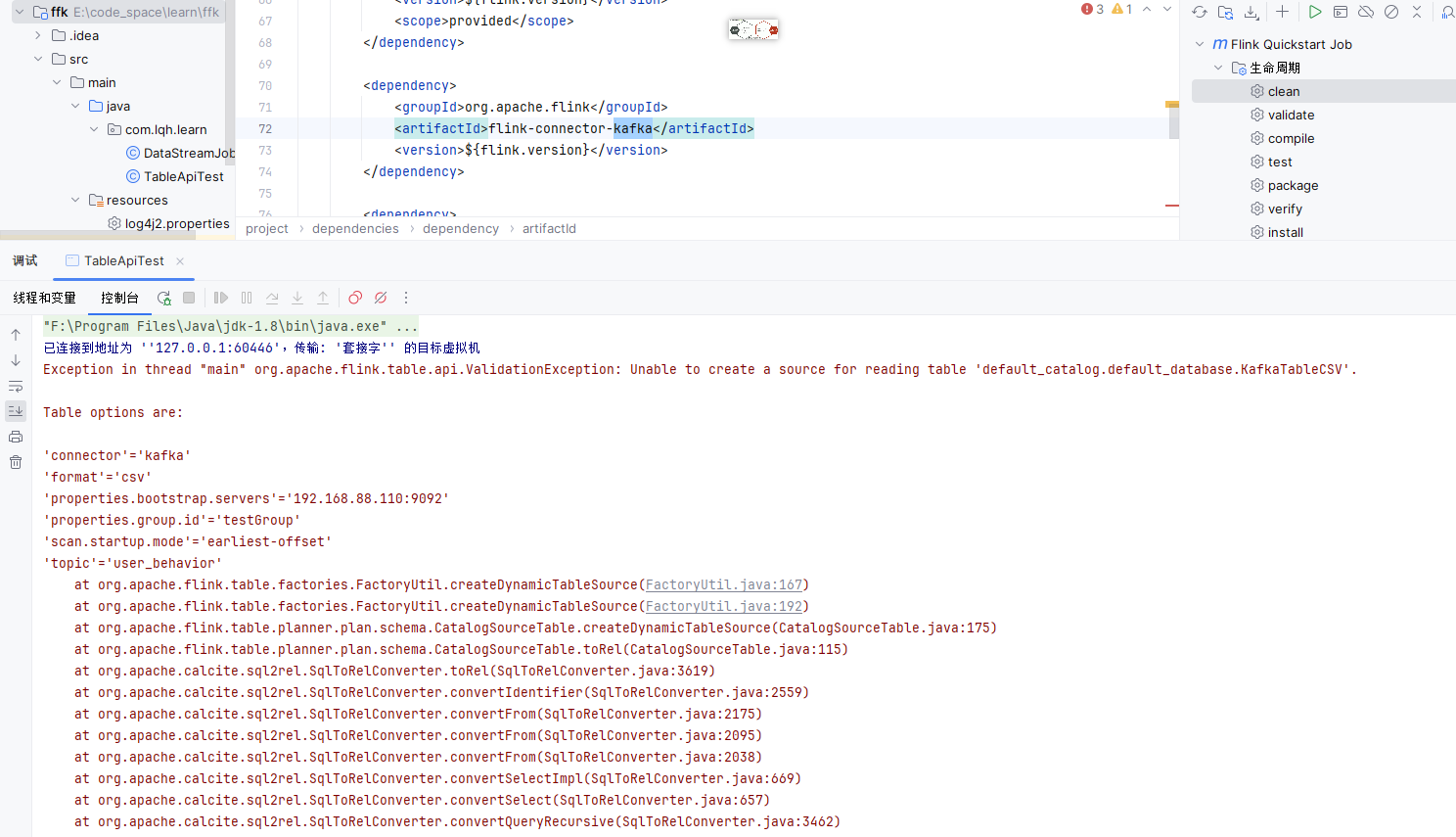
参考答案:
不一定是缺包,看错误是option 错了
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/577421
问题五:Flink CDC业务删除和归档删除在binlog日志层面有区别吗?
Flink CDC业务删除和归档删除在binlog日志层面有区别吗?
参考答案:
对于Flink CDC业务删除和归档删除在binlog日志层面是否有区别,目前没有明确的资料说明它们之间存在明显的区别。但是,我们可以了解到,当Flink CDC的原始表中的数据被删除,但结果表未被删除时,可能的原因是Flink CDC作业未能正常消费对应的删除事件。此外,Flink CDC中同步过久可能会出现快照过久问题,导致状态大小超过了配置的阈值,引发异常
关于本问题的更多回答可点击进行查看:
