
Flink CDC这种依赖到底要怎么找是哪个包缺了呢? 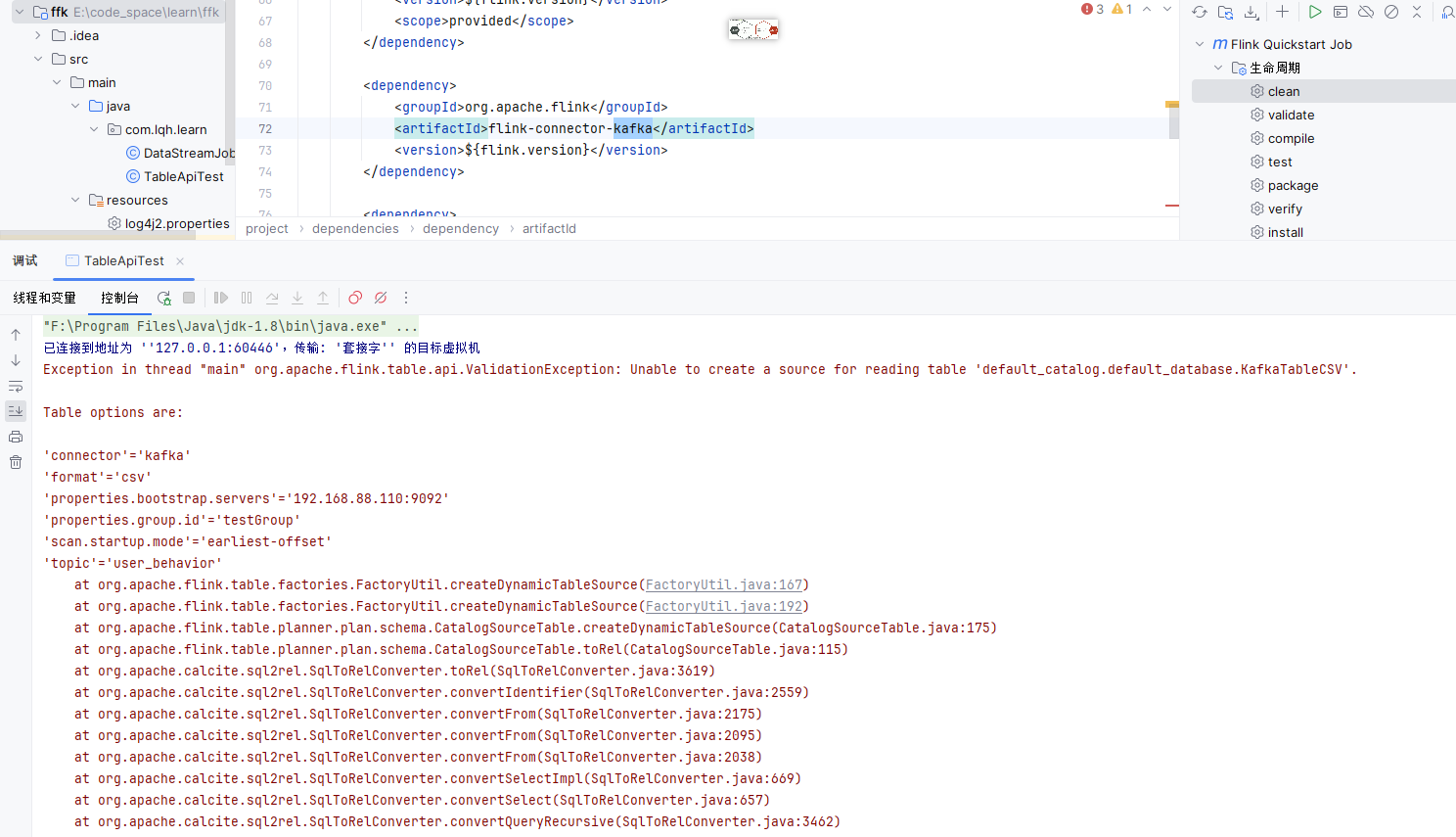
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC (Apache Kafka Connect for Apache Flink) 是一个用于将数据从 Apache Kafka 迁移到 Apache Flink 的开源项目。它允许用户通过定义自定义转换函数来自定义数据迁移过程。
如果你遇到找不到 flink-connector-kafka 包的问题,可以按照以下几个步骤排查:
首先确认你的 Maven 或 Gradle 工作空间中是否存在正确的依赖项。请查看项目的 pom.xml 文件(Maven)或 build.gradle 文件(Gradle),确保已经正确添加了 flink-connector-kafka 相关的依赖库。
对于 Maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
对于 Gradle:
implementation 'org.apache.flink:flink-connector-kafka_$(scala.binary.version):${flink.version}'
其中 ${scala.binary.version} 应该替换为实际使用的 Scala 版本号。
然后检查你正在编译的目标版本与所引用的 jar 包是否匹配。确保你在本地环境中安装了对应的 Flink 版本以及相应的 Kafka 连接器插件。
最后,在构建过程中确保所有所需的依赖关系都已成功下载到本地仓库。你可以通过运行 mvn dependency:tree (对于 Maven)或 ./gradlew dependencies (对于 Gradle)命令来验证这一点。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


