问题一:Flink CDC系统配置和环境怎么样的,现在采集oracle全量支持多并行度吗?
Flink CDC系统配置和环境怎么样的,看这张图是支持source并行度了,我现在采集oracle全量支持多并行度吗?
参考答案:
用增量算法去多并行度
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579949
问题二:Flink CDC原表字段增加或者类型修改,目标表有没有好的方案自动调整?
Flink CDC原表字段增加或者类型修改,目标表有没有好的方案自动调整?
参考答案:
Flink CDC支持自动同步整库的全量和增量数据,并且可以实时将每张源表的表结构变更(如加列等)同步到对应的目标表中。然而,需要注意的是,如果新增字段,那么下游可能无法收到新增字段的数据,如果删除字段,那么Flink任务可能会出现报错。
对于这种情况,可以通过自定义扩展来解决。例如,可以实现自己的DebeziumDeserializationSchema,将binlog数据转换为JSON,或者根据业务需求实现更个性化的操作,例如向下游发送自定义的Schema变更通知等等。这样即使原表字段增加或者类型修改,也可以在目标表中得到相应的调整。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579948
问题三:Flink CDC中flinksql怎么打印日志啊?
Flink CDC中flinksql怎么打印日志啊?
参考答案:
在Flink SQL中,可以通过以下方式打印日志:
- 使用
set log.level命令设置日志级别。例如,将日志级别设置为DEBUG:
SET log.level = 'DEBUG';
- 这将打印出更详细的日志信息。
- 使用
show source命令查看源表的详细信息。例如,查看名为my_source_table的源表的详细信息:
SHOW SOURCE my_source_table;
- 这将显示与该源表相关的日志信息。
- 使用
EXPLAIN命令查看查询计划和执行计划。例如,查看名为my_query的查询的执行计划:
EXPLAIN my_query;
- 这将显示与该查询相关的日志信息,包括执行计划、资源消耗等。
- 使用
SET table.exec.result.log.enabled命令启用结果集日志记录。例如,启用名为my_sink_table的目标表的结果集日志记录:
SET table.exec.result.log.enabled=true;
- 这将打印出目标表的结果集日志信息。
请注意,以上方法适用于Flink SQL CLI或IDE中执行的SQL语句。如果你使用的是其他方式(如提交作业到Flink集群),则需要在相应的配置中设置日志级别或启用日志记录功能。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579946
问题四:Flink CDC再加上输出条件:条数+开窗window时间,会变慢一点,还有其它什么好建议提升?
Flink CDC再加上输出条件:条数+开窗window时间,会变慢一点,还有其它什么好建议提升source端?
参考答案:
Flink CDC的输出条件中加入条数和开窗时间窗口确实会对性能产生一定的影响,因为需要对数据进行额外的过滤和聚合操作。以下是一些提升source端性能的建议:
- 调整并行度:适当增加或减少并行度可以优化任务的执行效率。可以尝试不同的并行度设置,找到最佳的并行度值。
- 调整checkpoint间隔:checkpoint是Flink中用于容错和状态保存的重要机制,但频繁的checkpoint会降低性能。可以尝试调整checkpoint间隔,以平衡性能和容错性。
- 使用异步IO:Flink支持异步IO,可以提高数据的读取速度。可以尝试开启异步IO,并适当调整相关参数。
- 使用增量检查点:增量检查点可以减少每个checkpoint的数据量,从而提高性能。可以尝试开启增量检查点功能。
- 优化SQL语句:如果使用了SQL语句进行数据处理,可以尝试优化SQL语句,例如使用合适的索引、避免全表扫描等。
- 使用更高效的数据结构:根据具体的业务需求,选择合适的数据结构可以提高处理效率。例如,如果需要频繁地进行聚合操作,可以考虑使用Bloom Filter等高效的数据结构。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579945
问题五:Flink CDC增量source 并行度1,导致的拉取数据处理不过来,这个有啥优化方案吗?
Flink CDC增量source 并行度1,导致的拉取数据处理不过来,flink下游的数据量明显低于mysql数据量,造成延迟。这个有啥优化方案吗? 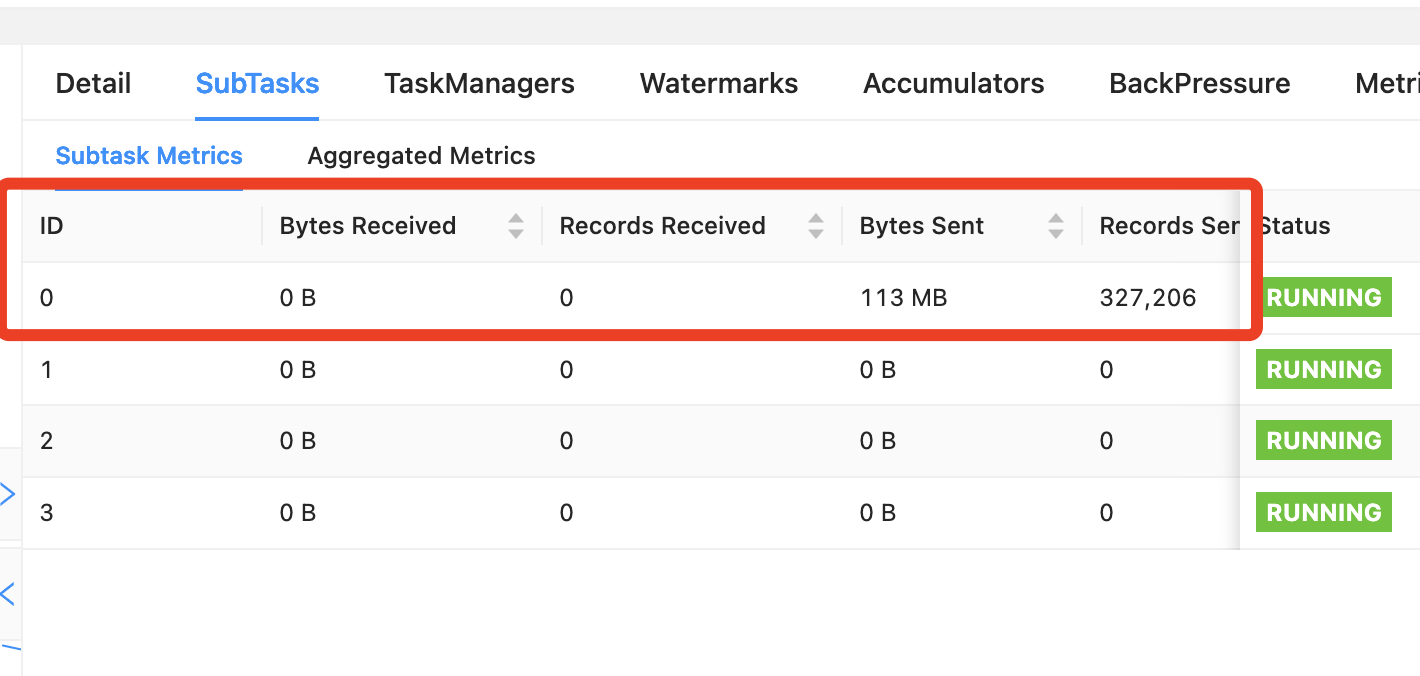
参考答案:
当Flink CDC的Source并行度设置为1,可能会因为单个任务线程无法及时处理MySQL数据库产生的大量变更数据,进而导致下游的数据处理滞后和延迟增大。针对这种情况,可以尝试以下几种优化方案:
- 增加Source并行度:
- 提高Flink CDC Source任务的并行度是最直接的优化手段,这样可以从MySQL binlog中并发地读取和处理更多的数据。每个并行的source实例会独立消费binlog,从而提升整体的拉取和处理能力。
- 调整其他相关配置:
max.batch.size或fetch.size类似的参数可以控制每次从MySQL读取的事件数量,适当增加可以减少网络交互次数,但需注意防止内存溢出。buffer.memory或queue.capacity控制缓冲区大小,确保有足够的空间存储拉取到的事件,避免因为缓冲区不足而限制拉取速度。heartbeat.interval.ms和相关的超时参数,确保上游MySQL服务器与Flink CDC之间的心跳和连接稳定。
- 优化下游处理逻辑:
- 如果下游算子处理逻辑复杂或耗时,那么即使增加Source并行度也可能受限于下游瓶颈。检查并优化下游operator,如是否可以增加其并行度,或者简化计算逻辑以提高处理效率。
- 监控与资源分配:
- 确保Flink集群有足够的计算资源,如CPU、内存等,以便在增加并行度后能提供足够的处理能力。
- 对任务进行实时监控,查看是否存在任何异常情况或资源争抢,如IO瓶颈、网络带宽限制等,并针对性优化。
- Binlog格式与过滤条件:
- 根据业务需求,只捕获必要的数据库表和列变化,避免无谓的资源消耗,进一步提高处理效率。
- 错误处理与重试策略:
- 设置合理的错误处理和重试策略,确保偶发错误不会导致整个任务停滞,保持数据流的连续性和稳定性。
通过上述措施综合调整和优化,可以有效缓解由于Source并行度过低造成的MySQL数据拉取延迟问题。当然,在实际操作前,请务必结合具体的应用场景和系统环境进行细致评估和测试。
关于本问题的更多回答可点击进行查看:


