问题一:Flink CDC读取不到mongo的数据,有大大碰到过这种问题没,怪的一批?
Flink CDC读取不到mongo的数据,有大大碰到过这种问题没,怪的一批? 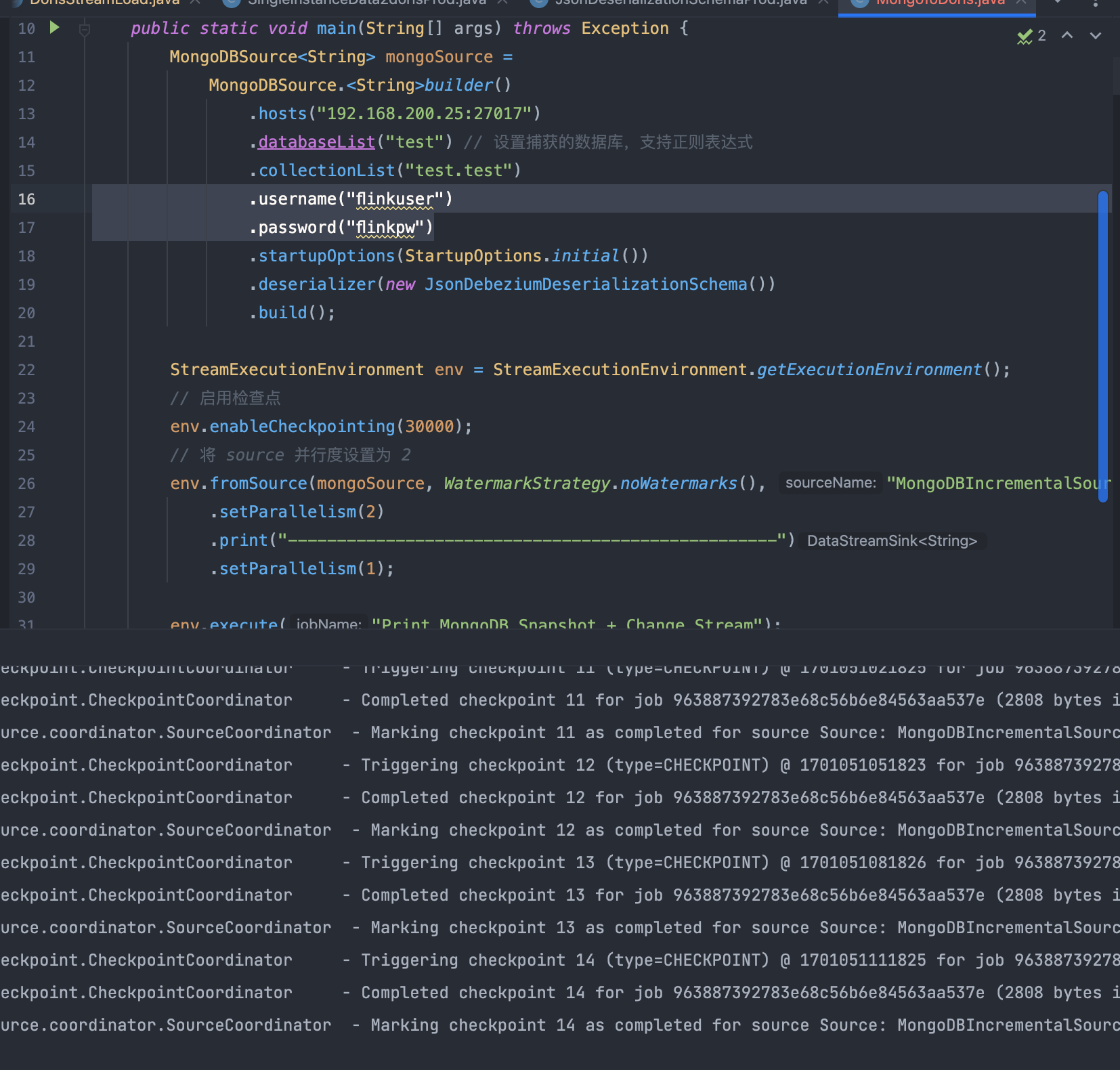
参考回答:
对于Flink CDC无法读取MongoDB数据的问题,可能的原因和解决方案如下:
- 检查Flink CDC配置中的相关参数,例如
cdc.source.poll-interval(轮询间隔)和cdc.source.max-pending-splits(最大待处理分片数)。如果这些参数设置不合适,可能会影响数据的读取。您可以尝试适当调整这些参数进行优化。 - 考虑增加Flink CDC作业的并行度,以便更好地利用计算资源。
- 确保服务器上的环境和依赖项与本地环境相同,包括Flink版本、MongoDB Connector for Flink版本等。检查日志文件,查看是否有任何错误或异常信息。
- 检查MongoDB的性能和资源利用情况,确保MongoDB能够提供足够的读取速度。
- 如果问题依旧存在,您可以考虑使用MongoDB CDC连接器。这是一个Flink Source连接器,支持从MongoDB读取快照数据和增量数据。它支持多种启动模式,并且即使在作业任何阶段失败都能保证Exactly-once语义。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574896
问题二:使用flinkcdc的oracle连接器消费数据,历史数据可以正常拿到,不知道怎么解决?
使用flinkcdc的oracle连接器消费数据,历史数据可以正常拿到,但是过一会程序就会报错挂掉了。不知道怎么解决,已经卡这块一段时间了。版本信息:oracle:11g,cdc:2.1.1。报错信息如下? 
参考回答:
这个问题可能是由于LogMiner无法找到完整的字典导致的。Oracle提供了一个名为DBMS_LOGMNR_D.BUILD_FLASHBACK_DICT的过程来构建缺失的字典。你可以尝试在执行sys.dbms_logmnr.start_logmnr之前调用这个过程。
以下是修改后的SQL代码示例:
BEGIN DBMS_LOGMNR_D.BUILD_FLASHBACK_DICT; sys.dbms_logmnr.start_logmnr(startScn => *1996903', endScn => *2013137', OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + DBMS_LOGMNR.DDL_DICT_TRACKING + DBMS_LOGMNR.CONTINUOUS_MINE + DBMS_LOGMNR.NO_ROWID_IN_STMT); END;
请注意,这个方法可能需要一些时间,因为它需要重新构建字典。另外,确保你的Oracle实例有足够的内存和CPU资源来执行这个过程。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574297
问题三:oracle11g 在 flinkCDC2.4 下使用flinkSql来进行同步,增量没有问题吗?
oracle11g 在 flinkCDC2.4 下使用flinkSql来进行同步,增量没有问题吗?会在全量结束后,确认 checkpoint 的时候卡住,表现出来就是只能全量不能增量,但是用 datastream 编写没有问题。Snapshot split assigner received all splits finished, waiting for a complete checkpoint to mark the assigner finished.
参考回答:
在 Flink CDC 2.4 中,使用 Flink SQL 进行同步时,增量同步可能会出现问题。如果在全量同步结束后,确认 checkpoint 时卡住,只能进行全量同步而不能进行增量同步,这可能是由于 Snapshot split assigner 接收到所有拆分完成并等待一个完整的检查点来标记分配器完成导致的。
为了解决这个问题,你可以尝试以下方法:
- 增加检查点的超时时间。在 Flink 配置文件(flink-conf.yaml)中,设置
taskmanager.network.memory.min和taskmanager.network.memory.max参数,以便为检查点分配更多的内存。例如:
taskmanager.network.memory.min: 64mb taskmanager.network.memory.max: 256mb
- 调整 Flink SQL 的并行度。在 Flink SQL 查询中,可以通过设置
parallelism.default参数来调整并行度。例如:
SET parallelism.default = 8;
- 如果问题仍然存在,可以考虑升级 Flink CDC 版本。确保你使用的是最新版本的 Flink CDC,因为它可能已经修复了这个问题。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574296
问题四:Flink CDC同步MySQL分库分表500张表报连接超时,方便帮忙看一下吗?
Flink CDC同步MySQL分库分表500张表报连接超时,方便帮忙看一下吗?这个库别的分表是没有问题的,就这个分库分表? 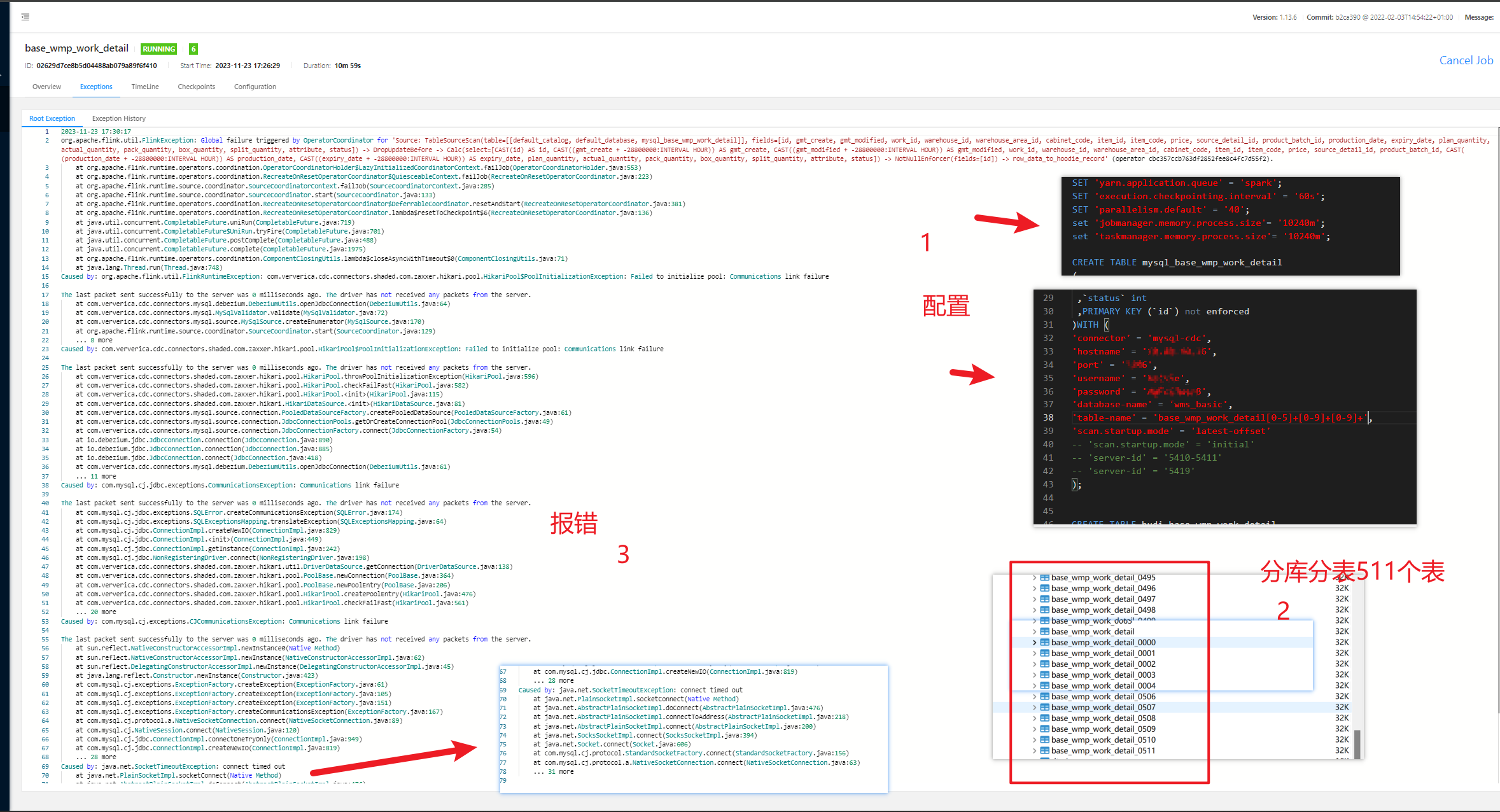

参考回答:
从你提供的错误信息来看,这是一个通信问题。这可能是因为网络连接问题或者MySQL服务器的问题。以下是一些可能的解决方案:
- 检查MySQL服务器的网络连接和状态。如果可能的话,尝试从其他机器连接到MySQL服务器,看看是否能成功。
- 检查MySQL服务器的日志,看看是否有任何相关的错误信息。
- 在Flink的配置中,增加连接MySQL服务器超时的时间。在
application.properties文件中,将execution.timeout.ms的值增加到一个较大的数值,比如30000(30秒)。 - 如果可能的话,尝试重启MySQL服务器。
- 更新MySQL驱动到最新版本。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/574294
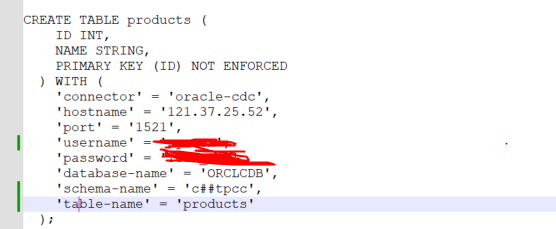
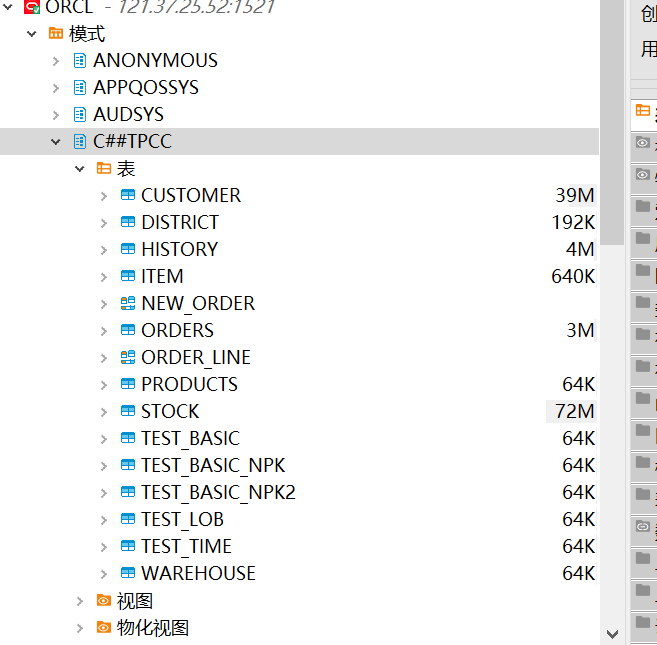
问题五:Flink CDC报这个是表不存在吗 但是我的表都在呀?
Flink CDC报这个是表不存在吗 但是我的表都在呀? 
参考回答:
根据你提供的错误信息,Flink CDC在尝试更新表时遇到了问题,错误信息中提到了"table or view does not exist"。这可能意味着表或视图在尝试更新时不存在。
然而,你提到你的表都在,这可能意味着错误信息中的表或视图可能是一个误报,或者是在错误的时间点尝试更新的。你可以检查你的表或视图是否存在,以及在错误发生时它们是否存在。
关于本问题的更多回答可点击原文查看:
