问题一:Flink这个问题怎么解决?
Flink这个问题怎么解决? The main method caused an error: maxConcurrentCheckpoints can't be > 1 if UnalignedCheckpoints enabled
参考回答:
要解决这个问题,您需要将maxConcurrentCheckpoints的值设置为1。在Flink的配置文件(如flink-conf.yaml)中,找到taskmanager.checkpointing.max-concurrent-checkpoints设置项,并将其值更改为1。例如:
taskmanager.checkpointing.max-concurrent-checkpoints: 1
然后重新启动Flink集群以使更改生效。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/576590
问题二:用FlinkSQL向DataHub中另一个topic写数据写不进去也不报错,知道什么原因吗?
用FlinkSQL从Datahub中的一个topic读数据没有问题,但是向DataHub中另一个topic写数据写不进去也不报错,知道什么原因吗?
参考回答:
可能的原因有以下几点:
- 检查目标topic是否存在,如果不存在,需要先创建topic。
- 检查FlinkSQL的写入配置是否正确,例如目标topic的名称、分区数等。
- 检查数据格式是否与目标topic的要求一致,例如序列化方式、schema等。
- 查看Flink集群的资源使用情况,如CPU、内存、网络等,确保有足够的资源支持数据的写入。
- 查看Flink日志,看是否有报错信息或者异常堆栈,以便进一步定位问题。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/576375
问题三:Flink这个错误怎么处理?
Flink这个错误怎么处理?2023-11-30 11:20:48
java.lang.UnsupportedOperationException: Currently it is not supported to update the CommittableSummary for a checkpoint coming from the same subtask. Please check the status of FLINK-25920
参考回答:
这个错误是由于Flink不支持在同一个子任务中更新来自相同检查点的CommittableSummary。要解决这个问题,你可以尝试以下方法:
- 确保你的Flink版本是最新的,因为这个问题可能已经在新版本中得到解决。
- 检查你的代码,确保在更新CommittableSummary时没有使用相同的子任务ID。如果有多个子任务同时更新同一个检查点,可能会导致这个错误。
- 如果问题仍然存在,你可以考虑在Flink的GitHub仓库中提交一个issue,详细描述你遇到的问题和复现步骤,以便开发人员能够更好地了解并解决这个问题。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/576354
问题四:Flink写入阿里云的selectdb,导入selectdb连接器报错,怎么处理?
Flink写入阿里云的selectdb,导入selectdb连接器报错,怎么处理? 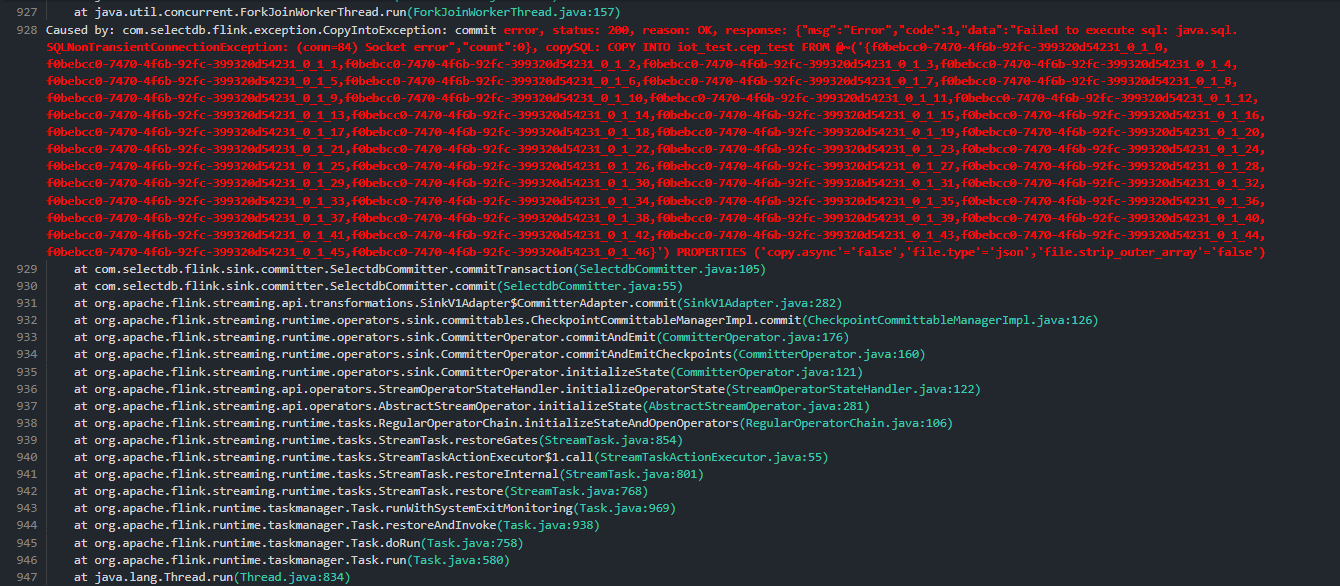
用的flinksql从阿里云kafka导入到阿里云selectdb
参考回答:
要解决Flink写入阿里云的SelectDB时,导入SelectDB连接器报错的问题,可以尝试以下方法:
- 检查依赖是否正确添加。确保在项目的pom.xml文件中添加了阿里云的SelectDB连接器依赖:
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-connector-selectdb</artifactId> <version>0.1.0</version> </dependency>
- 检查连接配置是否正确。在Flink的配置文件(如flink-conf.yaml)中,添加以下配置信息:
# 阿里云SelectDB连接器配置 table.sql.catalog: selectdb table.sql.defaultDatabase: your_database_name table.sql.username: your_username table.sql.password: your_password table.sql.endpoint: your_endpoint
将your_database_name、your_username、your_password和your_endpoint替换为实际的数据库名称、用户名、密码和端点。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/576353
问题五:Flink因为session集群无法启动,提示要剔除参数。剔除后调试的时候又报错,这应该怎么处理啊?
Flink因为session集群无法启动,提示要剔除参数。剔除后session集群能启动了,但是调试的时候又报错,这应该怎么处理啊? 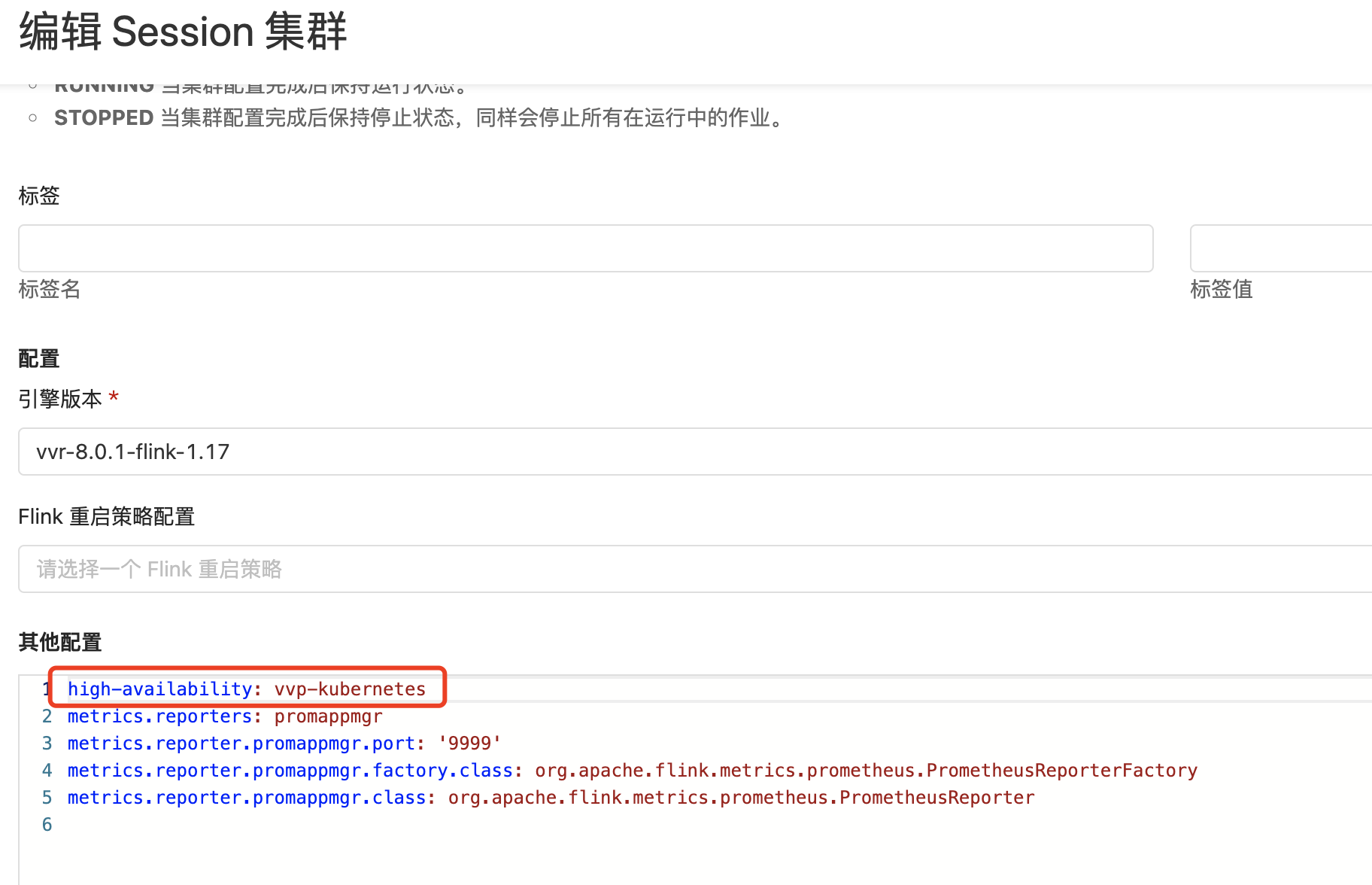

参考回答:
这个问题可能是由于Flink的参数设置不正确导致的。你可以尝试以下步骤来解决这个问题:
- 检查你的Flink配置文件(flink-conf.yaml),确保所有的参数都设置正确。特别是关于session集群的相关参数,如jobmanager.rpc.address、taskmanager.numberOfTaskSlots等。
- 如果参数设置没有问题,那么可能是你的Flink版本和你的代码不兼容。你可以尝试升级或降级你的Flink版本,看看是否能解决问题。
- 如果以上步骤都不能解决问题,那么你可能需要查看更详细的错误日志,找出具体的错误原因。你可以在启动Flink时添加-verbose和-debug参数,以获取更详细的日志信息。
关于本问题的更多回答可点击原文查看:

