问题一:flink任务 调整内存和cpu分配之后启动报错?
flink任务 调整内存和cpu分配之后启动报错?Failed to rollback to checkpoint/savepoint Checkpoint Metadata. Max parallelism mismatch between checkpoint/savepoint state and new program. Cannot map operator 58212cb79e8186067bdc9ae3681ec630 with max parallelism 32768 to new program with max parallelism 1. This indicates that the program has been changed in a non-compatible way after the checkpoint
参考回答:
这个错误提示表明在调整内存和CPU分配后,Flink任务启动时出现了问题。具体来说,它指出了检查点/保存点状态与新程序之间的最大并行度不匹配。这意味着在检查点之后,程序发生了非兼容的更改。
要解决这个问题,你可以尝试以下几个步骤:
- 检查你的Flink代码,确保你没有在检查点之后对程序进行了任何不兼容的更改。这可能包括添加或删除操作符、修改操作符的属性等。
- 确保你在调整内存和CPU分配时正确地更新了Flink配置文件(如
flink-conf.yaml)。特别是,确保你设置了正确的taskmanager.numberOfTaskSlots参数,以匹配你的CPU和内存分配。 - 重新启动Flink任务,并确保在启动时使用相同的配置。这样可以确保Flink能够正确地加载检查点和保存点,并与新的程序进行匹配。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577066
问题二:请教一个Flink问题,基于springboot2.6.0构建的flink项目,该怎么解决呢?
请教一个Flink问题,基于springboot2.6.0构建的flink项目,提交到flink环境报如下图所示错误,该怎么解决呢? 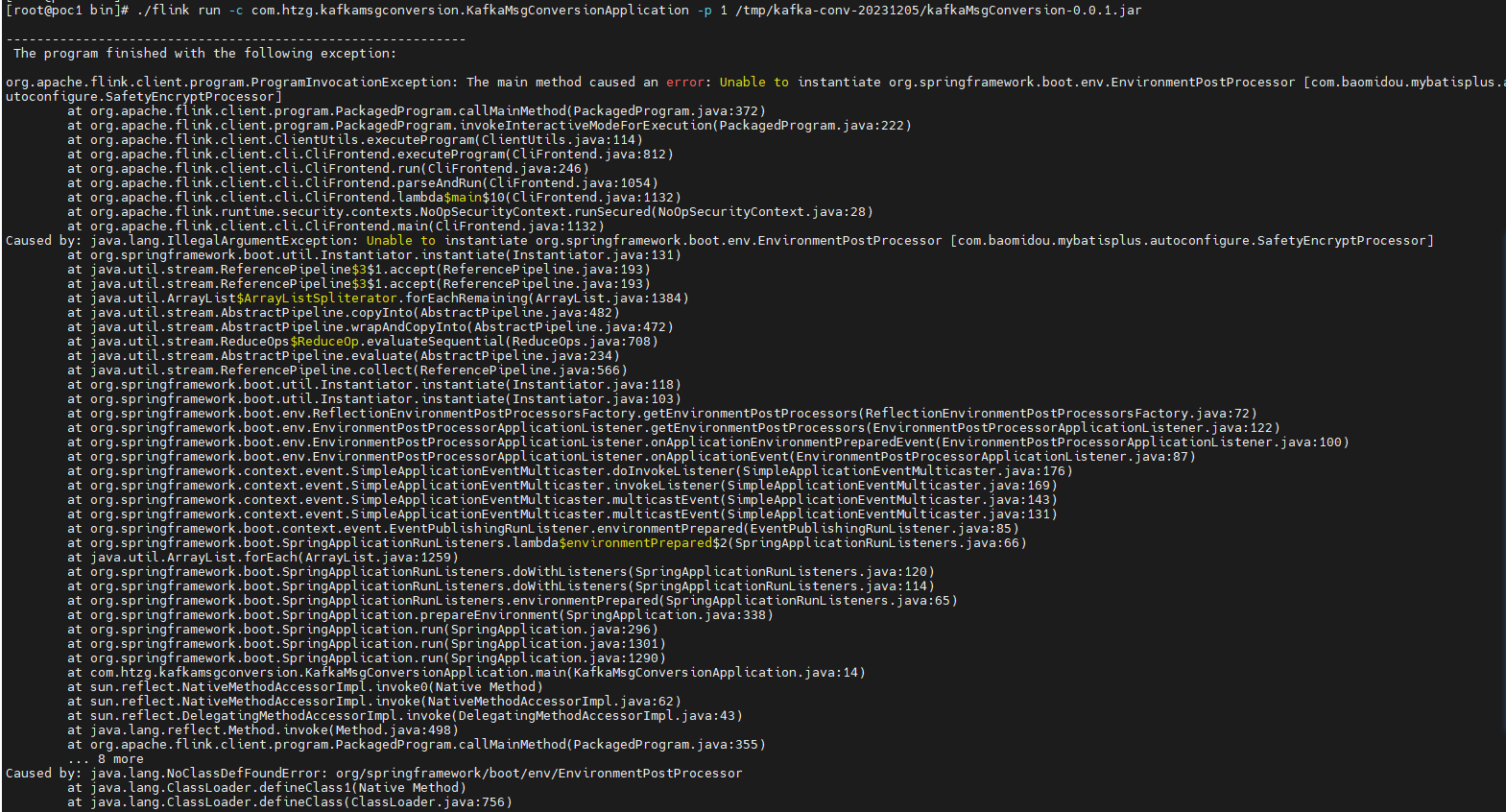
参考回答:
根据你提供的错误信息,看起来像是Spring Boot应用程序中的类找不到异常。这种错误通常发生在你的应用程序试图加载某个类,但是该类没有被正确地添加到类路径中。
要解决这个问题,你可以尝试以下几个步骤:
- 确保你在项目的pom.xml文件中正确地配置了依赖项。特别是,你需要确保你正在使用的是正确的Spring Boot版本(例如,如果你正在使用Spring Boot 2.6.0,那么你应该使用对应的Spring版本,如Spring Framework 5.3.x)。
- 在你的代码中,确保你正确地导入了所有必要的类。例如,如果你在代码中使用了
org.springframework.boot.env.EnvironmentPostProcessorApplicationListener,那么你需要确保你已经导入了org.springframework.boot包下的所有类。 - 如果你仍然遇到问题,你可以在你的代码中添加更多的日志语句来调试。这样可以帮助你确定哪个类或者方法引发了这个异常。
- 最后,如果以上步骤都无法解决问题,你可能需要考虑更新你的Spring Boot版本或者重新创建一个新的项目来测试你的代码。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577064
问题三:Flink之前任务少mysql数据可以正常抽到doris ,任务超过20几就一直会报超时问题?
Flink之前任务少mysql数据可以正常抽到doris ,任务超过20几就一直会报超时问题 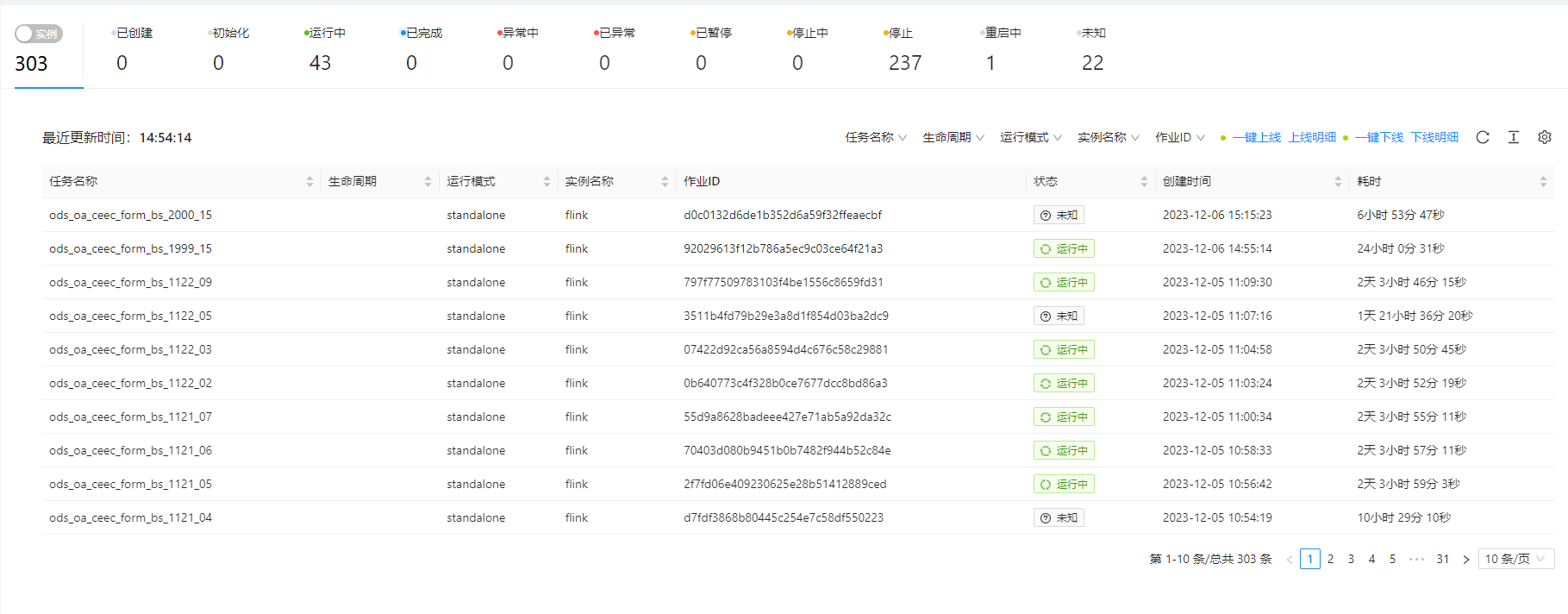
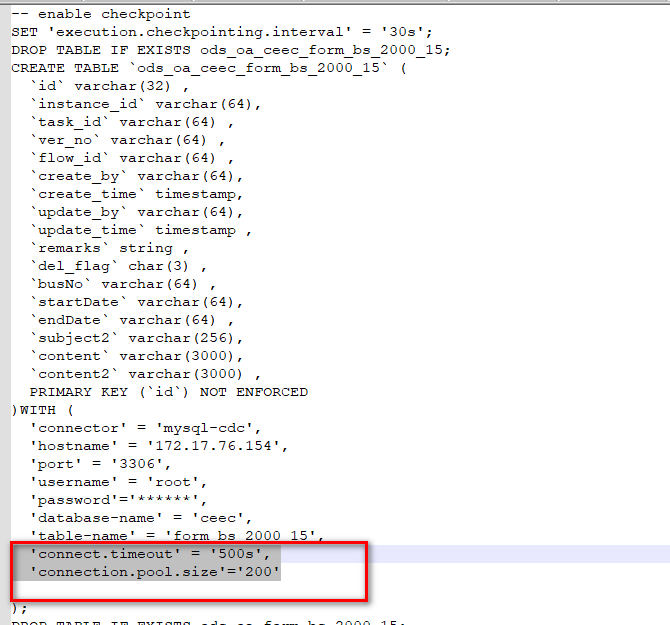
设置flinkcdc两个参数,也不行
参考回答:
您好,这个问题可能是由于Flink任务在处理大量数据时出现了超时问题。这可能是由于以下原因导致的:
- 网络延迟问题:由于网络质量不稳定或者任务管理器与资源管理器之间的连接发生故障,导致心跳消息无法及时到达,从而引发心跳超时问题。
- 资源不足问题:Flink任务管理器需要充足的内存和CPU资源来运行任务,如果资源不足,则可能导致任务运行缓慢或者失败,从而引起心跳超时问题。
- 任务调度问题:Flink任务管理器负责接收和执行任务,如果任务调度出现问题,比如任务堆积、任务依赖关系错误等,就会导致心跳超时问题的发生。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577062
问题四:flink cdc跑多个MySQL到doris任务,报错数据库连接超时,还有其他什么地方需要配置?
flink cdc跑多个MySQL到doris任务,报错数据库连接超时,查看连接的数据库连接数及超时时间正常,请教大佬们还有其他什么地方需要配置? 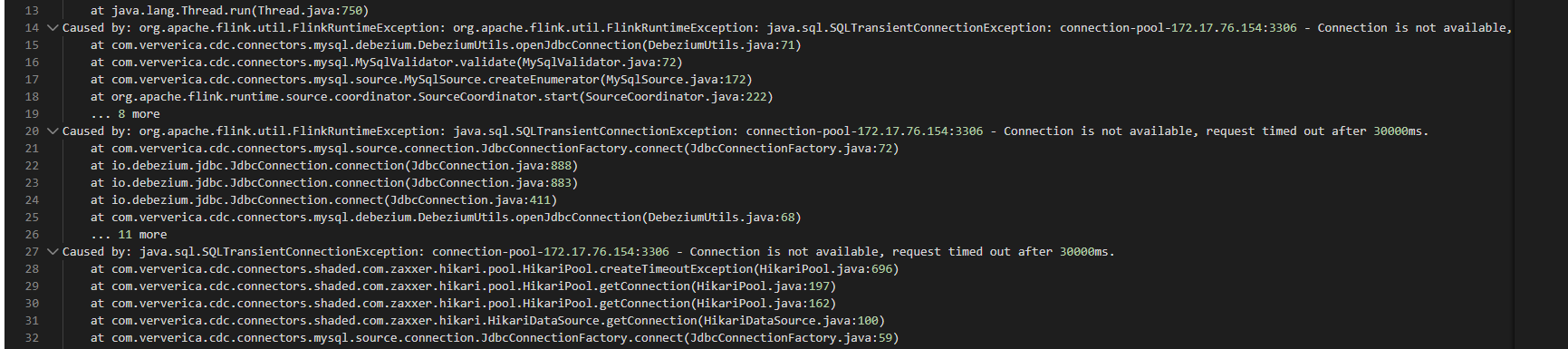
参考回答:
您好,针对Flink CDC在将多个MySQL同步到Doris时出现数据库连接超时的问题,您可以考虑以下方面的配置和优化:
- Flink参数调优:您可以增加Flink的
taskmanager.memory.off-heap参数值,以便分配更多的堆外内存给任务,从而避免因内存不足而导致的任务失败。此外,适当增加taskmanager.numberOfTaskSlots参数值可以提高任务的并发度,但请注意不要设置过高的值,以免引发其他问题。 - 网络连接优化:确保作业所在的集群网络状况良好,避免因网络延迟或丢包等问题导致的任务执行失败。您可以尝试通过增加Flink与MySQL、Doris之间的网络带宽来改善数据传输效率。
- MySQL Binlog配置:Flink CDC通过订阅MySQL的binlog来实现数据同步,因此确保MySQL的binlog功能正常启用是很重要的。您可以检查MySQL的配置文件(如
my.cnf),确认log-bin和binlog_format等参数的配置是否正确,并重启MySQL服务使配置生效。 - Doris Flink Connector配置:确保您使用的Doris Flink Connector版本与您的Flink版本兼容,并且已正确配置相关参数。检查Doris端的参数设置,例如FE节点数、BE节点数以及列簇设计等,以确保它们能够适应您的数据量和查询负载。
- 任务并行度和资源分配:根据您的作业需求和数据量大小,合理设置Flink任务的并行度以及每个任务的资源分配。过高的并行度可能导致资源竞争和任务失败,而过少的并行度可能限制了作业的处理能力。
- 日志和监控:仔细查看Flink作业的日志输出,特别是报错信息,以获取更多关于连接超时的线索。同时,利用Flink提供的监控工具来监控系统的性能指标,如任务运行状态、CPU利用率、内存使用情况等,有助于定位问题所在。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577060
问题五:flink+hologres实时数仓 宽表merge问题
双流数据有些没有merge上,不确定是否是回撤原因引起,在建结果表的时候不能设置ignoredelete属性,出现”The provided value for option ignoredelete is true, which is not as same as the value false inferred by catalog. You can use the inferred value by removing the specified option from the DDL”
后面就换成创建临时表,设置该属性,但是还是出现没有merge的流,双流都建了同样的主键
参考回答:
Flink 和 Hologres 结合构建实时数仓时,如果在宽表合并(merge)过程中遇到双流数据没有完全 merge 的问题,可能是由于多种原因导致的。以下是一些可能的原因和相应的解决方案:
- 事件时间不一致:
- 确保两个流中的事件时间戳是准确且一致的。使用 Flink 的 Watermark 机制来处理乱序事件。
- 主键冲突:
- 检查是否有多个流具有相同的主键值。如果有,考虑使用其他方法来区分不同的记录,如添加额外的唯一标识符或修改主键策略。
- 回撤数据处理:
- 如果你的系统支持回撤数据,确保你已经正确地处理了这些数据。可以尝试在 Flink 中启用
sideOutputLateData或者在 Hologres 中设置合适的 TTL 来处理过期数据。
- 并发控制:
- 在写入 Hologres 时,确保并发控制设置正确。你可以尝试降低并行度或者增加 Hologres 表的分区数量来提高写入性能。
- 检查点一致性:
- 确保 Flink 的检查点间隔和保留时间足够大,以避免丢失数据。
- 临时表与结果表的问题:
- 如果你在创建临时表时设置了 ignoredelete 属性,但在将数据写入结果表时未设置,可能会导致数据丢失。尝试将临时表的数据合并到结果表中,并确保在合并期间保持忽略删除属性。
- 网络延迟和连接问题:
- 检查 Flink 与 Hologres 之间的网络连接是否稳定,以及是否存在任何网络延迟或超时问题。
- Hologres 版本兼容性:
- 确保使用的 Hologres 版本与 Flink 集成插件兼容。如果不兼容,可能会导致数据无法正确写入。
关于本问题的更多回答可点击原文查看:
