问题一:Flink CDC跑个一晚上第二天看就会报错什么原因?
Flink CDC就还是这个整库同步的时候出现的server-id的问题我在flink的配置文件跟dinky的作业里面都配置了server-id 然后跑个一晚上第二天看就会报错? 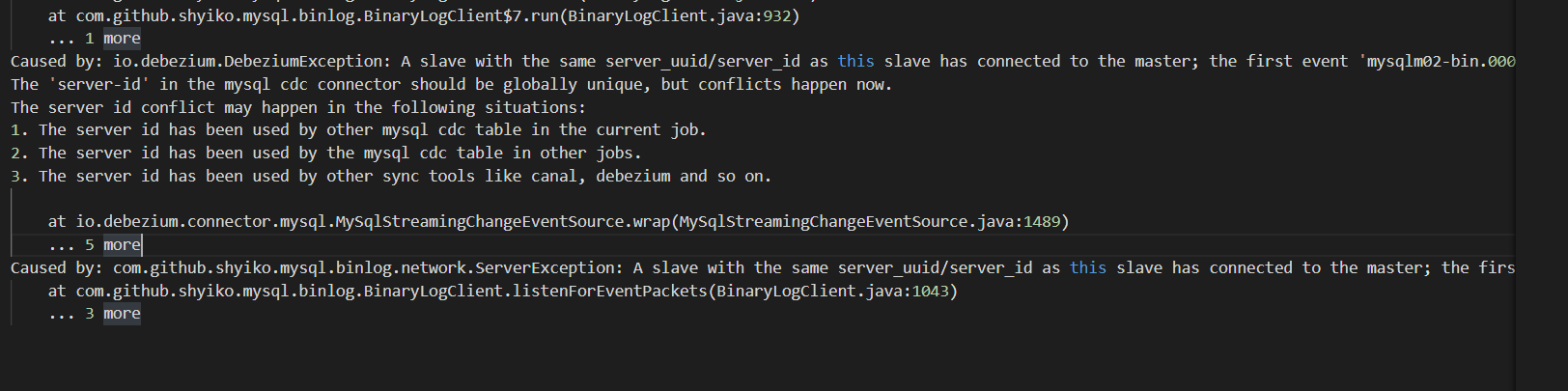
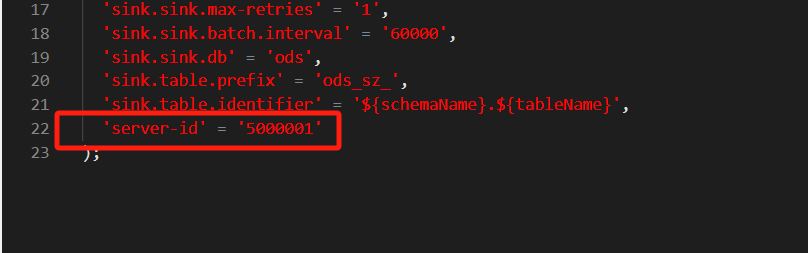
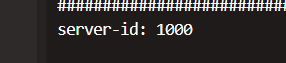
参考回答:
冲突了,有的历史任务没清,建议5400-6400之间取三个,如果5400-5402一个并行度一个server id就会这样
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/580002
问题二:Flink CDC这是传输blob文件太大导致的吗?
Flink CDC这是传输blob文件太大导致的吗?2023-12-09 04:33:29,302 ERROR org.apache.flink.runtime.blob.BlobServerConnection [] - Error while executing BLOB connection.
java.io.IOException: Unknown operation 80
参考回答:
这个错误信息表明在执行BLOB连接时出现了问题。具体来说,它指出了一个未知的操作代码80。这可能是由于传输的blob文件太大导致的。
要解决这个问题,你可以尝试以下几种方法:
- 增加Flink CDC的内存限制:如果blob文件过大,可能会导致内存不足。你可以尝试增加Flink CDC的内存限制,以便能够处理更大的blob文件。
- 优化数据存储和传输方式:如果可能的话,你可以考虑优化数据的存储和传输方式,以减少blob文件的大小。例如,你可以使用压缩算法来减小文件大小,或者将大文件分割成多个小文件进行传输。
- 调整Flink CDC的配置参数:你还可以尝试调整Flink CDC的配置参数,以适应更大的blob文件。例如,你可以增加
taskmanager.network.memory.min和taskmanager.network.memory.max的值,以便为网络传输提供更多的内存空间。 - 检查网络连接和防火墙设置:如果问题仍然存在,可能是由于网络连接或防火墙设置导致的问题。你可以检查网络连接是否正常,以及防火墙是否允许Flink CDC与数据库之间的通信。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/579985
问题三:Flink CDC有人遇见这个问题吗?
Flink CDC有人遇见这个问题吗?导致原因:org.apache.flink.table.api.ValidationException:MySQL服务器的时区偏移量(比UTC晚18000秒)与配置的亚洲/上海时区不匹配。指定正确的服务器时区,以避免与时间相关的字段不一致。Caused by: org.apache.flink.table.api.ValidationException: The MySQL server has a timezone offset (18000 seconds behind UTC) which does not match the configured timezone Asia/Shanghai. Specify the right server-time-zone to avoid inconsistencies for time-related fields.我添加了'server-time-zone' = 'Asia/Shanghai',还是没用
参考回答:
这个问题是由于MySQL服务器的时区偏移量与配置的亚洲/上海时区不匹配导致的。要解决这个问题,你需要确保MySQL服务器的时区设置正确。你可以尝试以下方法:
- 登录到MySQL服务器,执行以下命令查看当前时区设置:
SELECT @@global.time_zone, @@session.time_zone;
- 如果发现时区设置不正确,可以使用以下命令进行修改(以将时区设置为'+08:00'为例):
SET GLOBAL time_zone = '+08:00'; SET SESSION time_zone = '+08:00';
- 重启MySQL服务器使更改生效。
- 确保在Flink CDC的配置中指定正确的时区。例如,如果你使用的是Debezium连接器,可以在
connector.properties文件中添加以下配置:
debezium.database.hostname=your_mysql_host debezium.database.port=your_mysql_port debezium.database.user=your_mysql_user debezium.database.password=your_mysql_password debezium.database.server.time-zone=Asia/Shanghai
- 重新启动Flink CDC任务,问题应该已经解决。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/579973
问题四:Flink CDC这种问题怎么解决?
Flink CDC这种问题怎么解决? 
参考回答:
换个server-id
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/579963
问题五:flinkcdc同步oracle19c报上面的错?
flinkcdc同步oracle19c报上面的错?Caused by: java.sql.SQLException: ORA-44609: CONTINOUS_MINE is desupported for use with DBMS_LOGMNR.START_LOGMNR.
ORA-06512: at "SYS.DBMS_LOGMNR", line 72
参考回答:
这个错误是由于Oracle 19c不支持DBMS_LOGMNR.START_LOGMNR的CONTINOUS_MINE参数导致的。你可以尝试使用DBMS_LOGMNR.START_TIMING_TRANSACTION来替代DBMS_LOGMNR.START_LOGMNR。
在Flink CDC中,你需要修改源表的DDL语句,将CONTINOUS_MINE替换为DBMS_LOGMNR.START_TIMING_TRANSACTION。具体操作如下:
- 首先,找到你的源表的DDL语句,它可能类似于以下格式:
CREATE TABLE your_table ( ... ) WITH ( CONTINUOUS_MINE = 'ON', ... );
- 然后,将CONTINUOUS_MINE替换为DBMS_LOGMNR.START_TIMING_TRANSACTION,并删除其他不需要的参数,例如CONTINUOUS_MINE = 'ON'。修改后的DDL语句应该类似于以下格式:
CREATE TABLE your_table ( ... ) WITH ( DBMS_LOGMNR.START_TIMING_TRANSACTION, ... );
- 最后,重新运行Flink CDC作业,看看是否还会出现相同的错误。
关于本问题的更多回答可点击原文查看:
