问题一:Flink CDC我在配置文件分配了三个G 没提交任务是只占用了100m 现在已经增长到1.7G?
Flink CDC我在配置文件分配了三个G 没提交任务是只占用了100m 全量阶段跑完后占用1.6G 然后就一直不动了。现在已经增长到1.7G? 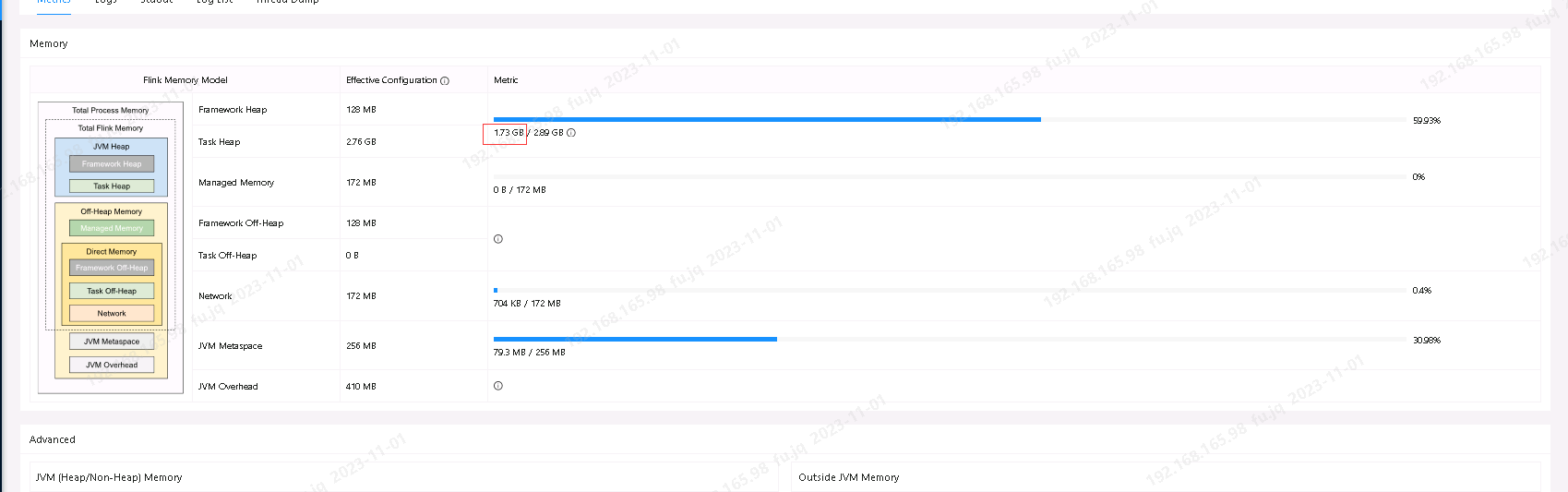
参考回答:
这可能是因为Flink CDC的内存使用不仅仅是取决于你配置的内存大小,还与你的数据量和复杂性有关。
一般来说,全量阶段会消耗较多的内存,因为它需要处理所有的数据。而在增量阶段,内存使用通常会比较稳定,因为只需要处理新的或者更改过的数据。
如果你发现内存使用一直在增加,那么可能是由于以下原因:
- 数据流持续不断地输入新的数据,而且这些数据非常大或者复杂,导致内存使用不断增加。
- Flink CDC任务出现了一些问题,例如数据倾斜、垃圾回收频繁等,这也可能导致内存使用增加。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/567532
问题二:Flink CDC全量同步时数据分片速度快吗,为什么我分片速度很慢,而且是越来越慢?
Flink CDC全量同步时数据分片速度快吗,为什么我分片速度很慢,而且是越来越慢?
参考回答:
Flink CDC在进行全量数据同步时,需要先读取所有的数据然后再写入到目标端,以此来保证数据的一致性和顺序。这一过程可能会消耗大量的时间和资源,导致数据同步速度较慢。此外,Flink CDC初始全量速度慢的另一原因是它使用了Debezium作为捕获数据变化的引擎,Debezium在读取数据时,会使用全局锁或者快照隔离级别,这样可能会对源端数据库的性能和并发能力产生影响。
为了优化全量数据同步的速度,你可以采用并行读取的方式,将源端数据库的表分成多个分区,然后使用多个任务同时读取不同的分区,这样可以显著提高读取速度和吞吐量。Flink CDC也支持并发读取,可以通过增加处理节点数来加快数据处理速度。此外,Flink CDC还实现了断点续传功能,如果同步任务在运行过程中出现失败,不需要重跑整个任务,可以从上次停止的地方继续执行,这也能在一定程度上提高数据同步的效率。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/567531
问题三:使用flinkcdc 2.4.1从时间戳启动的时候,我想输出前三天的数据,有最近七天的?
使用flinkcdc 2.4.1从时间戳启动的时候,我想输出前三天的数据,但是实际数据只有最近一天半的数据,查看数据库Binlog文件,都是全的,有最近七天的?
参考回答:
如果在 Flink CDC 2.4.1 中从时间戳启动,并且想要输出三天的数据,但实际上只有最近一天半的数据,则可能是由于 Flink CDC 的初始化时间戳设置不合理导致的。可以按照以下步骤进行排查:
- 检查初始时间戳设置:请确认您的时间戳是否正确设置,一般情况下 Flink CDC 初始化时间戳是指定了一个 SCN 或者时间段。如果是的话,请确认该时间戳的时间范围。
- 检查 Oracle 的日志信息:如果您设置了 SCN,则请查看 Oracle 数据库中的 scn 时间戳,确认其是否符合预期。
- 查看 binlog 文件中的数据:可以查看 binlog 文件的内容,看看是否有完整的历史数据。如果 binlog 文件中的数据不足,请检查 binlog 文件大小限制。
- 其他情况:检查其他可能导致数据缺失的因素,如权限问题、连接问题等。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/567530
问题四:Flink CDC实际保留的这个task的backpressure是0这是不是有点问题?
Flink CDC设置了.closeIdleReaders(true)后,增加新表启动,其他几个task finished,但是dag图上的busy一直是100,实际保留的这个task的backpressure是0这是不是有点问题? 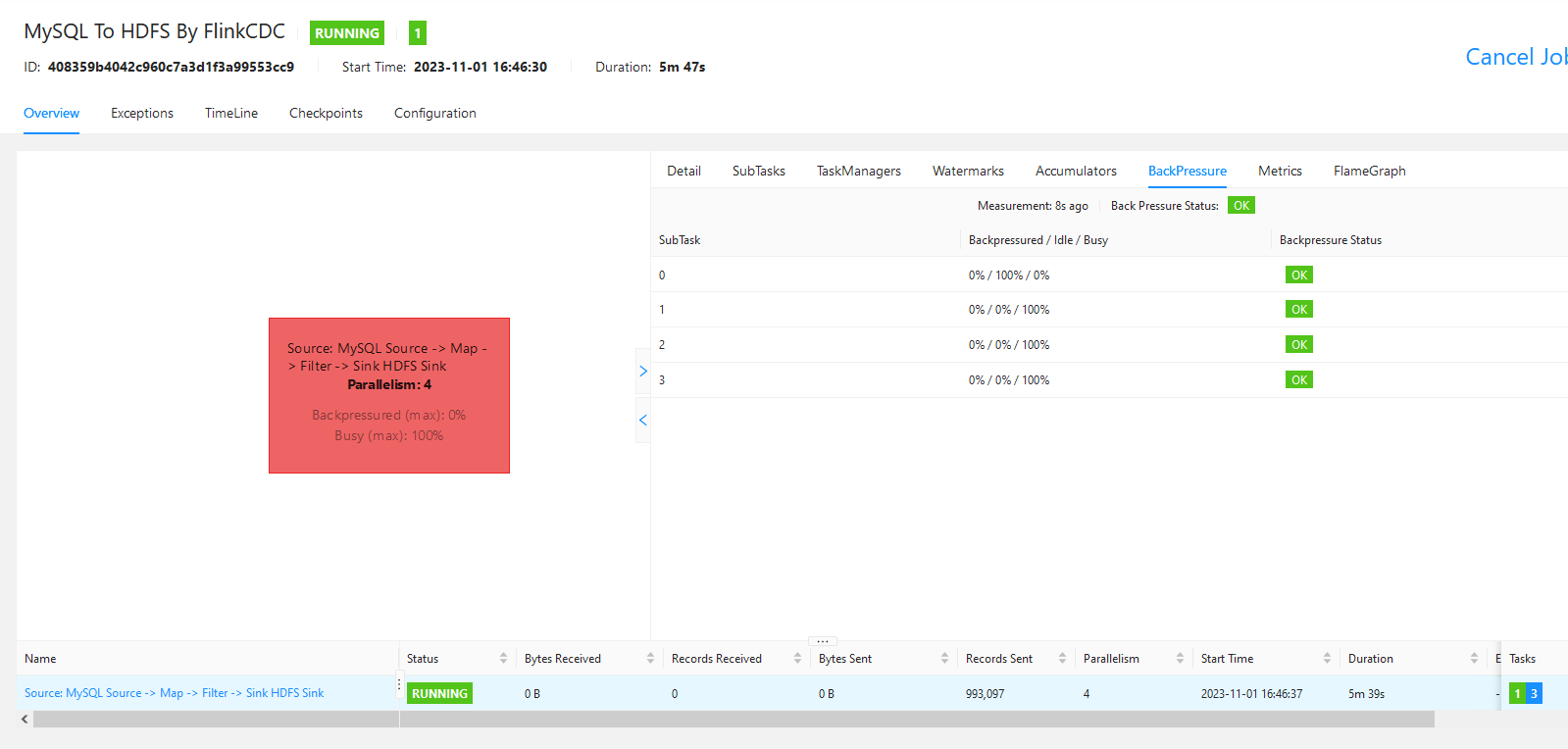
参考回答:
这可能是由于以下原因引起的:
- 在设置
closeIdleReaders(true)之后,Flink CDC会在检测到reader闲置一段时间后将其关闭。这可能会导致一些延迟,特别是在刚开始增加新表的时候,因为Flink需要先创建一个新的reader来读取新的表,然后再关闭原来的reader。所以在这个过程中,其他的task可能已经完成了工作,而新的task还在等待reader创建完成,这就可能导致DAG图上显示的busy仍然是1000,但实际上新task的backpressure是0。 - 另外,如果你的任务是并行运行的,那么即使所有的子任务都已经完成,DAG图上仍然可能会显示有一个或多个任务处于busy状态。这是因为Flink需要等到所有并行任务都完成后才会结束整个任务。因此,即使有些子任务已经完成了工作,但只要还有一个子任务仍在仍在进行,DAG图就会显示有一个任务处于busy状态。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/567529
问题五:flinkcdc从时间戳启动,为啥只能读取最近的两个binlog日志文件吗?还是有其他规律吗?
flinkcdc从时间戳启动,为啥只能读取最近的两个binlog日志文件吗?还是有其他规律吗?时间戳有啥要求吗?
参考回答:
Flink CDC 只能读取从某个时间点以后的 binlog 日志文件。也就是说,如果设置了一个时间戳,则只能读取此时间戳以后的所有 binlog 日志文件。
对于 binlog 日志文件的要求,请参阅 Oracle 数据库的官方文档和开发指南,以了解详细的要求和规定。需要注意的是,binlog 文件有格式要求,例如 binlog 格式和编码等,因此务必按照规范来创建 binlog 文件。
此外,需要注意的是,由于 Flink CDC 依赖于 binlog 文件的创建日期,因此务必确保 binlog 文件创建日期与实际日期相符。如果 binlog 文件日期不正确,则会导致读取失败。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/567528
