问题一:Flink CDC2.4.1 flink1.14.6,sql left join一些表,这个咋解决?
Flink CDC2.4.1 flink1.14.6,sql left join一些表,非主键关键,会丢失delete同步,这个咋解决?
参考回答:
如果您使用的是Flink CDC v2.4.1和Flint 1.14.6,可能是因为缺少合适的配置或者连接器导致删除事件无法及时捕获。
针对这种问题,您可以在Flink SQL语句中加入WITH (key='id')关键字,以指定Join的主键字段,如:
SELECT * FROM sourceTable AS src LEFT JOIN targetTable AS tgt ON src.id = tgt.id WITH (key='id')
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570213
问题二:Flink CDC这个问题大家遇到过吗 请问怎么解决?
Flink CDC这个问题大家遇到过吗 请问怎么解决? 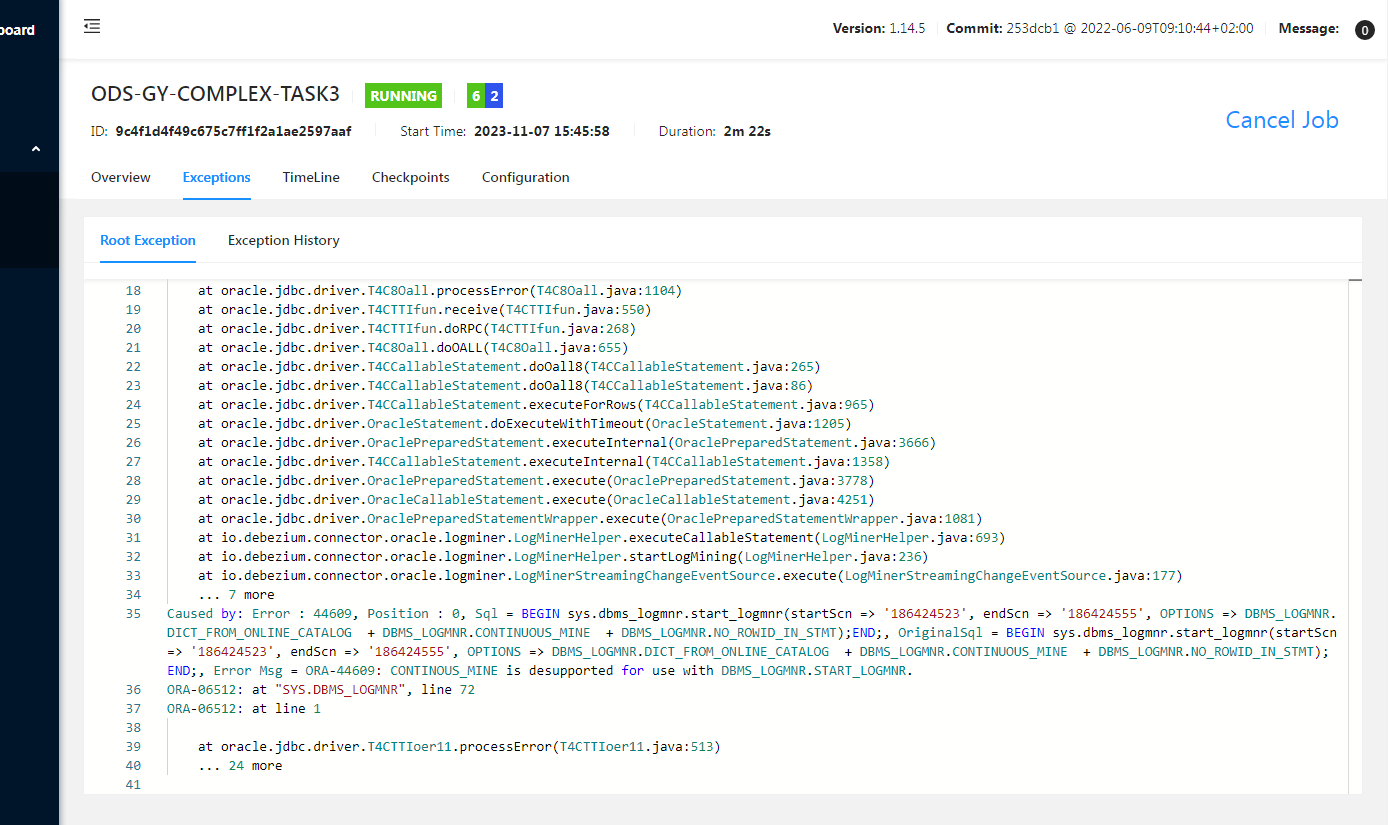
flinkcdc2.2.1 抽取oracle19c环境,'debezium.log.mining.strategy' = 'online_catalog',
'debezium.log.mining.continuous.mine' = 'true' 网上好像说是因为这个参数的问题,但是不设置这个参数的话 日志增长速度会非常快
参考回答:
Flink CDC 是一个用于捕获数据库变更的框架,它可以从多种数据库中抽取数据。在您的情况下,您正在使用 Flink CDC 2.2.1 版本来抽取 Oracle 19c 环境的数据。
关于您遇到的问题,debezium.log.mining.strategy 参数设置为 online_catalog 是必要的,因为它告诉 Flink CDC 使用在线目录模式进行日志挖掘。这意味着 Flink CDC 会实时监控数据库的变化,并在检测到变化时立即开始抽取数据。
然而,您提到不设置这个参数会导致日志增长速度非常快。这可能是由于以下原因:
- 数据库中的更改速度非常快,导致日志增长速度过快。
- Flink CDC 的配置可能没有正确设置,导致它无法有效地处理日志。
为了解决这个问题,您可以尝试以下方法:
- 检查数据库中的更改速度,确保它们不会对 Flink CDC 造成太大的影响。
- 调整 Flink CDC 的配置,例如增加缓冲区大小或调整心跳间隔,以确保它能够更有效地处理日志。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570212
问题三:Flink CDC环境 只能拿到全量数据,没法拿到增量数据,还有可能是什么原因?
Flink CDC环境
maven依赖:flink-connector-db2-cdc 2.3.0
db2:docker安装 11.5.0.0
使用DataStream Source方式连接db2,只能拿到全量数据,没法拿到增量数据,还有可能是什么原因
env.enableCheckpointing() 已设置过?env.enableCheckpointing(3000);
参考回答:
有个SQL可以检测你的asncdc有没有正常开启的... 我之前的时候是按照db2 test 里得 dockerfile文件构建出来的, 是可以成功的.
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570211
问题四:Flink CDC中 oracle19应该用哪个版本的cdc 包呀?
Flink CDC中 oracle19应该用哪个版本的cdc 包呀?本地环境1.13.6的 hadoop 2.8
参考回答:
对于Oracle 19c环境,推荐使用Flink CDC 2.3.0版本。该版本的Flink CDC对Oracle的数据进行了实时采集,底层使用的是debezium框架来实现,debezium使用oracle自带的logminer技术来实现。需要注意的是,logminer的采集需要对数据库和采集表添加补充日志。此外,如果在全量阶段发生数据更新,建议使用rowid来避免增量同步问题。请确保在设置过程中遵循最佳实践,以确保最佳的同步效果。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570210
问题五:Flink CDC有测试过mysql-cdc的吞吐率么? 单线程每秒大概能获取多少的mysql数据?
Flink CDC有测试过mysql-cdc的吞吐率么? 单线程每秒大概能获取多少的mysql数据?主要就是看增加薄荷额吞吐量吧
参考回答:
只测过单表同步,1c2g全量大概5000/秒,增量的话测的不严谨,大概也得有个两三千,甚至还测出过两三万。总体性能还是不错的
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570209
